
こんにちは。技術本部 プライベートクラウドグループの中西 (@whywaita) です。
先日開催されたbuilderscon tokyo 2019にて発表させていただいた、「なぜディスクレスハイパーバイザに至ったのか」について解説させて頂きます。
発表スライドはこちらになります。
今回ご紹介するプライベートクラウドについて
サイバーエージェントでは、社内向けにプライベートクラウドを運用しています。
私が所属するメディア事業部ではAmebaなどのプロダクトを運用するためのプライベートクラウドを展開しており、現在は3リージョンを利用しています。
その中にあるTKY02が最も新しいリージョンです。VMを起動させているコンピュートノードの物理サーバは約150台、約12000コアほどで現在は運用しています。
今回はTKY02において採用しているアーキテクチャである、ディスクレスハイパーバイザについてご説明します。

プライベートクラウドはつらいのか?
「仕事でプライベートクラウドを運用しています」と言うと、皆さん決まって「夜寝られていますか?」「あのつらいやつですか……」などの反応をいただきます。
近年多く使われるようになったパブリッククラウドは、ユーザが物理的な要件を意識せずに仮想マシンを立ち上げることができることが大きな利点の1つです。
プライベートクラウドを運用するということは、我々はこのような要素も含めて管理するということです。

本記事では、「仮想ネットワーク」「VM Manager」「物理サーバ」のレイヤに集中してお話しします。
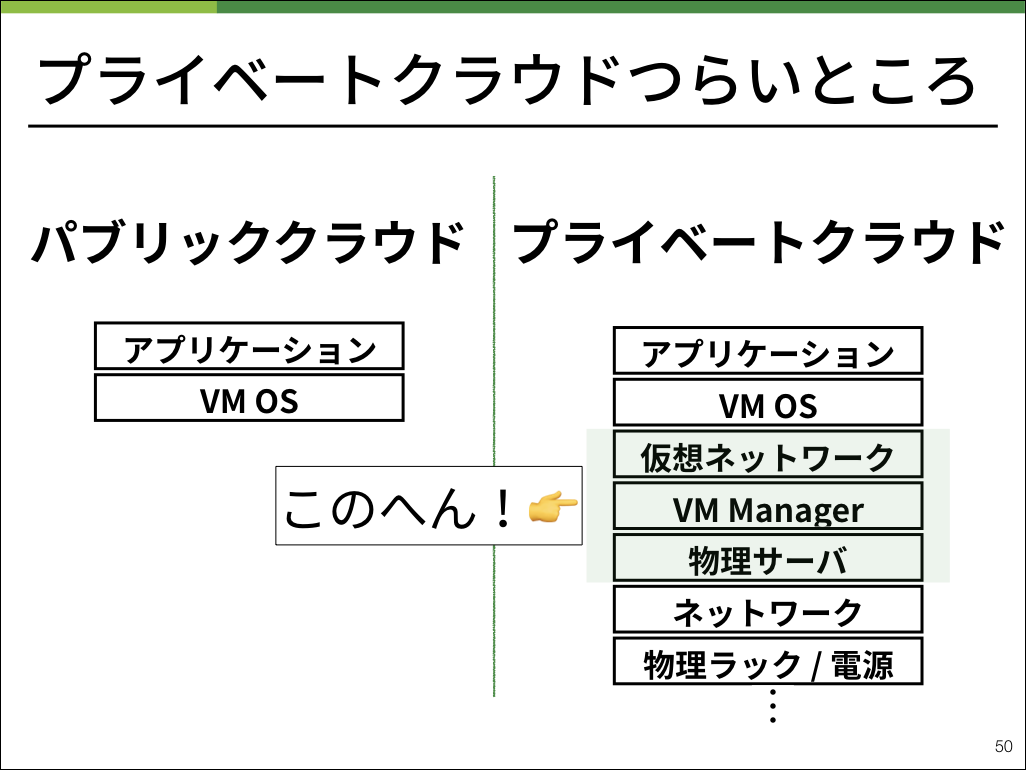
今までのプライベートクラウド
数百台のラックマウント型物理サーバを運用するにあたって、壊れやすい部分はどこでしょうか。
我々は「動いている部分」であると考えています。物理的に摩耗してしまったり、何らかの衝撃によってモーターの軸がずれてしまったりしてしまい、突然エラーを起こすことがあります。
我々の肌感覚としては、その中でもHDDが最も壊れやすい部品だと思っています。HDDを分解してみた方にはわかると思いますが、HDDの中では円盤が回転しており、円盤の中にデータが保存されています。
この部分が非常に壊れやすく、もし壊れた場合はもちろん交換処理が必要となります。
他にも薄いラックマウント型のサーバに必要な小さなファンなども非常に壊れやすい部分です。

サーバが壊れてしまうとどうなるでしょうか。
在庫として保存されている機材を追加する必要もあります。
機材を追加する際には「LANケーブルの配線が正しく刺さっているか」「IPMIの設定は正しいか」「OSの設定は異常ないか」などなど、多くのことをダブルチェックするため2人体制で確認します。

交換用在庫を持ってきてから仮想マシンが立ち上げられるようになるまで、概ね1台あたり1時間ほど要していました。
もちろん追加するサーバの数が増えれば増えるほど負荷は多くなっていきます。

とはいえ、サーバが壊れてしまうことを回避するのは不可能です。
そのために、できるだけサーバ作業などの負担を減らすことを目的として、ディスクレスハイパーバイザを導入しました。
ディスクレスハイパーバイザ
作業する方の負担や確認する項目が増えている理由として、サーバが壊れる前の状態と差異がないように起動する必要があるということが挙げられます。
プライベートクラウドを行う上で、いくつかのステートを管理する必要があるのですが、出来るだけステートは1箇所にまとめて管理したいものです。

そのために、コンピュートノード内でステートを管理しているディスクを全て外して管理することにしました。
我々が利用しているプライベートクラウドでは、OpenStackを利用しています。
OpenStackはPythonで実装されているVM管理ソフトウェアで、OSSとしてソースコードが公開されています。
RabbitMQやmemcachedなどのメッセージングキューを用いて、コンポーネントごとにMicroServicesとして実装されています。
我々はこの特徴に注目し、コンテナ管理基盤であるKubernetes上で動作させています。
※ nova-apiはコントロールプレーンに必要なプロセス、nova-computeはコンピュートノードに必要なプロセスです。

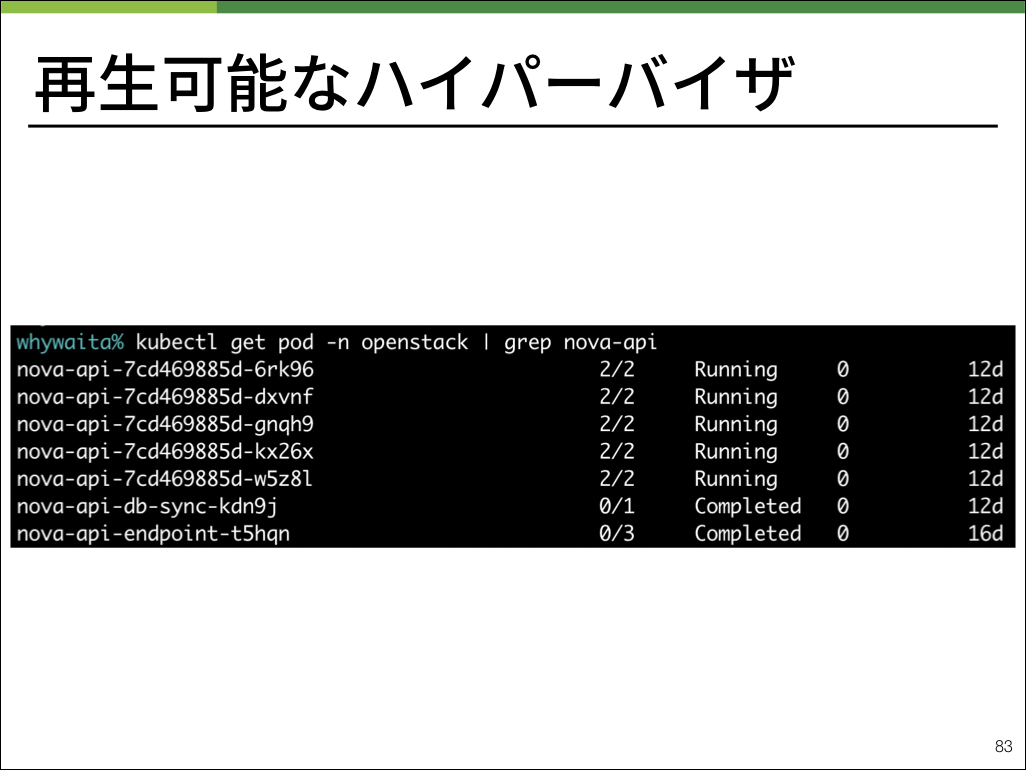
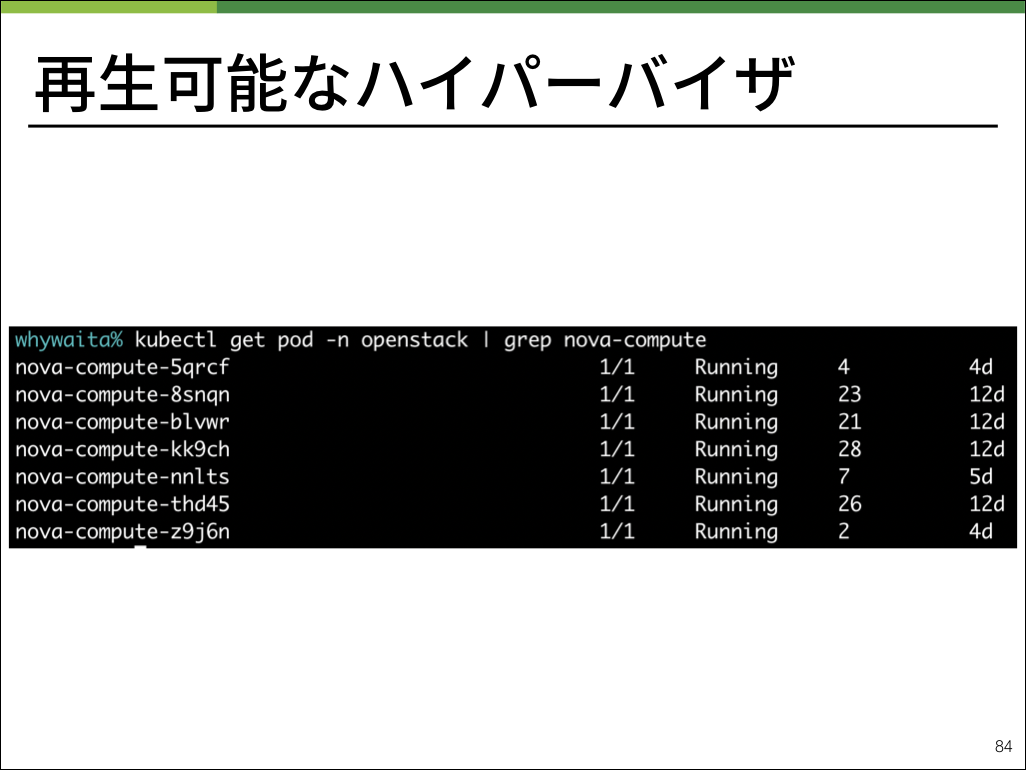
実運用ではOpenStackを動作させるためのKubernetes manifestをHelmを用いてopenstack-chartsとして管理しており、管理が非常に楽になっています。
OpenStackで必要なコンポーネント群をKubernetesのPodとして管理することで、全体のディスクレス化が見えてきます。
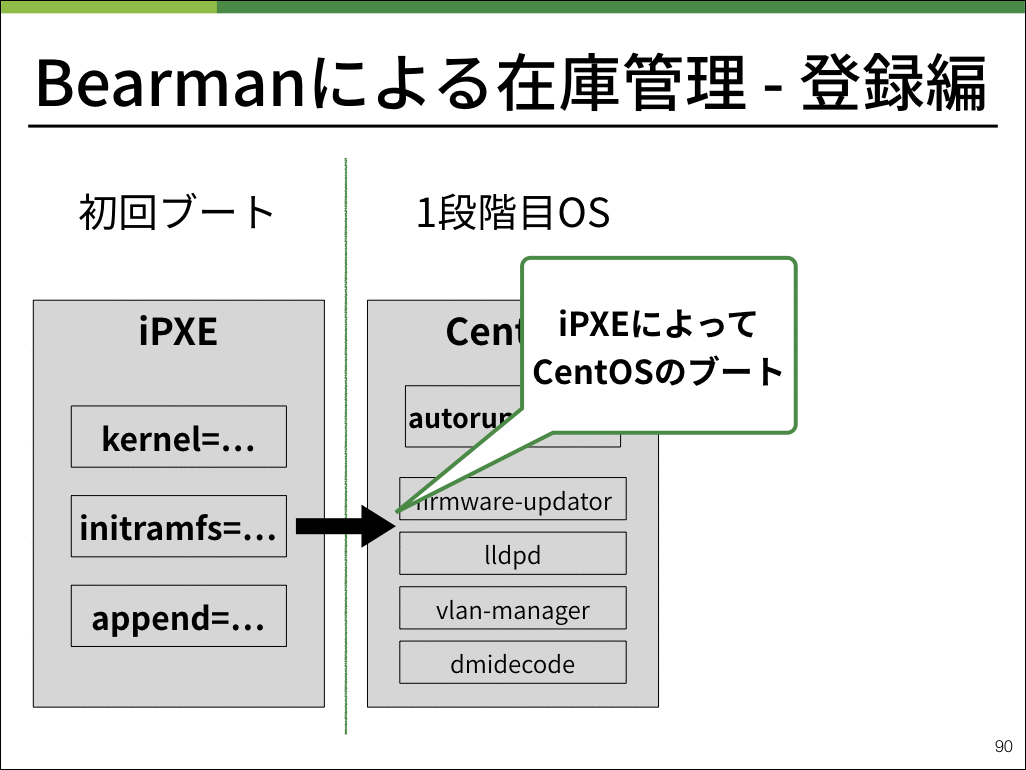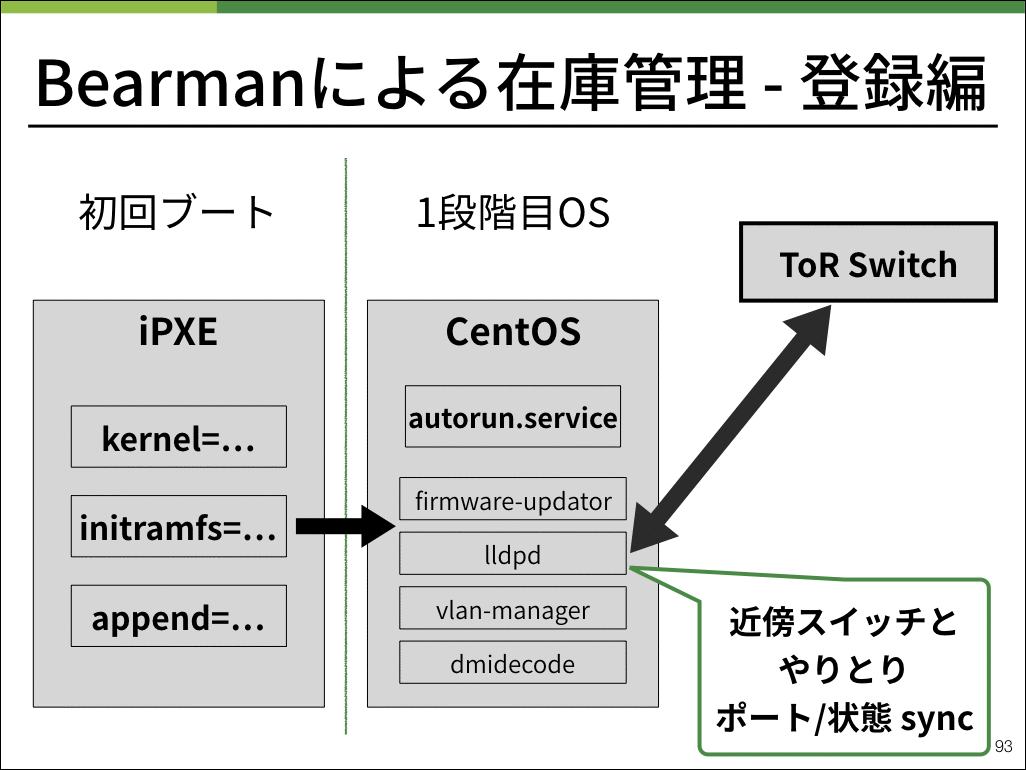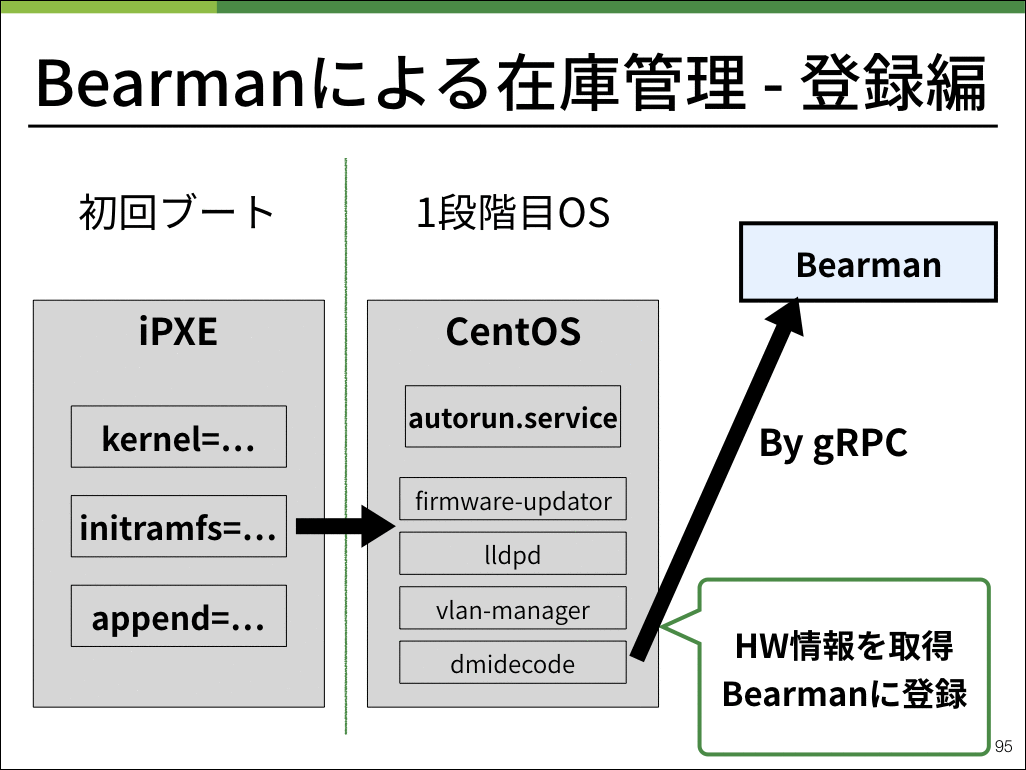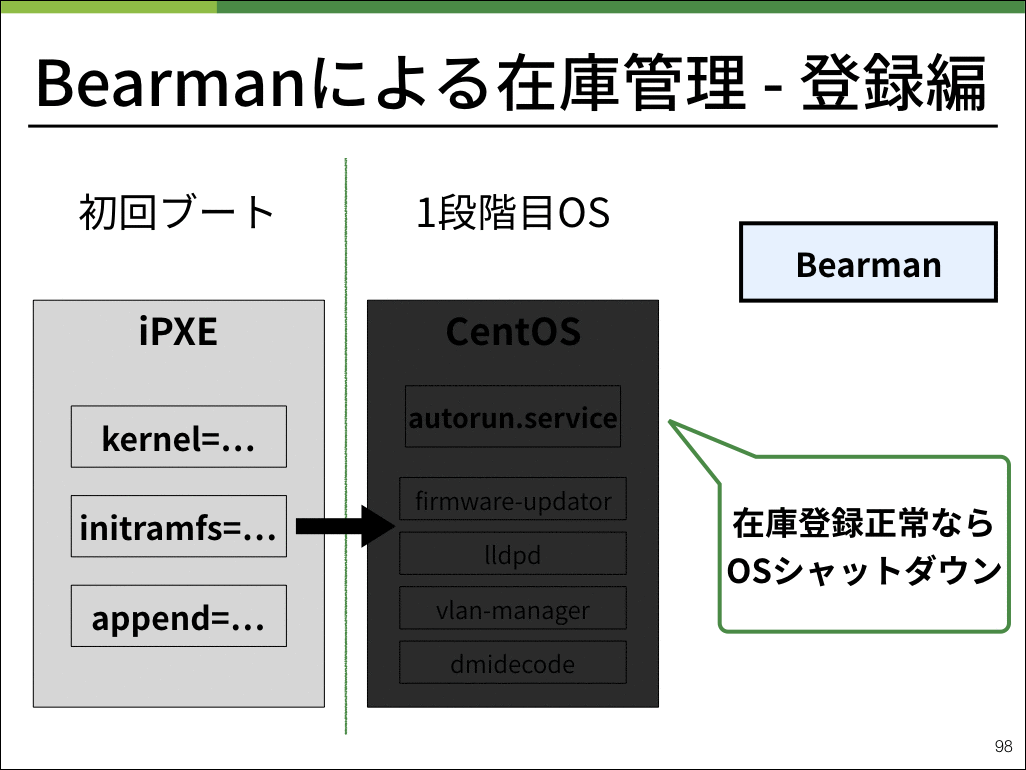
弊社ではコンピュートノードをはじめとして、物理サーバを管理するためにBearmanと呼ばれるアプリケーションを開発しました。
Bearmanは物理サーバで起動させるOSや、IPMIの設定情報を保持しています。

実際の登録作業では、様々な起動チェックを行いつつ最終的にシャットダウンし在庫登録完了となります。

具体的な動作に関しては以下のgifアニメをご確認ください。スライドのスクリーンショットとなっているので、ゆっくり確認したい方はslideshareからスライドを確認ください。
正常に登録作業が終わった場合にシャットダウンされる仕様は、作業する方の負担を大幅に減らすことができます。
数十台の物理サーバをセットアップする際には、ネットワーク配線をチェックした上で全て電源ボタンを押すだけで登録が完了します。
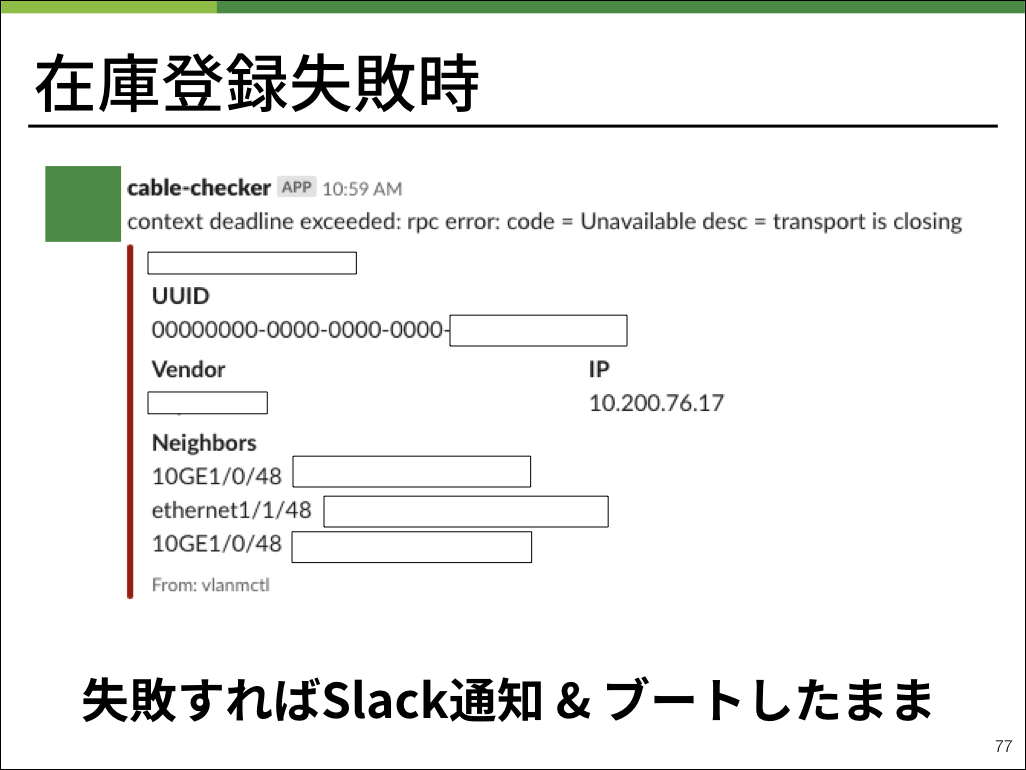
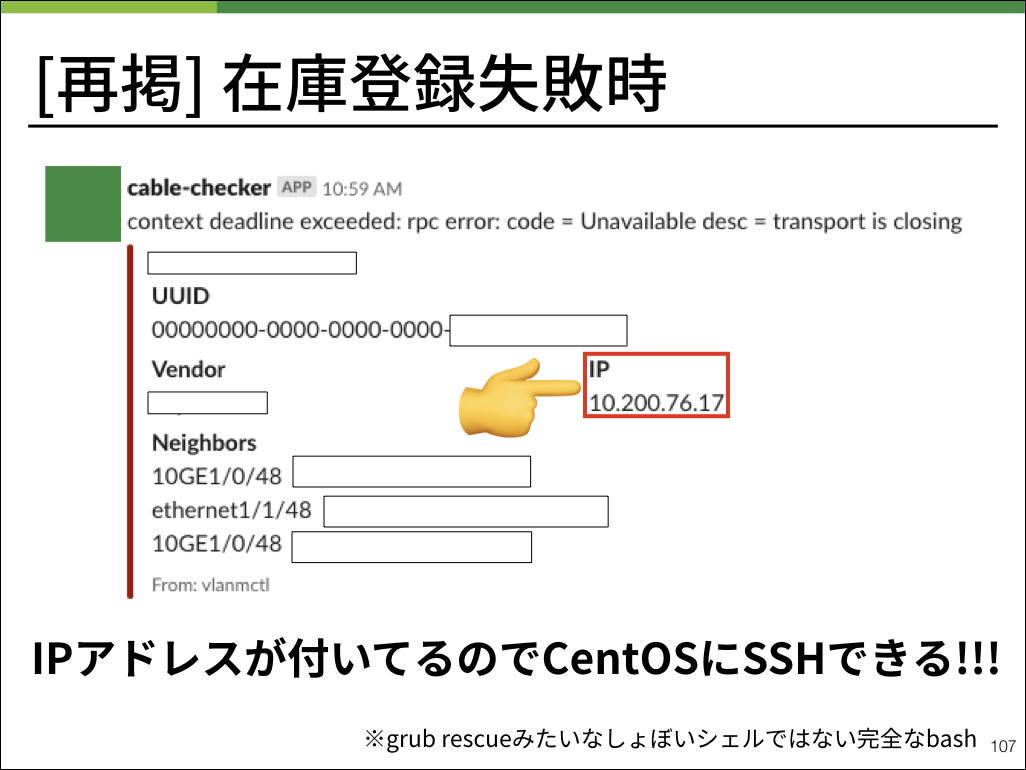
逆に言えば、もし起動後しばらく経ってもシャットダウンしていない物理マシンは何らかの理由でBearmanの在庫登録が失敗してしまった個体ということです。
物理サーバはラックマウントした状態でも見やすい位置に起動を示すLEDランプがあるため、そこから起動したままの物理サーバだけを確認すれば良いという仕組みになっています。
また、登録に失敗した場合はこのようなslack通知が発砲されます。
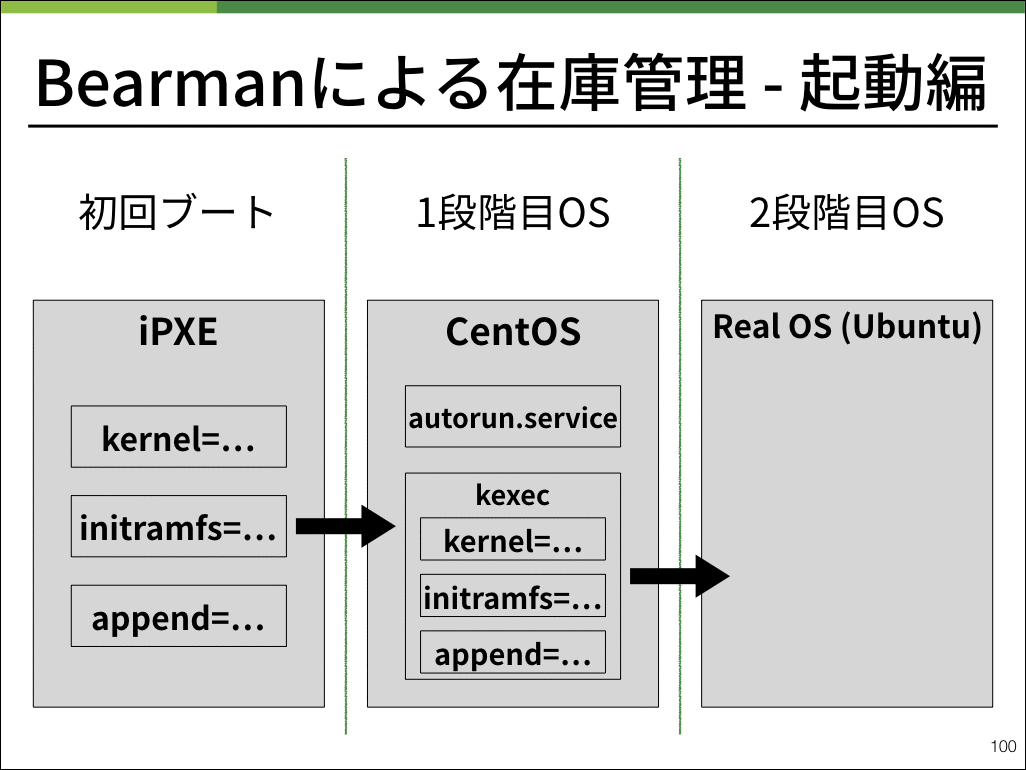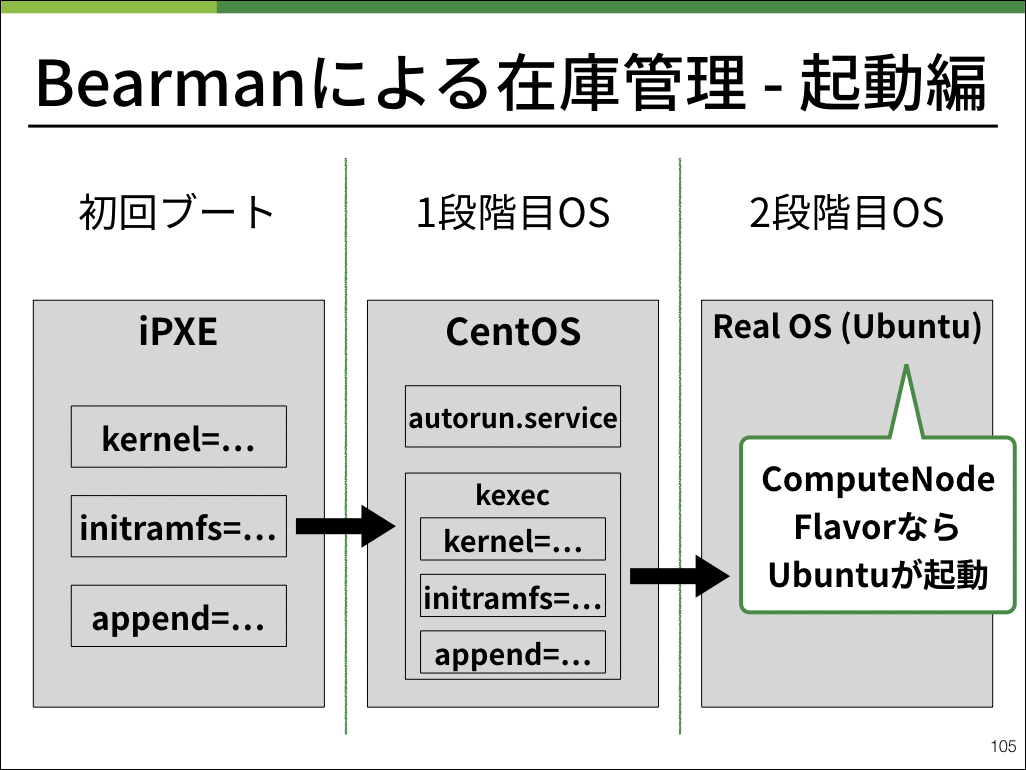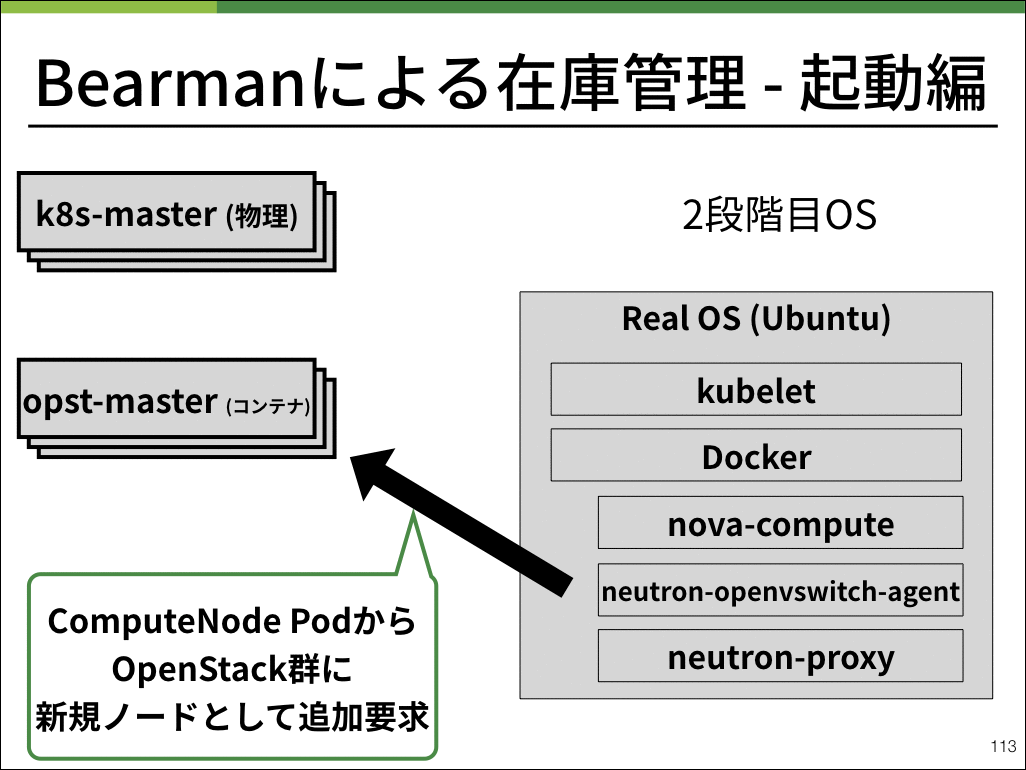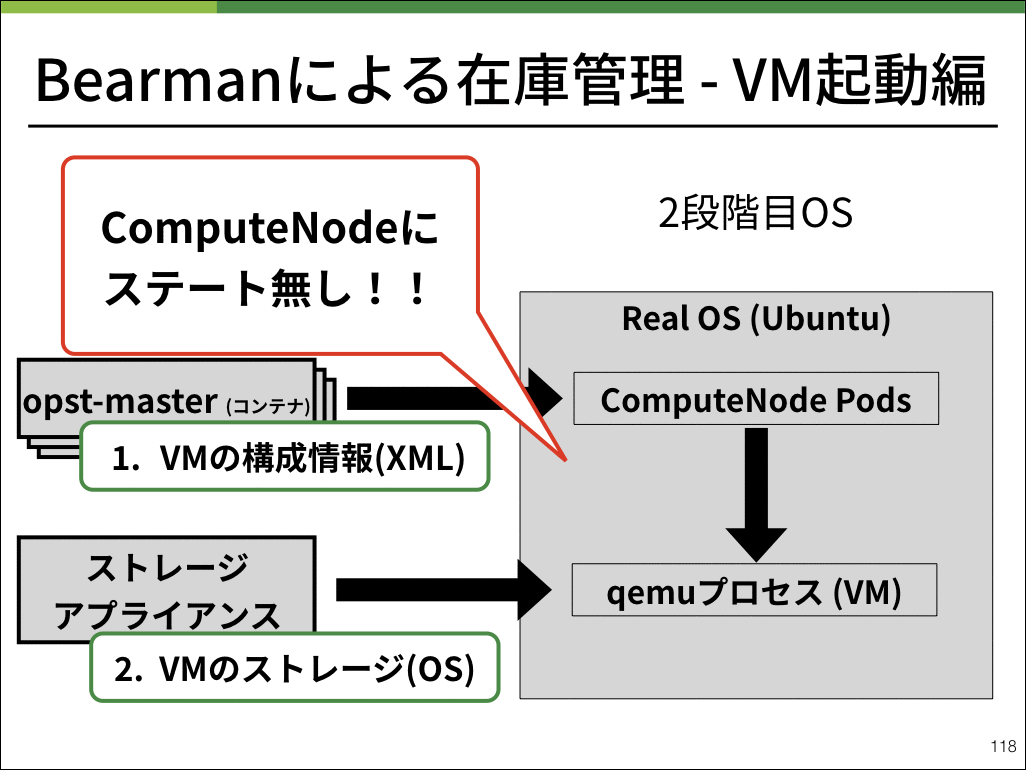
Bearmanの起動プロセスとして、1度CentOSを起動したあとに、物理サーバ上で動作させたいOSに切り替えるという動作を実装しています。
在庫登録作業をベアメタル上で動作するGRUBのような小さなシステムではなく一般的なLinuxで行うことにより、トラブルシューティングをデータセンターのコンソールではなくSSHで遠隔に、各種Linuxコマンドが使えない小さなシェルではなく一般的なbashで行うことができます。
起動時もBearmanを用いて物理サーバのオンメモリ上にOSを起動します。
具体的な動作に関してはこちらもgifアニメにしてみました。詳しく確認したい方はスライドをご確認ください。
ユーザが利用する仮想マシン内のストレージは外部からマウントし、仮想マシンのスペックなどのメタ情報をOpenStackのコントロールプレーンが保持することにより、コンピュートノード上に保存し整合性を保つべきステートを完全に排除することができました。
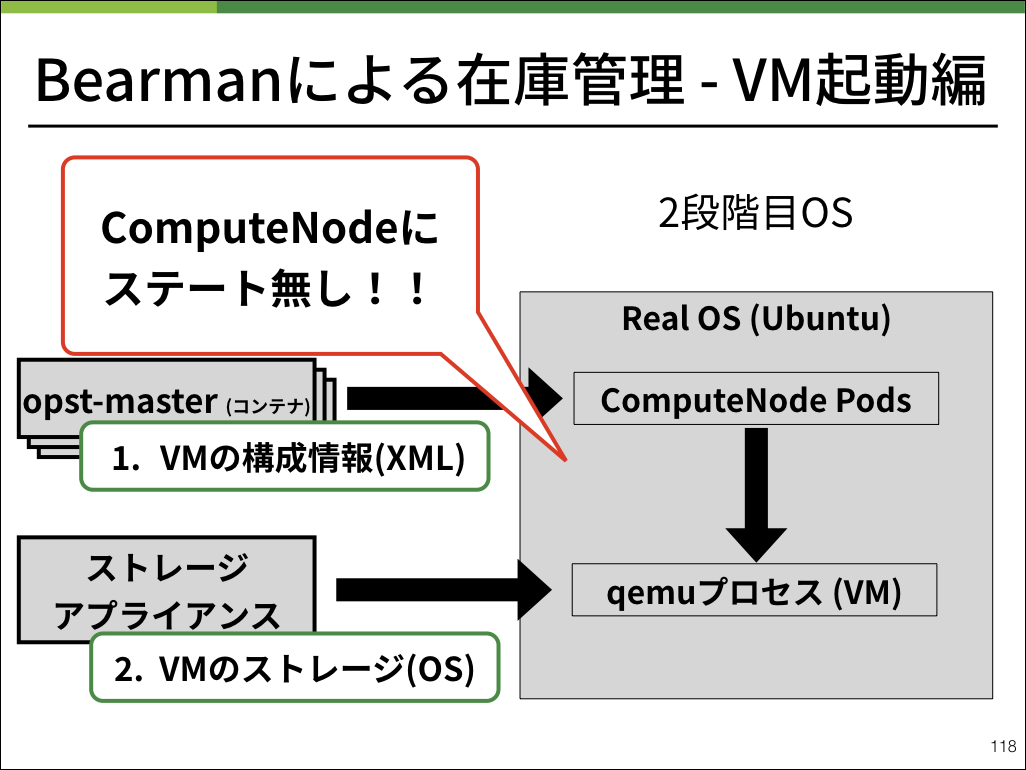
これによりコンピュートノードを完全オンメモリで起動することができました。何かコンピュートノードにおいて問題が発生した場合は、仮想マシンをなくした上で再起動すれば綺麗な状態で起動するようになり、メンテナンスコストを抑えることができました。

そのほか、ユーザ向けの仕様としてはこのようになっています。

ディスクレスハイパーバイザへの道
次に、われわれがどのようにディスクレスハイパーバイザに至ったのかです。
コンピュートノードを全てオンメモリに起動させるアーキテクチャは、突然天恵を受けたのではなくその前のディスクレス知見が活きた結果でした。
ディスクレスハイパーバイザ以前のディスクレスシステムの誕生は、2016年。
Appleにより発表されたApp Transport Securityの対応強制化によるものでした。

それまでHTTPで通信していたバックエンドアプリケーションをHTTP over SSLに対応するために、プライベートクラウドチームとしてSSL終端を行うサービスが必要となりました。
それまではロードバランサーアプライアンスを購入して利用していたのですが、価格面やその他の面からもあまり現実的な選択肢ではありませんでした。

そこで、ディスクレスにOSを起動しその上でNginxを起動させることでSSL終端を行うシステム、sslproxyが開発されました。
PXEでブートを行い、各ホストやSSL証明書などの設定はgitリポジトリによって集権管理及び自動生成と配布が行われるシステムです。

古いデータセンターにおいてもSSL終端の要件があったため、古いサーバの利活用として信頼性の低いディスクを抜いた上で運用を行っていました。
sslproxyは結果として非常に安価に要件を実現することに成功し、ほぼトラブルもなく運用の経験値を高めることができました。
sslproxyの経験から、新しく構築するTKY02においてコンピュートノードのディスクレス化の発想に至りました。
おわりに
今回ご紹介したディスクレスハイパーバイザは、TKY02として稼働を開始しています。
一部本番運用しているサービスもあり、実運用期間として更なる安定性向上と新しい価値の創造を続けていく予定です。

また、これからのデータセンターアーキテクチャを作るメンバーも絶賛募集中です。
興味のある方はネットワークエンジニア、クラウドプラットフォームエンジニア、データセンタースペシャリストなどでぜひご応募ください。
学生向けには就業型インターンやイベントなども実施しています。興味のある方はぜひご応募ください。
弊チーム企画イベントとしてデータセンター見学会も開催しています。
残念ながら先日 Vol.1 の募集は終了してしまったのですが、今後も継続的に開催する予定です。次回のお知らせをお待ちください。
