
サイバーエージェント技術本部インフラエンジニアの@prog893です。今回も「AWA」という音楽ストリーミングサービスのインフラの改善について紹介したいと思います。前回の記事では、データベースの復旧時間が12時間から55分まで短縮できた話を紹介しましたが、今回は楽曲ダウンロード及びストリーミングレイヤーでのエラー率を大幅に改善したことについて述べたいと思います。
楽曲ダウンロード及びストリーミングの構成
まず、楽曲ダウンロード及びストリーミングの構成概要について紹介します。
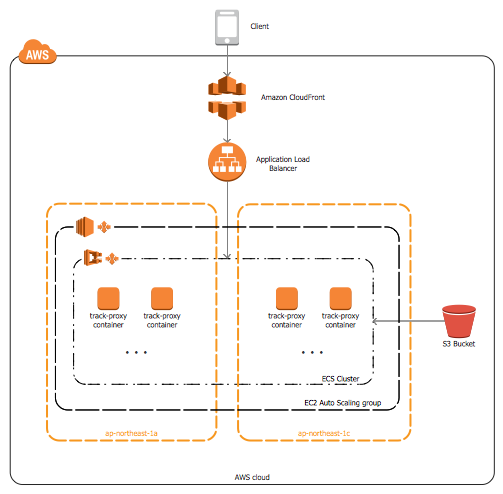
楽曲配信サーバ(以降Track Proxy)はコンテナとして実行しAWS Elastic Container Service(ECS)で運用しており、ECSのバックエンドとしてはEC2のAuto-Scaling Group(ASG)を使っています。また、ECSではApplication Auto-Scalingを使用することによって、負荷に応じてコンテナの増減を自動的に行っています。EC2 ASGは、稼働しているコンテナが使用しているリソースの変化に応じてスケーリングするようにしています。
ECS Serviceで起動されたコンテナが自動的にApplication Load Balancer(ALB)に紐付けられ、ALBからアクセスが可能になります。キャッシュのためにCloudFrontを使っており、CloudFrontがALBの前段にあります。ユーザからのリクエストがCloudFrontで受けられ、ALBに転送されます。ALBではリクエストが負荷分散され、コンテナに転送されます。
Track Proxyは、元々オフライン用楽曲ファイルの配信など限定された用途向けに作成したものでした。そのため、EC2 ASGの設定はありましたが、しきい値を超えることはなく、EC2 ASGのスケールイン、スケールアウトが発生することはありませんでした。しかし、しばらくサービスを運営し、よりよい音楽体験をへ提供するためのさまざまな改善を行っていく過程で、このサーバの役割も変化していき、リクエスト数が徐々に増加していきました。そして、日常的にEC2 ASGのスケールイン、スケールアウトが発生するようになっていきました。
エラー増加に気付いた瞬間:iOSクライアントのクラッシュ
11月頃、iOSクライアントのクラッシュが急増したとの連絡が入りました。
クラッシュ原因の特定及びiOSクライアントの修正はiOSチームに任せて、CloudFrontの調査をすることになりました。特定の時間帯にCloudFrontでは5xxのエラーが発生していることがわかり、iOSクライアントのクラッシュとグラフが一致しました。アプリレベルで5xxエラーがハンドリングできるようにiOSクライアントが修正され、エラー時のリトライを行うことである程度の回避ができました。ログの調査を行うべく、CloudFront、ALB、コンテナのアクセスログ出力を有効にし、データを収集することにしました。しかし、CloudFrontでの5xxエラーが落ち着いて、調査に使えそうなデータが集められなかったのです。
再発編
12月頃、CloudFrontでの5xxエラーがまた観測できました。時間帯が深夜、アクセスが最も少ない時間帯に定期的に起きるようになり、ここで初めてスケーリングを疑いました。
CloudWatchに格納されていたコンテナのログを確認しましたが、特にエラーが見つかりませんでした。EC2 ASGのスケールインが行われる際に非正常なコンテナが一瞬だけ発生していることが確認できました。この事象の出現タイミングとCloudFrontでの5xxエラーが跳ねるタイミングが一致しました。

CloudFrontのアクセスログから無作為にいくつかの5xxエラーが発生するイベントを選択し、ALBのログと突き合わせました。イベントが一致し、ALBまでリクエストが到達していることを確認できたので、根本問題はCloudFrontレイヤーではないと確信しました。次に、ALBのログをコンテナのログと突き合わせてみると、一致するイベントが見つかりませんでした。
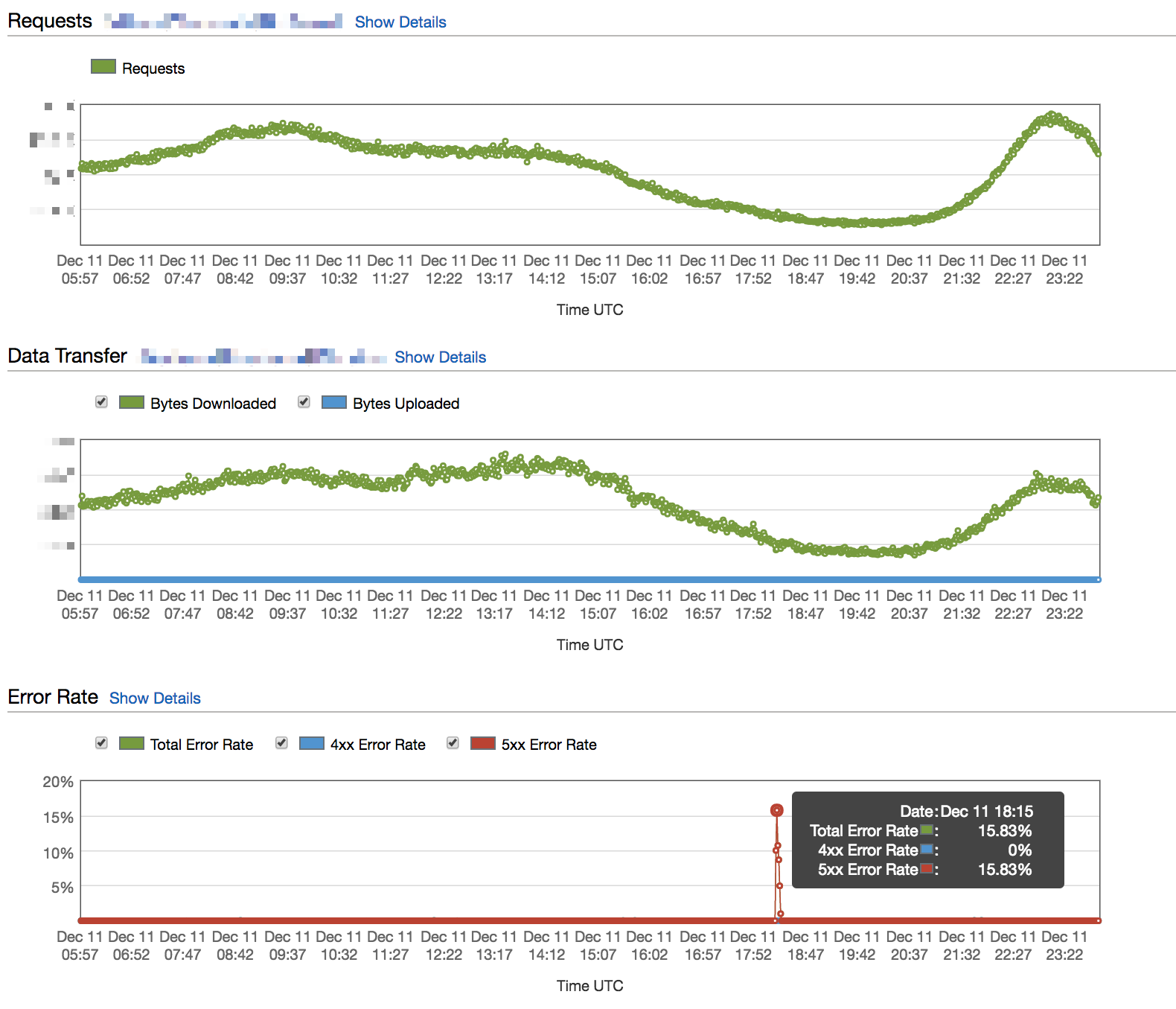
まず、CloudFrontのアクセスログを目grepし、同じリクエストが同じクライアントから連続的に複数回出現することがわかりました。また、CloudFrontでのエラー数とALBでのエラー数が一致しませんでした。
「CloudFrontはデフォルトだとエラーレスポンスを5分間キャッシュする。そのせいでリクエストがコンテナに到達しなかった際に、ALBの問題が解消しても5分間CloudFrontがエラーを返し続けるんだな」と考え、5xxエラーを全部、一旦TTL=0にしてみました。エラーキャッシュを無効したときの効果を下の図で示しました。
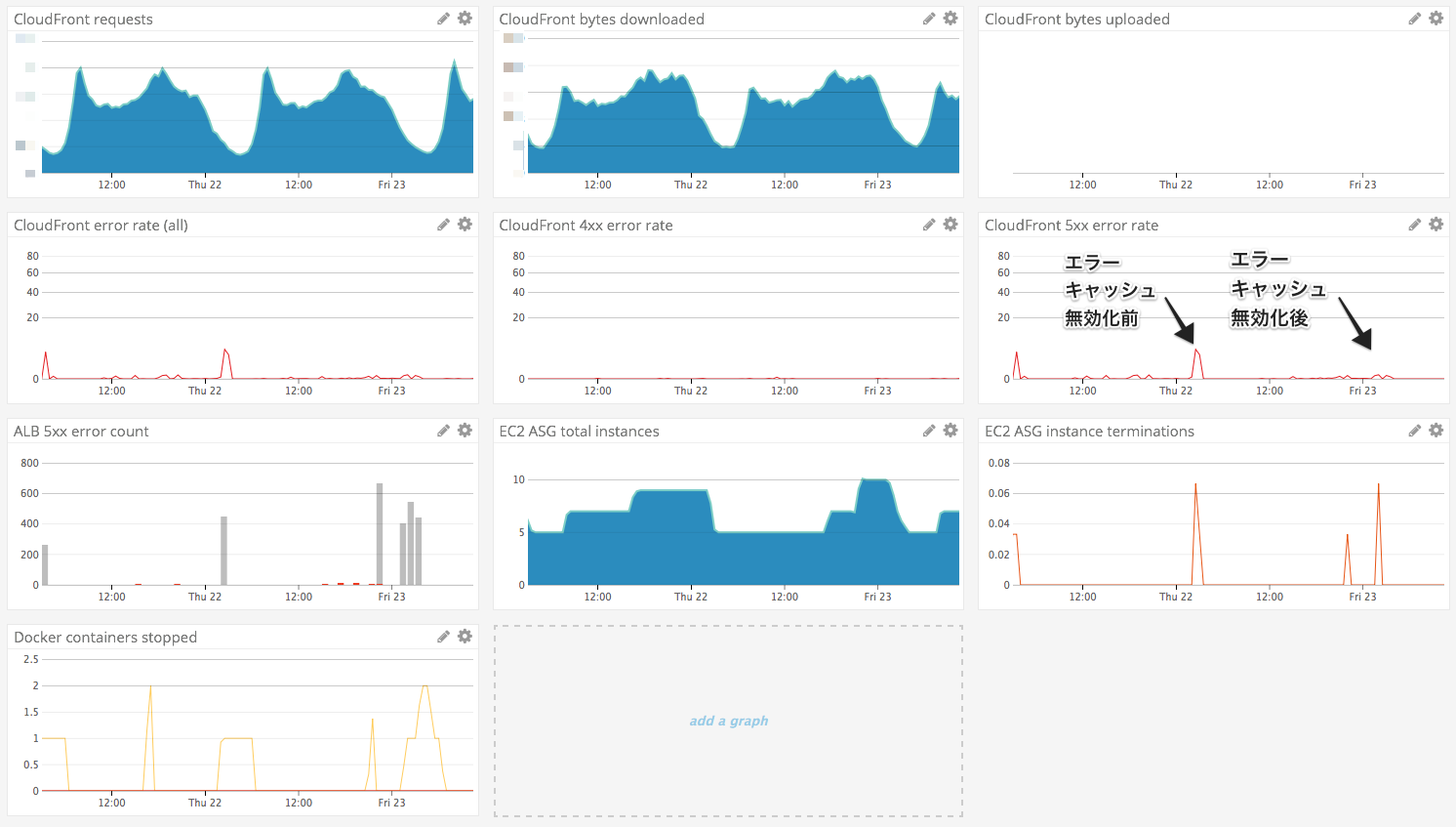
CloudFrontのエラー数を減らせたことによって、全体のエラー数を大幅に減らすことに成功できました。しかし、キャッシュを無効にしたため、ALBでの5xxエラーが増加しました。取りあえず緩和はこれで良いとし、根本解決に向けて調査を続行…
インスタンススケールインでコンテナが殺される編
ALBのログでは、リクエストをどのバックエンドに転送したか(具体的に、バックエンドのIPアドレスとポート)が記述されています。エラーとなっているイベントのIPを調べてみると、すべてがもう存在しないインスタンスを指していました。TerminateされたインスタンスのIDで過去のIPアドレスを確認することができませんが、CloudTrailのイベントログを用いることによって、エラーとなっているリクエストがもうその時点ではTerminateされていたインスタンスに転送されていたことがわかりました。
そこで、EC2 ASGのオートスケーリングとECS Serviceのオートスケーリングが別レイヤーだ、ということに気付きました。コンテナの増減とインスタンスの増減が独立して行われ、EC2 ASGスケールイン時に、インスタンスが停止されます。そして、そのインスタンスで起動していたコンテナが全部、ECSに報告することもなく、停止されます。システム終了時にDockerサービスが停止されるので普通にkillですね。絶対これだと確信したものの、対策どうしましょうとしばらく悩んでいました。
AWS公式ブログで紹介されている方法では、Terminateイベントのフックで、インスタンス停止前にコンテナを移動させることが可能です。しかし、コンテナの移動によるスケーリングの遅延や、インスタンスの停止が免れないのでこの方法は採用しませんでした。他にもっといい方法がないかと、しばらく探っていました。
お手製スクリプト編
そして探っていたら、そもそもコンテナが稼働しているインスタンスを殺させない、という方法に出会いました。具体的に、殺されては困るようなコンテナをdocker psコマンドで数え、0であればインスタンスのスケールイン保護を無効にする、1以上であれば有効にする、というストレートな解決方法です。該当クラスタでは、dd-agentという、Datadog Agentのコンテナと、ecs-agentというECS管理用が殺されても困ることはありません。この二つの種類以外のコンテナは殺されたら困るので、数える対象とします。
上記のようにスクリプトを実装し、その結果がこちらにあります。このスクリプトをEC2インスタンス起動時に取得し、定期実行されるようcrontabを設定させるようにuser dataを更新し、インスタンスのIAM Roleに適切な権限を追加し、導入してみました。その結果、まず、殺されて困るコンテナが起動しているインスタンスがスケールインから保護されるようになりました。下の図の通りです。
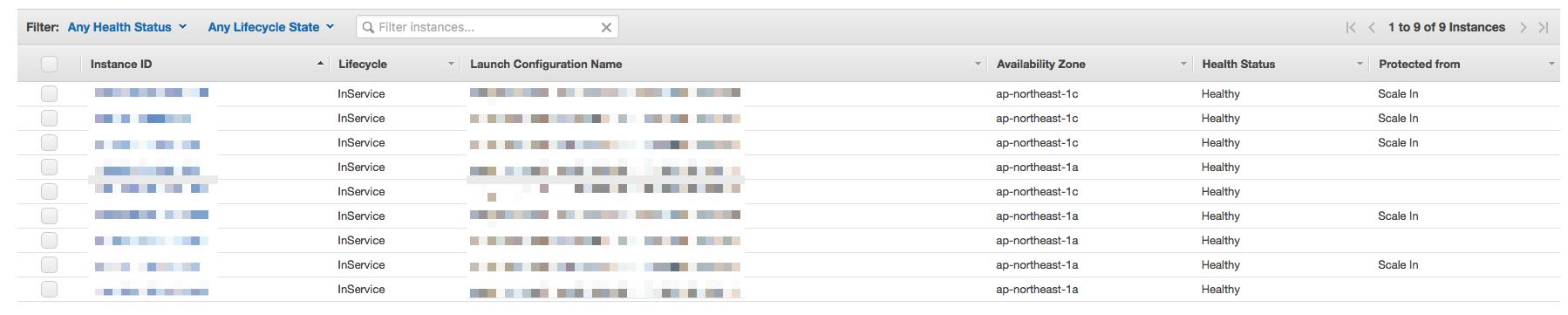
しばらくこの状態で稼働させて、CloudFront、ALBでのエラーを確認しました。
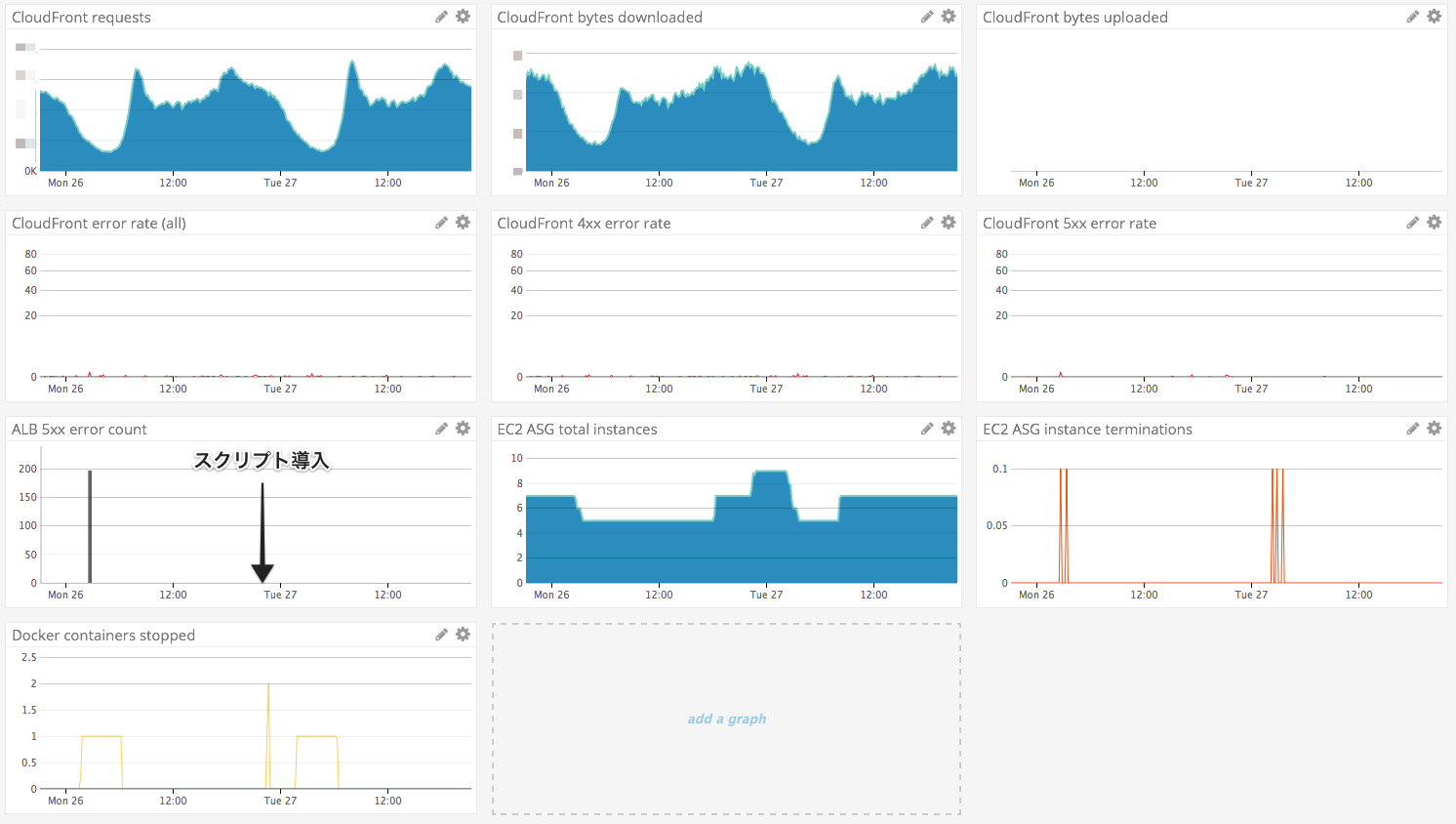
激減です。というか、エラーが0件になりました。オートスケーリングもいい感じです。これでやっと対応完了です。
コンテナ配置戦略がbinpackである方がこの方法では理想的ですが、配置戦略の指定がクラスタ作成時にしかできないため、ECSクラスタの再作成が必要になります。そのため、現状は配置戦略まで対応しきれていないのですが、今後する予定です。
まとめ
今回の問題のインフラレイヤーでの原因は、ECSのバックエンドとして使われていたEC2 ASGのスケールイン時の挙動とCloudFrontでのエラーキャッシュでした。CloudFrontでの5xxエラーのキャッシュTTLを指定することで緩和できました。対応完了後、もしバックエンドに不具合があったときの負荷増加防止策としてエラーキャッシュが有効のため、TTLの設定を数秒に設定しました。また、EC2のオートスケーリングがECSの状況を考慮しない(連携がされていない)ため、コンテナが実行されているインスタンスをASGのスケールインから保護する設定を入れました。この対応の結果、コンテナが実行されているインスタンスが停止されなくなり、インフラ起因の5xxエラーを撲滅できました。
SREの取り組みについて
現在、私はサイバーエージェント技術本部のサービスリライアビリティグループに所属しています。サービスリライアビリティグループでは、SREの取り組みを進めています。その一環として、Postmortemと呼ばれる障害報告書のようなものを作成しています。今回の記事の元になったのは、Postmortemの1つです。

Postmortemでは、上の図のように、障害起因や原因、解決方法、残タスク、障害タイムラインなどをまとめています。Postmortemの活用により、インフラエンジニアと開発者間の障害に関する議論や、他サービスでの同様障害の防止やノウハウ共有ができるようになっています。
所感
Datadogが導入できていたことにより、記事内の図の通り、一つの画面で全レイヤーでの異常を確認することができました。特に、dd-agentを導入していたことによって、例えば特定のインスタンスで稼働していたコンテナの一覧などのような、CloudWatchだけでは取得できない情報もまとまっていて、調査が楽でした。今後は、さらなる調査簡略化、CloudFrontのアクセスログやALBのログをクエリ、可視化できるシステムの構築・導入を考えています。