
はじめに
皆さんはじめまして、サイバーエージェントのアメーバピグというサービスでエンジニアをやっています赤野です。私はアメーバピグのコアシステムというチームに所属しており、サービスの監視やJenkinsの管理、ミドルウェアのバージョンアップや新ツールの導入などをやっています、最近はデータセンターの移設のお手伝いをさせてもらっていました。今回は私が以前ピグのストレージサーバをAmazon S3へ移行させた時につまづいたこと、困ったことを中心に書こうと思います。S3に移行させたのは去年の11月頃なので、情報としては少し古かったり、ピグ特有の問題であったりしますが最後まで読んで頂けるとうれしいです。
移行前のストレージサーバの構成
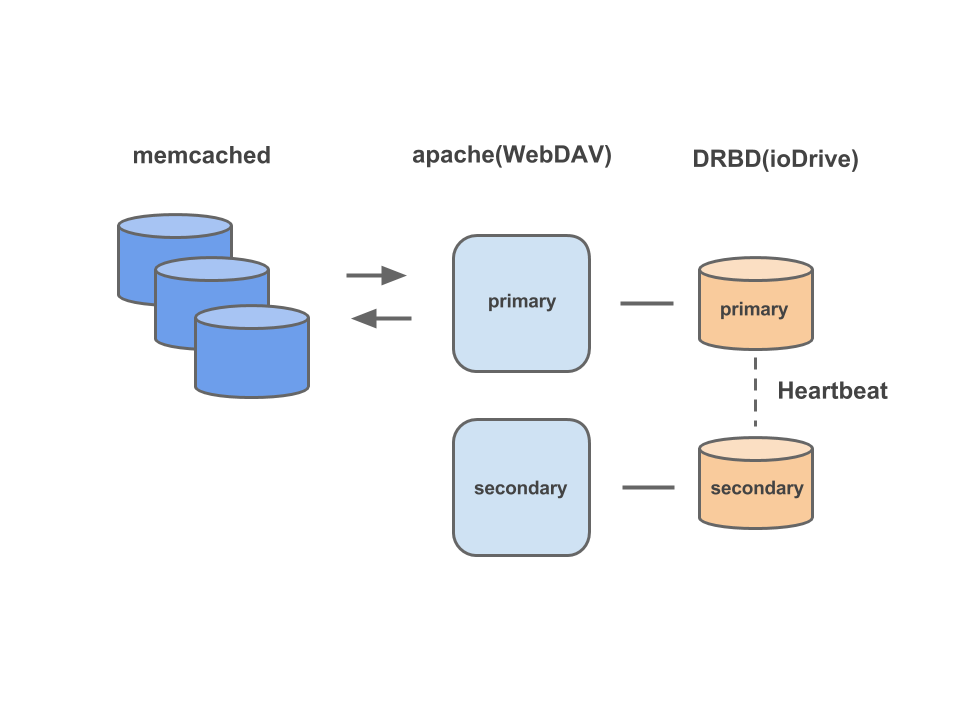
移行前にピグで使用していたストレージサーバの構成は、ioDriveのディスクがマウントされた物理サーバにApacheをWebDAVサーバとして起動し、Heatbeatの死活監視でprimaryに問題があれば自動的にsecondaryが昇格してくれる構成になっていました。DRBDとHeartbeatについて詳しい人が限られていたこと、このストレージサーバを構築した当時のメンバーがチームから離れてしまっていたこともあって、運用コストの筆頭として上げられていた部分でした。また、DRBDの構成が物理サーバに依存してしまうため、前々から移行したいという話をチームでしていた部分でもありました。
ストレージサーバをS3に移行することになったきっかけ
ストレージサーバを移行することを決めたのは、2016年4月1日にピグで起きた障害がきっかけになっています。この日、ピグのユーザ画像が全て裸になってしまう障害が発生しました。さらに、ピグではきせかえアイテムを全て脱いでもパンツだけは脱ぐことが出来ないのですが、この時のユーザ画像はパンツすら履いていない状態になっており、事象を確認した時はかなり混乱しました…発生日がエイプリールフールであったこともあり、ユーザの方々もかなり混乱されている状態でした。調査をした結果、ストレージサーバからユーザ画像を生成するための素材画像が消失していることが分かり、バックアップから素材画像をコピーすることで復旧することは出来たのですが、ストレージサーバから素材画像が消失してしまった原因の特定をすることは出来ませんでした。さらに、この時Heartbeatによるsecondaryの昇格が発動せず、手作業での昇格を実施したため復旧するまでにも時間がかかってしまいました。この障害をきっかけに、このままの構成で運用していくのはリスクが高いと判断し、ストレージサーバの移行へ本格的に動き出すことになりました。
S3へ移行後の構成
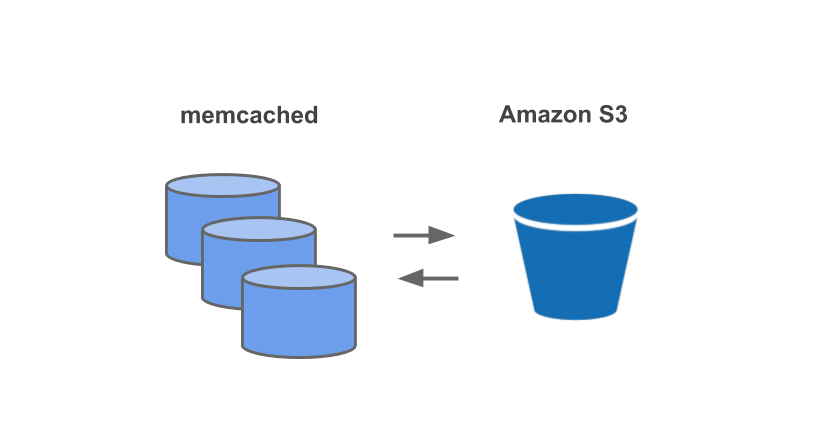
ApacheのWebDAVサーバーとDRBDを使用していた部分をS3に置き換えた構成になります
S3への移行でつまずいたこと、困ったこと
S3への移行作業は大きく分けてこれらでした
- Amazon S3にバケットを準備
- Amazon S3に旧ストレージサーバのデータをコピー
- アプリからストレージにアクセスしている部分の改修
具体的な作業手順については特に変わったことはしていないので、S3へ移行するまでの間にあった困ったことを中心に紹介しようと思います。
ストレージサーバへのリクエスト多すぎ問題
S3への移行前に旧ストレージサーバへのアクセスログを集計して、想定されるS3へのアクセス数を算出しました。下記は当時出した想定される最大のアクセス数です。
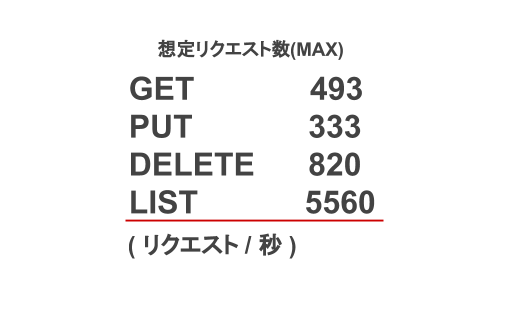
私も算出してみて驚いたのですが、かなりの数のLISTのリクエストが発行されていました。旧ストレージサーバは物理サーバでディスクにはioDriveを使用して構築されていたため、全てのリクエストを一瞬で処理してしまうほどハイパフォーマンスだったので何とかなっていたのですが、S3への移行で確実にパフォーマンスは低下してしまうので、この状態のまま移行するのは厳しいと判断しました。
対応
調査したところ、LISTのリクエストはmemcachedにキャッシュしないような作りになっていたので、LISTのリクエストもmemcachedでキャッシュするようにアプリの実装を改修して対応しました。対応後のLISTリクエストのキャッシュHIT率は予想以上に高く、改修後のストレージサーバへのリクエスト数は驚くほど下がりました。

S3にはフォルダという概念が無い問題
hoge/fuga/piyo.pngというファイルパスがあったとして、S3ではhoge/とhoge/fuga/は階層構造を扱うためのフォルダではなく、hoge/fuga/piyo.pngというKeyに対してpiyo.pngというValueがあるという扱いになります。
これが理由で、アプリからS3を操作する実装をする際に少し困ったことがありました。
ピグはJavaで実装されており、ストレージ関係の操作を実装するためのインターフェースが用意されています。
public interface Storage {
boolean mkdir(String key) throws IOException;
OutputStream save(String key) throws IOException;
InputStream load(String key) throws IOException;
boolean exists(String key) throws IOException;
ItemInfo getInfo(String key) throws IOException;
ItemInfo[] listInfo(String key) throws IOException;
void delete(String key) throws IOException;
}
ストレージインターフェースの例このインターフェースを使って「WebDAVStorage」や「LocalStorage」などの実装クラスを作成することで、データの参照元を簡単に切り替えられるような作りになっていたので、S3用の実装もこのインターフェースを使用して実装することにしました。実装自体はAWS SDK for Java の AmazonS3Clientを使用して、ストレージインターフェースの各メソッドに対応するAPIを呼び出すようにして実装を進めていたのですが、AmazonS3Clientには「フォルダを作成するAPI」と「フォルダの存在を確認するAPI」が無かったので少し困りました。
対応
フォルダの作成は作成したいフォルダ名をKeyにして空のデータをPUTすることで作成することが出来ました。
String key = “hoge/”;
ByteArrayInputStream emptyContent = new ByteArrayInputStream(new byte[0]);
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentLength(0);
PutObjectRequest putObjectRequest
= new PutObjectRequest(bucket, key, emptyContent, metadata);
amazonS3Client.putObject(putObjectRequest);
フォルダ作成の例この時、Key名はスラッシュで終わるようにする必要があります。
フォルダの存在確認はAmazonS3ClientのdoesObjectExistでは実現できなかったので、一階層上のKeyに対してAmazonS3ClientのlistObjectsを実行した結果の中に確認したいフォルダのKeyが存在するかをチェックするようにして実装しました。
ListObjectsRequest listRequest = new ListObjectsRequest()
.withBucketName(bucketName)
.withDelimiter(delimiter)
.withPrefix(parentKey);
ObjectListing objects;
do {
objects = amazonS3.listObjects(listRequest);
boolean exist = objects.getCommonPrefixes().stream()
.anyMatch(existFolderKey -> existFolderKey.equals(targetKey));
if (exist) return true;
listRequest.setMarker(objects.getNextMarker());
} while (objects.isTruncated());
return false;
フォルダ存在確認の例パフォーマンスの問題
Javaの実装が完了したタイミングで実装したJavaのクライアントを通してパフォーマンスの測定を行いました。その結果、更新系の処理のパフォーマンスが思っていたよりも遅かったため困りました。
JMeterの実行結果CSVデータをローカルMacにたてたElasticsearchとKibanaで可視化するを参考にしてKibanaでパフォーマンス測定結果をすぐに見れるようにしていたのですが、とても便利でした。
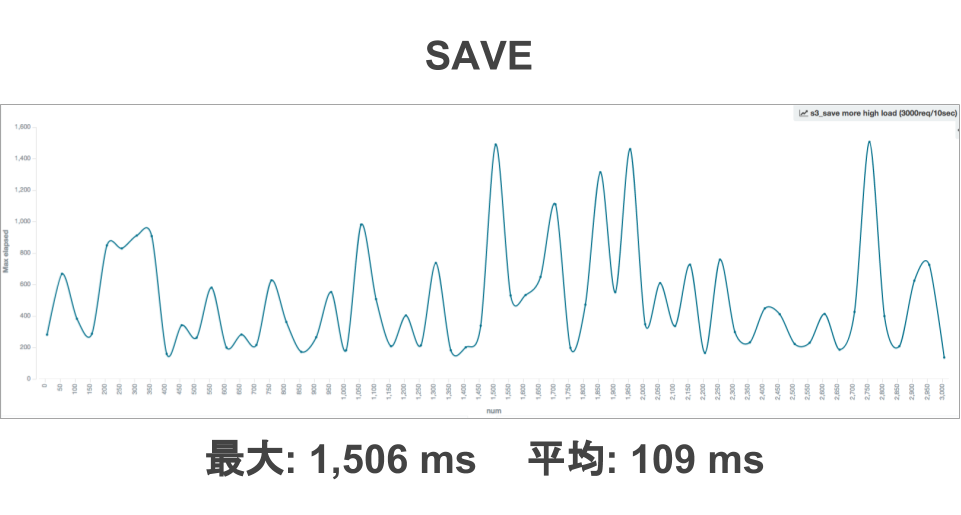
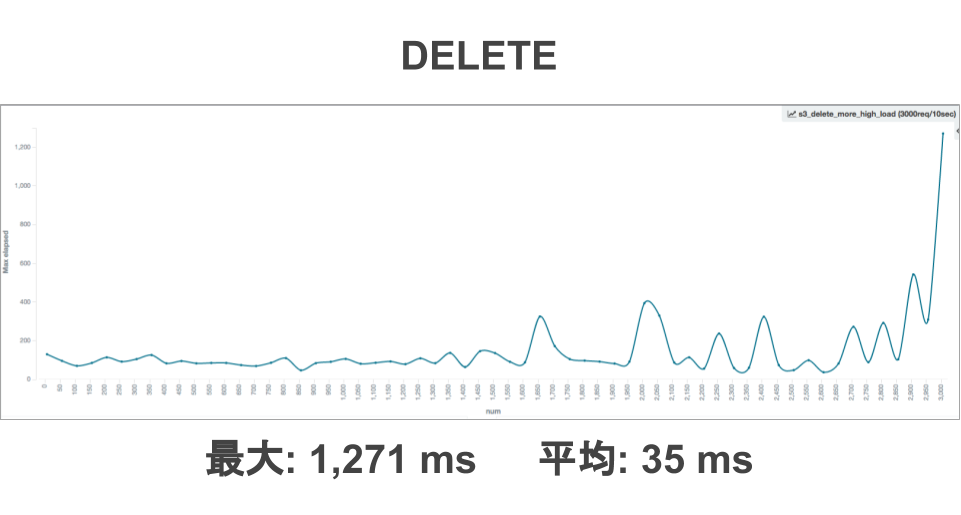
上記は2016年8月頃に測定した時の結果です。実装したJavaのクライアントを通しているのでピグ特有の処理も入っているため、純粋なS3のパフォーマンスではありません。
気になったのは、レスポンスタイムに波があることと遅い時で1秒を超える場合がある点でした。これは、移行当時のピグが物理サーバで稼働しており、インターネットを通してS3にアクセスしていることの影響が大きいと思います。ピグでストレージへの更新処理が実行されるのはアバターの着せ替えが実行されるタイミングなのですが、そのタイミングでストレージに対して複数回のSAVEとDELETEのリクエストが実行されていたため、着せ替えの処理時間への影響が大きいと判断して、対応することにしました。
対応
対応方法は下記の3つを検討しました
- 更新するオブジェクトのKeyを分散させる
- S3 Transfer Accelerationを使う
- S3への更新を非同期に行う
検討した結果、3つ目のS3への更新を非同期にする対応を行いました。具体的にはJavaの実装で非同期に処理するメソッドをストレージインターフェースに追加して、非同期にS3のデータを更新する処理を実装しました。非同期のSAVE処理はAWS SDK for Java の TransferManagerで実現できましたが、非同期にDELETEするAPIは用意されていなかったので、DELETEは自前で実装しました。いまのところピグの仕様的に更新の順序を担保する必要がなかったため、順序を担保するような設計にはなっていません。この対応を選択した理由は対応コストが低く、効果も大きかったからです。
更新するオブジェクトのKeyの分散を採用しなかった理由は下記です。
- ピグでは十分な改善効果が得られなかった
- 大規模なKey名の変更がしづらくなる
- オブジェクトのライフサクル管理など、Keyの共通プレフィックスを指定して使用する機能が使いづらくなる
- LISTのリクエストが使いづらくなる
S3 Transfer Accelerationは費用コストが大きくなるため今回は使用しませんでした。
さいごに
S3への移行に少し手こずることもありましたが、無事にS3への移行を終えることができました。いまのところ大きな問題もなく順調に稼働していますし、移行したことで費用コストも削減できました。最近、データセンターの移設があったのですが、その時にも移行しておいて良かったという実感を得ることが出来ました。個人的にも既存のシステムをパブリッククラウドに置き換える貴重な経験をすることが出来て楽しかったです。ピグにはまだ新しいシステムに置き換えることができそうな部分が残っているので、今後もこのような動きをしてしていこうと思います。