
AI事業本部 Dynalystでデータサイエンティストをしている藤田です。
Dynalystの開発チーム内にはデータサイエンス(以降DS)チームがあり、そこにはデータサイエンティスト・機械学習エンジニア(以降まとめてデータサイエンティストと呼ぶ)たちが所属しています。私がこのチームで働く中で、「プロダクト所属のデータサイエンティストがどこまでエンジニアリングをすべきなのか」ということを考えることがあったのでまとめてみました。当然これは一般的な答えではなく、人・チーム・組織の現状や目指すべきところによって答えは変わるので、あくまで1チームの1個人が考えたこととして読んでもらえればと思います。
プロダクト所属と横断DS組織所属
エンジニアリング云々の話をする前に、まずプロダクト所属と横断DS組織所属のデータサイエンティストの違いについて軽く説明します。両者のメリット・デメリットについても書きたいのですが、今回は割愛させていただきます。
プロダクト所属
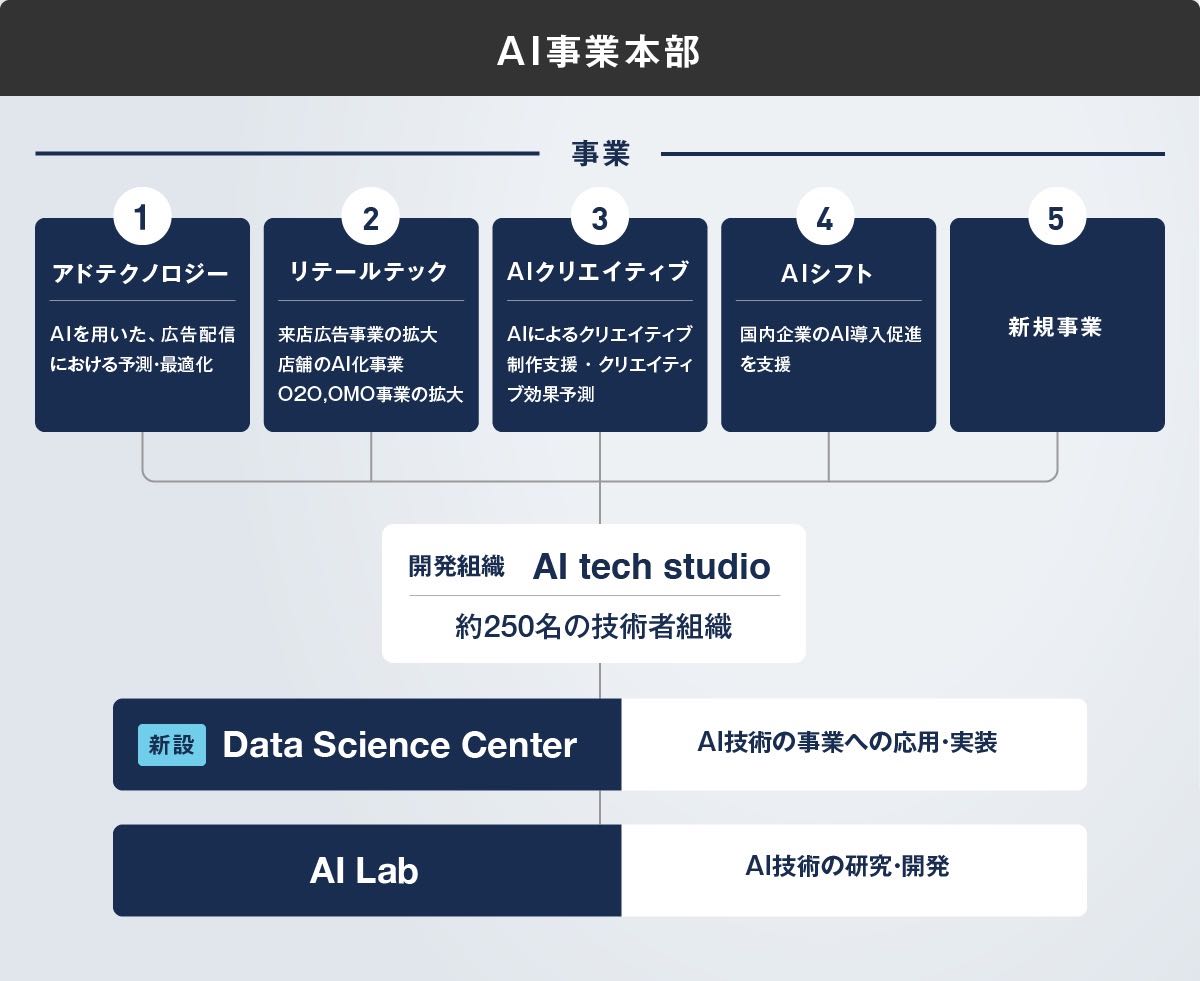
下の組織図の各事業領域ごとにプロダクトがいくつかあり、Dynalystはアドテクノロジー部門に属する1プロダクトです。AI事業本部のデータサイエンティストは基本的に各プロダクトにそれぞれ所属しています。彼らは所属プロダクトに貢献するためにDSに関わるタスクをし、プロダクトから評価をされます。
横断組織としてのAI LabとData Science Centerがありますが、前者は研究、後者はプロダクト所属データサイエンティストの支援がメインなので、それらの組織がプロダクト横断で機械学習の導入を進めているわけではありません(協力して何かをやることはとても多いです)。Dynalystのプロダクトマネージャーの福原さんの記事も参考にしてください。
AI事業本部のプロダクト開発体制とそれを支えるサポート
横断DS組織所属
横断DS組織とは、事業部やプロダクト横断でデータ分析をしたり機械学習の導入を進めたりする組織のことです。少し古いですが、メルカリさんのブログがわかりやすいと思います。
メルカリの分析チームとは?その全ての疑問にひとつひとつ答えます
プロダクト所属と横断組織所属のデータサイエンティストではエンジニアリングに対する考え方が違います。以降ではプロダクト所属の場合について書きます。
プロダクトのデータサイエンティストのタスク
プロダクト所属のデータサイエンティストの主なタスクを挙げると以下のようになります(Dynalystのタスクを一般化したものですが、多くのプロダクトにもあてはまるのではないかと思います)。
- データ分析タスク(プロダクトの意思決定に関わる分析をする)
- DSタスク
- MLエンジニアリングタスク
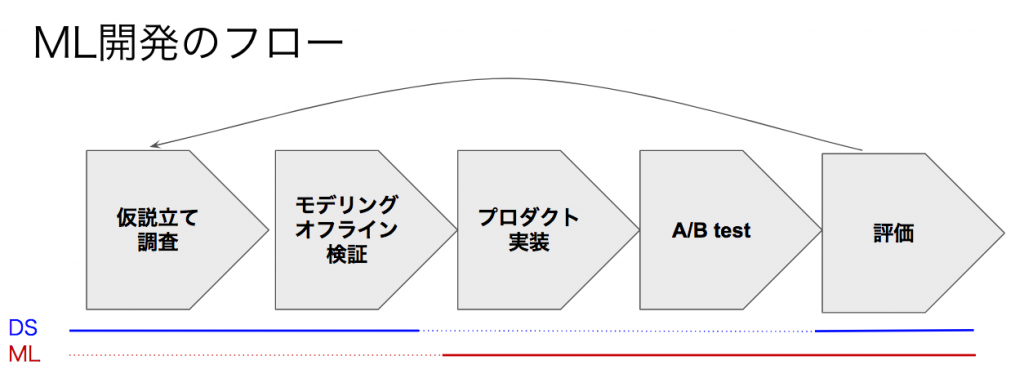
DSタスクとMLエンジニアリングタスクをあわせてML開発とし、深堀りします。
DSタスク
DSタスクでは、仮説からデータを使って課題を洗い出し、解決策としてMLモデルの導入 / アップデート(MLを使わない場合もあり)を提案します。そして、提案したMLモデルをオフラインで検証します。また、実際に本番環境でのA/Bテスト結果を評価し、必要であればさらなるモデルのアップデートを行います。下図の青線の部分が該当箇所です。
MLエンジニアリングタスク
MLエンジニアリングタスクとは、DSタスクで提案されたMLモデルが実際にプロダクトで動くようにする業務です。特徴抽出、モデル更新のための学習、推論時に引いたパラメータの計算などの実装が必要になります。また、必要に応じてログの設計 / 実装などのデータエンジニアリングもする場合があります。下図の赤線の部分が該当箇所です。
ML開発を分業するか全部やるか
ここでやっと「データサイエンティストがどこまでエンジニアリングをすべきか」という本題に入るのですが、すべきかどうかはともかく、Dynalystではデータサイエンティスト全員がそれぞれ一連のML開発フローを担当しています。たとえば
- 仮説からデータの調査、オフライン検証によってA/BすべきMLモデルを決める
- MLモデルのプロダクト実装1: PythonとScalaでバッチ学習の実装
- MLモデルのプロダクト実装2: Scalaで推論側の実装
- A/Bテスト1: 期待通りにMLモデルが動作しているかの確認(学習ジョブがコケないか、パラメータが引けているかなど)
- A/Bテスト2: 既存モデルとの性能比較
レイテンシの要求が厳しくない、捌くリクエストがそこまで多くないなどの場合には、推論APIをPython等で実装することで、MLとアプリケーションを分離できるため分業が簡単になります(アプリケーション側の実装にはDS知識があまり必要でなくなるため)。しかし、DSPでは大量のリクエストを短期間で捌かないといけないので、アプリケーション側でもMLロジックを実装する必要が出てきます。つまり、そこでもDS知識が重要になりMLとエンジニアリングを分けにくいのです。
逆に、完全にDSとエンジニアリングを分けられる部分(ログの実装など)はバックエンドエンジニアにお願いするケースが多いです。
全部やるメリット / デメリット
ML開発の一連のフローを全て一人のデータサイエンティストが担当する場合のメリット / デメリットを列挙します。
メリット
- DS視点でのシステム設計ができる
自分でMLモデルをプロダクト実装することで現状のシステムを理解できますが、それによってDS視点でのシステムのアーキテクチャのアップデートができるようになります。例えば、「学習ジョブのパイプラインを整備できる」、「A/Bテストしやすい設計を考えられる」、「新しいログを追加する際は、よりバックエンドで実装しやすく(システム負荷が低く)、よりデータサイエンティストが使いやすい設計を考えられる」などです。また、システム的な実現可能性 / 相性を考慮してDSタスクに取り組めたりもします。事前にML開発の工数を予想するためにも有用です。
- データから実装のバグを発見できる
これはDS / エンジニアリングで分業していると発見しにくい部分です。たとえば同じチームの加藤くんが書いてくれた記事は良い例です。
本番環境で動く機械学習モデルの性能を追試することの重要性
- 誰かに頼まなくていい
プロダクトの状況によっては、タスクを頼むにもバックエンドのエンジニアの手が空いていないというケースもあります。そういったときには、MLモデルを本番で動かすところまで自分でやれると便利です。
- 全部をやらない場合でも、バックエンドエンジニアとの会話がスムーズになる
データサイエンティストがエンジニアリングを知っていることで、バックエンドエンジニアとの会話がスムーズになり目指したいものを協力して開発するのがやりやすくなります。実際にデータサイエンティストがエンジニアリングまでやることはなくても、エンジニアリングの経験は役に立ちます。
デメリット
- チーム全員がDSとエンジニアリングに習熟する必要がある
DSとエンジニアリング双方の習熟には時間がかかるため、専門性を磨く時間が削られてしまいます。さらに、そもそもチームメンバーがDSにもエンジニアリングにも興味があるという状態でないと幸せになれません。
- 大人数になると機能しない
A/Bテストでの待ち時間を考慮すると所属人数 x 1.5くらいの開発タスクが同時期に走ることになるので、人数が増えるほどそのコンフリクトが起きやすくなります。同じ予測タスクに対してそれぞれが別々のアプローチで進めるのは非効率です。 事業責任者の木村さんがチーム人数とDSプロジェクトの観点から書いた記事があるのでこちらも参考にしてください。
DataScience系プロジェクトの育て方
結局どこまでやるべきか?
以下では私の個人的な見解を、チームとしてどうすればよいかと私自身のキャリアとしてどうしていきたいかに分けて書きます。
チームとして
データサイエンティストが一連のML開発フロー全てを自分で進められるのはかなり強みになります。しかしチームメンバー全員にそれを求めるのは、チームが大きい(10人以上とか)と機能しません。ある程度の分業体制と、一連のフローを知るデータサイエンティストがレビューできる体制が必要になると考えています。これは単に分業すればいいという話ではなく、システム的に分業しやすくする工夫も必要です。この部分についてはMLOpsと絡めて、解決のためのアクションを現在進行系で模索しています。
私自身として
私は経済学出身で、データ分析はやっていましたがプロダクト開発の経験は入社するまでゼロでした。ですが、開発にも挑戦してみたかったので(そしてやりたいと言ったらやらせてもらえたので)やってみました。すると、システムの全体像を把握することでMLロジックの実装の難易度やプロダクトとの相性がわかり、それをMLロジックのアップデートに活かせることがわかりました。つまり、エンジニアリングを知ることでDSタスクをうまく解けるようになったということです。
そして、自分が作ったものが実際に動いてユーザからフィードバックを受けられるというのはとても楽しいです。新卒であるならとりあえず一回はエンジニアリングをやってみるのがいいのでは?と思います。
では、どこまでエンジニアリングをやるべきかという話ですが、私としてはDSタスクとのシナジーがある部分をやり、切り分けられるところは切り分けたいと考えています。これは、私の興味 / 強みにしていきたい部分はあくまでDSだということと、私がエンジニアリングを真剣にやっても本職のMLエンジニアやサーバサイドエンジニアに比べて作業時間が何倍もかかり、プロダクト的にも非効率だからです。
また、エンジニアリングにはいろんな程度があると思います。「MLモデルの特徴量を変えるだけのA/Bテストのための実装が追加できる」、「バックエンドエンジニアと協力しながらシステム設計ができる」、「ゼロベースでシステム設計から実装まで自分でできる」などです。自身がどのくらいエンジニアリングに習熟したいかを考えるのも重要ではないでしょうか。
以上のことはあくまで私の考えですが、読んでくださった方がDSとエンジニアリングについて考える際の参考になれば幸いです。