
オレシカナイトとは
オレシカナイトは、「ABEMA」や「Ameba」をはじめとしたサイバーエージェントグループが運営するメディアにおいて、パブリッシャー独自の視点でアドテクノロジー開発を行うエンジニアの横断組織 「CyberAgent Publisher adTechnology Association (PTA)」が主催する技術者向け勉強会です。
今回のテーマは「予測」。
当社のエンジニアが登壇し、「ABEMA」や「Ameba DSP」などの広告システムで実際に使われている予測ロジックを紹介しました。

パーソナライズド広告配信における純広告の在庫管理(株式会社AbemaTV 広告本部 フルスタックエンジニア: 古川 俊太)
まずは、株式会社AbemaTV 広告本部 フルスタックエンジニアの古川の発表です。

広告における「在庫」とは、総インプレッション数のことです。
受け入れ可能在庫を算出するためには、未来の総インプレッション数を予測する必要があります。
この予測は過去の実績の平均値から作られています。
余裕を持たせるためにその内の何割かを受け入れ可能在庫として設定していたり、月次で見直す、閾値を超えたもの(外れ値)を除外する、といった工夫もなされているようです。
そして、予測値からすでに受け入れた案件分のインプレッションを差し引いて、残りの受け入れ可能在庫を計算する、これが純広告の在庫管理の大枠です。
広告主にとっての理想は、広告出稿費をできるだけ抑えながらも、より多くの売上を出すことです。
これを実現するために、パーソナライズド広告配信システムがABEMAへ導入されました。
パーソナライズド配信ではターゲティング項目が増えたため、在庫管理の難易度が上がりました。この問題にどのように対処したかが本発表の重要なポイントでした。
以前は、全ての項目の組み合わせに対してそれぞれ在庫管理を行っていましたが、項目が増えるとその組み合わせも膨大となり、現実的ではありません。
そこで、実績ログの一部を切り取った擬似ログを使って、比率による消費在庫の算出を行うことにしました。
例えば、ある案件を受け入れるか判断する際、その案件のターゲティング項目(20代、男性)が擬似ログ内で何割を占めるかによってその項目の総在庫を算出します。
この擬似ログは、期間については検証中で、サンプリング方法は一様確率のランダムサンプリングとのことでしたが、今後変わっていく可能性も示唆していました。
次に、すでに消費されている在庫を算出する必要がありますが、たとえすでにある案件(iOS)が対象のターゲティング項目を含んでいなかったとしても、iOSを含むグループの中には[20代、男性]の項目を含んでいるものも存在するはずです。
なので、擬似ログ内でiOSかつ[20代、男性]の項目がiOS全体の何割を占めるかによって、消費在庫のiOS案件内に含まれる[20代、男性]の数を算出し、それを[20代、男性]の消費在庫として計上します。
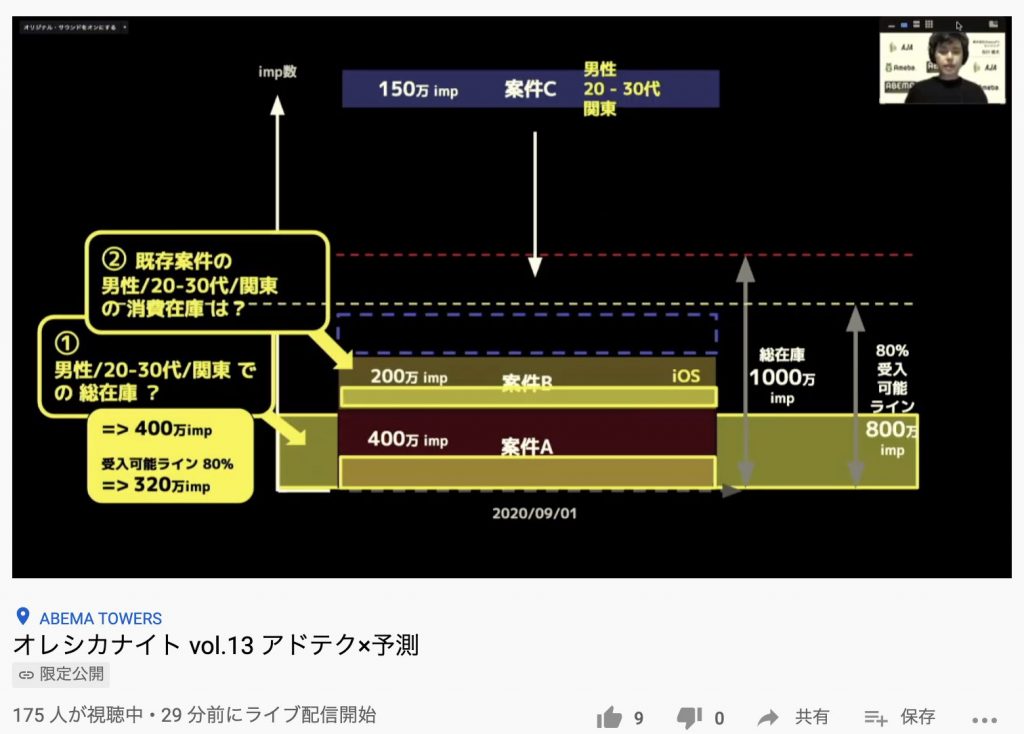
このようにして、パーソナライズド広告配信での在庫管理を行っています。
在庫の算出に比率を使っているのがとても興味深かったです。
発表スライドはこちらをご覧ください。
広告配信の予測におけるデータの反映速度(株式会社サイバーエージェント 技術本部 秋葉原ラボ データサイエンティスト: Tristan Irvine)
次は、株式会社サイバーエージェント 技術本部 秋葉原ラボ データサイエンティストのTristanの発表です。
DSPで広告配信を行う際には入札額(CPM)を決める必要がありますが、その適切な入札額の予測に機械学習が用いられています。
広告の配信結果(impressionやclick, conversion)を学習サーバーへ、そして学習結果を予測サーバーへ、さらにその予測の結果が学習サーバーへ、とフィードバックループが回り続けることで精度を高めます。

このフィードバックの頻度は、高いと精度の調整や新しい学習データをすぐに使えるという利点がありますが、低いと複雑な精度の高いモデルを扱えたり、問題に気付きやすいという利点もあります。
今は更新頻度が遅いことで問題の広がるケースが多いようです。
本発表は、この問題への対策に重点を置いて述べていました。
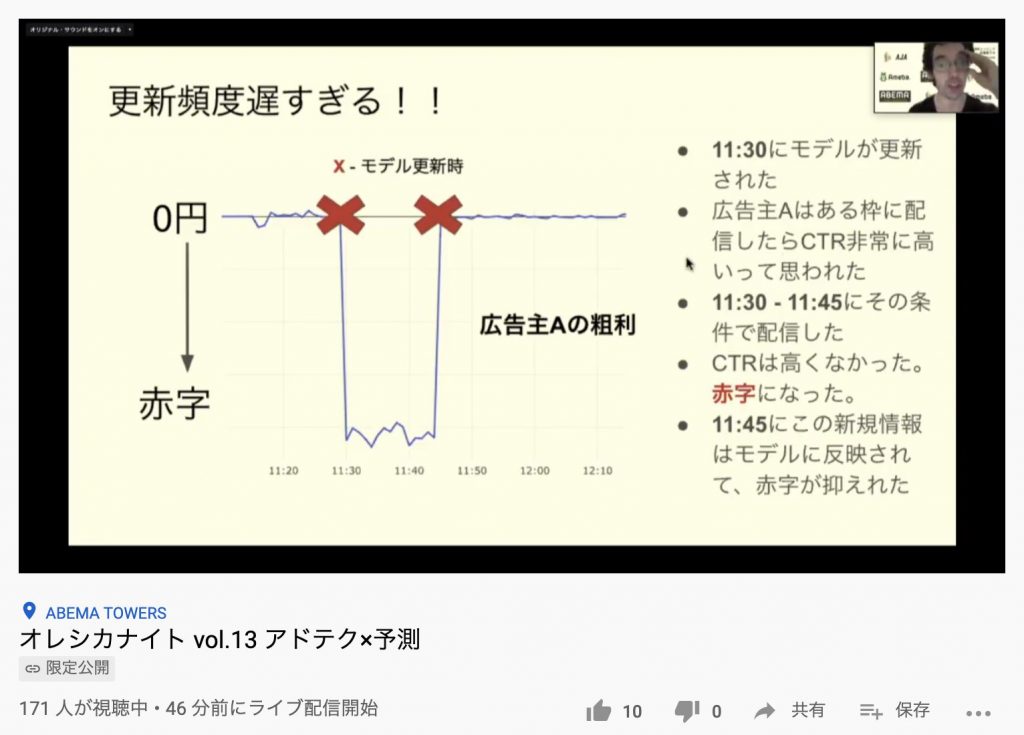
例えば、モデル更新によってたった15分で急激にCTRが悪化して赤字になったことがあったり、3個のクリックのうち一つがたまたまCVしてCVRが高めに見積もられたということがありましたが、どちらも更新頻度が高ければ早く止血することができました。
とは言え、更新頻度を上げると精度が下がる、つまり暴発の危険性が上がるという問題もあります。
impressionが発生してからclickやconversionまでに至るのはしばらく時間が経ってからのことが多いからです。
こうした問題に対処するために、直近の傾向データを組成に組み込む移動平均システムが提案されました。
具体的には直近5分間の移動平均を計算するのですが、毎回全ての計算をすると重い処理となるため、今までの移動平均に直近の10秒間のimp数だけを足して計算するという工夫がなされています。
このシステムを導入することで、更新頻度を上げて例外的な値が入って来ても、平均化されるため暴発のリスクを抑えることができるようになります。
最後に導入の結果はまた次の発表で話したいとのことなので、どう改善されるのか楽しみです。
発表スライドはこちらをご覧ください。
どんな機械学習が広告効果を改善するのか(株式会社サイバーエージェント AI事業本部 AIR TRACK データサイエンティスト: 早川 裕太)
最後は、株式会社サイバーエージェント AI事業本部 AIR TRACK データサイエンティスト早川の発表です。

広告配信で機械学習が必要とされるのは、広告効果が改善されることを期待するからです。
しかし、実は思ったより改善されていないのではないかという意見もあります。
広告を出す出さないに関わらず、元々CVする予定の人を機械学習で選んでいるだけの可能性があるためです。
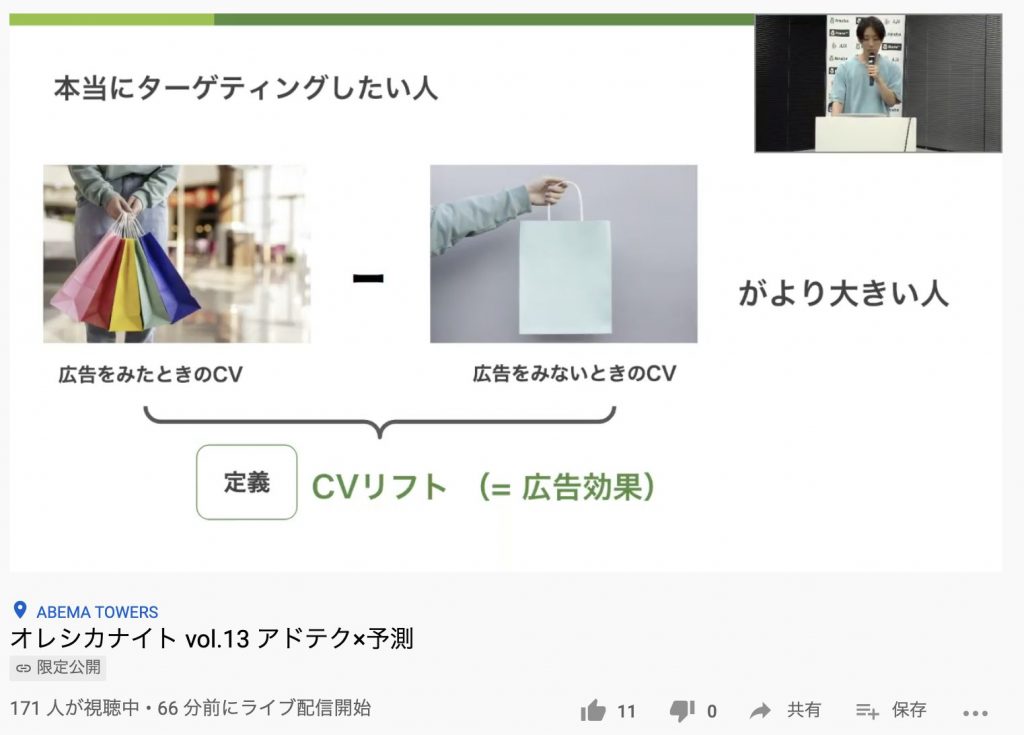
そのため、広告効果を測定するにはCVリフトを見るべきだと主張しています。
CVリフトとは、広告を出さなかった時に比べて、CVがどれだけ改善されたかを示すものです。
このCVリフトが広告主に受け入れられるのかという疑問があるかもしれませんが、AIR TRACKはO2O広告の配信サービスで、この種類の広告はまだ効果測定の指標が決まりきっていないため、特に問題はなかったそうです。
CVリフトをどのようにプロダクトに組み込んだのか、プロジェクトの進め方はどうだったか、この2つが本発表のメインテーマでした。
CVリフトの難しいところは、CVリフトしたかどうか手元のデータだけでは判断できないことですが、期待値の差分を取ることで推測値を計算します。
期待値と言っても、実際に手元にあるデータは広告を出した時と出さなかった時、どちらかの世界のものしかありません。
しかし、広告表示される確率で割ってやることで両方の世界の期待値を出すことが可能になるため、差分の計算ができます。
CVリフトとCVR、両方の予測を使った結果は、CVリフトの方がリーチ率やimp数は増加し、配信原価はかなり削減されていることがわかったとのことでした。
このCVリフトのプロジェクトの進め方についても示唆に富んだ内容がありました。
KPI整理を行いどんな指標を改善したいかはっきりさせた上で、A/Bテストありきのプロジェクトスタートが重要とのことでした。
特にA/Bテストの重要性を強調し、施策、技術を社会実装すべきか意思決定するためだけでなく、継続的な改善にも必要不可欠なので、こうしたA/Bテストができる環境と文化は重視すべきとのことでした。
また、プロダクトに応用されたかどうかが論文の価値を高めるという話も興味深かったです。
研究者がビジネス、プロダクト開発メンバーが連携してプロダクトの運用を目指すというのはとても意義のあることなのだと感じました。
発表スライドはこちらをご覧ください。
そんなオレシカナイトの14回目がオンライン開催12/11(金) 19:00開始
に開催されます!!(※時間の変動があります。コンパスよりご確認ください)
次回は「アドテク ビアバッシュ&LT大会~オレシカ忘年会2020~」
今年最大の成功or失敗をテーマに開催します!
どんな話が聞けるか楽しみですね!
以下のURLからぜひエントリーください!
https://cyberagent.connpass.com/event/195409/
▼PTA
Twitter:https://twitter.com/PTA_CyberAgent
-Profile
株式会社CyberAgent メディア統括本部 Ameba事業本部 リードDiv プロダクトグループ エンジニア
寺沢 伸太