
こんにちは、Cyberagent group Infrastructure Unit の源波です。
今回はCA Tech JOBの制度を用いてインターンに参加して頂いた岩井さんからの寄稿記事です。
以下本文です。
はじめに
AI 事業本部 Strategic Infrastructure Agency(SIA) で 2020年10月に 1ヶ月間就業型インターンシップに参加させていただいた 近畿大学大学院 総合理工学研究科 M1 の岩井佑樹です.
今回 1ヶ月の就業型インターンシップで以下のことに取り組みました.
1. Kubeflow の機能調査
2. NVIDIA DGX A100 の機能調査
本記事では NVIDIA DGX A100 の 特に Multi Instance GPU(MIG) について紹介します.

MIG とは
NVIDIA 公式ページの説明には以下のようになっています.
以下を要約すると高いアイソレーションを確保しつつも GPU を最大 7分割し計算リソースを最大限活用できるようにする機能だと言えます.
マルチインスタンス GPU (MIG) は、各 NVIDIA A100 Tensor コア GPU の
パフォーマンスと価値を高めます。MIG では、A100 GPU を 7 個ものイン スタンスに分割し、それぞれに高帯域幅のメモリ、キャッシュ、コン ピューティング コアを割り当てたうえで完全に分離できます。管理者は、
すべてのジョブについてサービス品質 (QoS) が保証された適切なサイズ の GPU を提供し、アクセラレーテッド コンピューティング リソースの使
用率を最適化し、全ユーザーにリーチを拡張することで、規模を問わずあ らゆるワークロードに対応できます。
https://www.nvidia.com/ja-jp/technologies/multi-instance-gpu/
まずMIG を理解する上で以下の用語が非常に重要になってきます.
- Streaming MultiProcessor(SM): GPUで実際に計算命令を実行する部分になります.
- GPU メモリスライス: A100 GPU メモリ最小単位のことで,最小値は GPU リソース全体の 1/8 です.
- GPU SM スライス: A100 GPU の SM 最小単位の事で,最小値は GPU 全体で利用可能な SM の 1/7 です.
- GPU スライス: GPU メモリスライスと GPU SM スライスを1つづつ合わせた物のこと.
- GPU Instance(GI): GPU スライス と NVDEC などの GPU エンジンを組み合わせた物.
- Compute Instance(CI): GI を複数に分割した物で,GI と 1:1 で作成することも可能.
- single CI: 1つの CI で 属しているGI の計算リソースを占有する形
- multiple CIs: 1つの GI から SM のみを分割し,複数の CI を作成する形のことで, VRAM を GI 内で共有する.
- GPU Instance Profile: GI の構成プロファイルのことで,以下が予め用意されており選択することができます.
| Profile Name | Fraction of Memory | Fraction of SMs | Hardware Units |
Number of instances Available
|
| MIG 1g.5gb | 1/8 | 1/7 | 0 NVDECs | 7 |
| MIG 2g.10gb | 2/8 | 2/7 | 1 NVDECs | 3 |
| MIG 3g.20gb | 4/8 | 3/7 | 2 NVDECs | 2 |
| MIG 4g.20gb | 4/8 | 4/7 | 2 NVDECs | 1 |
| MIG 7g.40gb | 8/8 | 7/7 | 5 NVDECs | 1 |
MIG 有効時の GPU パフォーマンス
single CI モードで GIP 毎のパフォーマンス計測を行います.
ベンチマークには,Tensorflow 公式が提供している tf_cnn_benchmarks を用いて synthesis data(imagenet) を学習させた際の1秒間に学習できた画像枚数で評価しました.
動作環境
以下の環境でベンチマークを実行しました.
| 機材 | OS | docker | nvidia-docker | NVIDIA driver | base container image | tensorflow |
| DGX A100 | DGX OS 4.99.11 | 19.03.12 | 2.4.0 | 450.51.06 | nvcr.io/nvidia/cuda:11.0-cudnn8-devel-ubuntu18.04 |
tf-nightly-gpu 2.4.0.dev20201020
|
ベンチマーク設定
各モデル以下の設定でベンチマークを実行しました.また比較のため Tesla T4 も同様の条件で計測を行いました.バッチサイズは計測に使用した GIP のうち最も VRAM 容量の少ない物が最大まで VRAM を使い切れるサイズに設定しています.(ただし 2の累乗)
なお,評価には平均値を使用しています.
| モデル | バッチサイズ | 最適化関数 | 計算精度 | epochs | 試行回数 | 備考 |
| lenet | 1024 | sgd | FP32 | 1 | 5 | 全サイズ |
| alexnet | 64 | sgd | FP32 | 1 | 5 | 全サイズ |
| inception4 | 16 | sgd | FP32 | 1 | 5 | 1g.5gb除く |
| resnet50_v2 | 64 | sgd | FP32 | 1 | 5 | 1g.5gb除く |
| resnet152_v2 | 64 | sgd | FP32 | 1 | 5 |
1g.5gb & 2g.20gb除く
|
| vgg16 | 32 | sgd | FP32 | 1 | 5 | 1g.5gb除く |
| vgg19 | 128 | sgd | FP32 | 1 | 5 |
1g.5gb & 2g.20gb除く
|
結果
ベンチマーク結果は以下のようになりました.
意外だったのが 3g.20gb と 4g.20gb のスコアがあまり変わらない点です.
この結果から 4g.20gb を一つ作るよりも 3g.20gb を2つ作るのが良いことがわかります.
また,7g.40gb と NonMIG においても差が出てしまっており MIG のオーバーヘッドを表しているのではないかと考えられます.
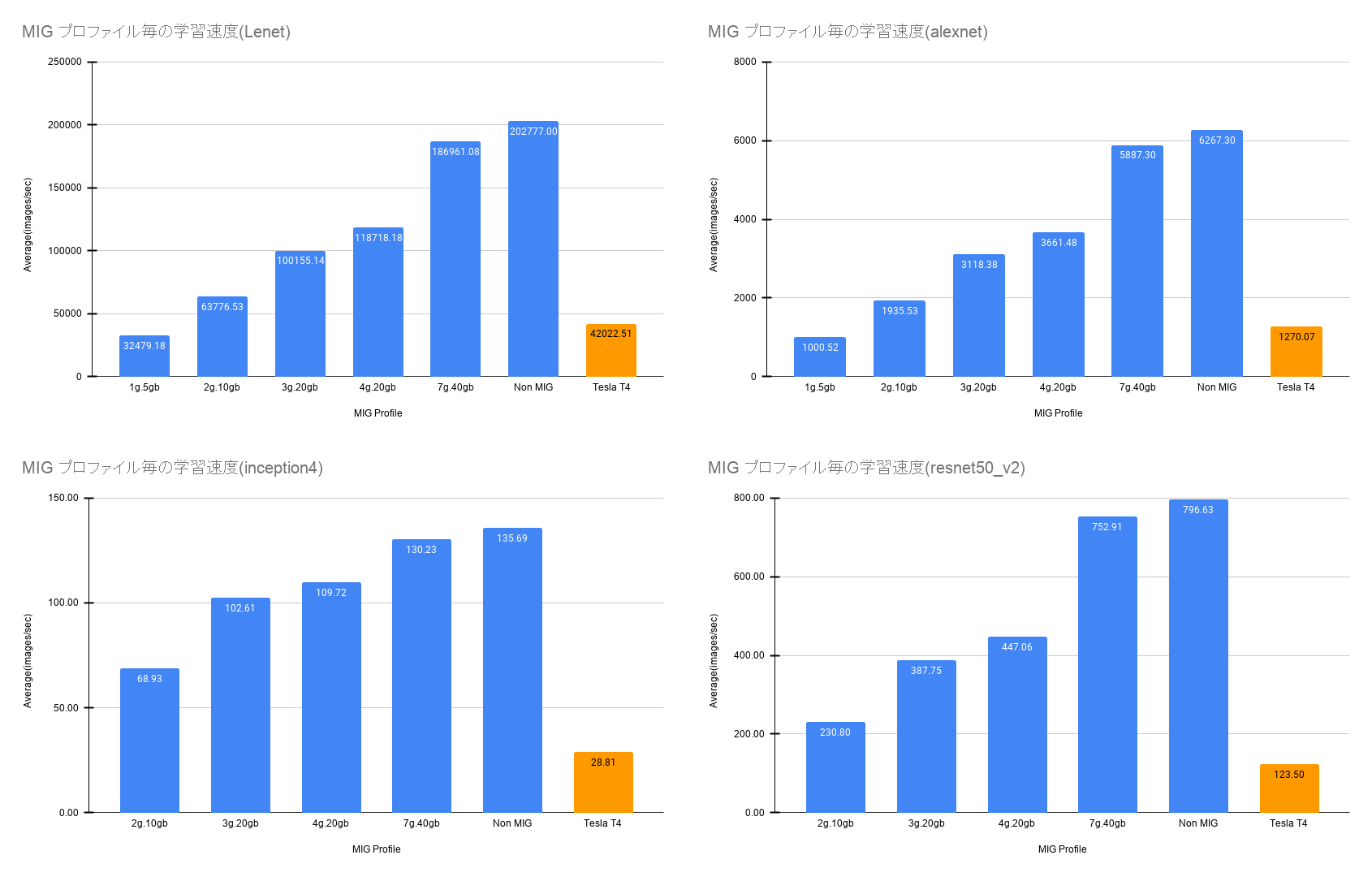
ベンチマーク結果1
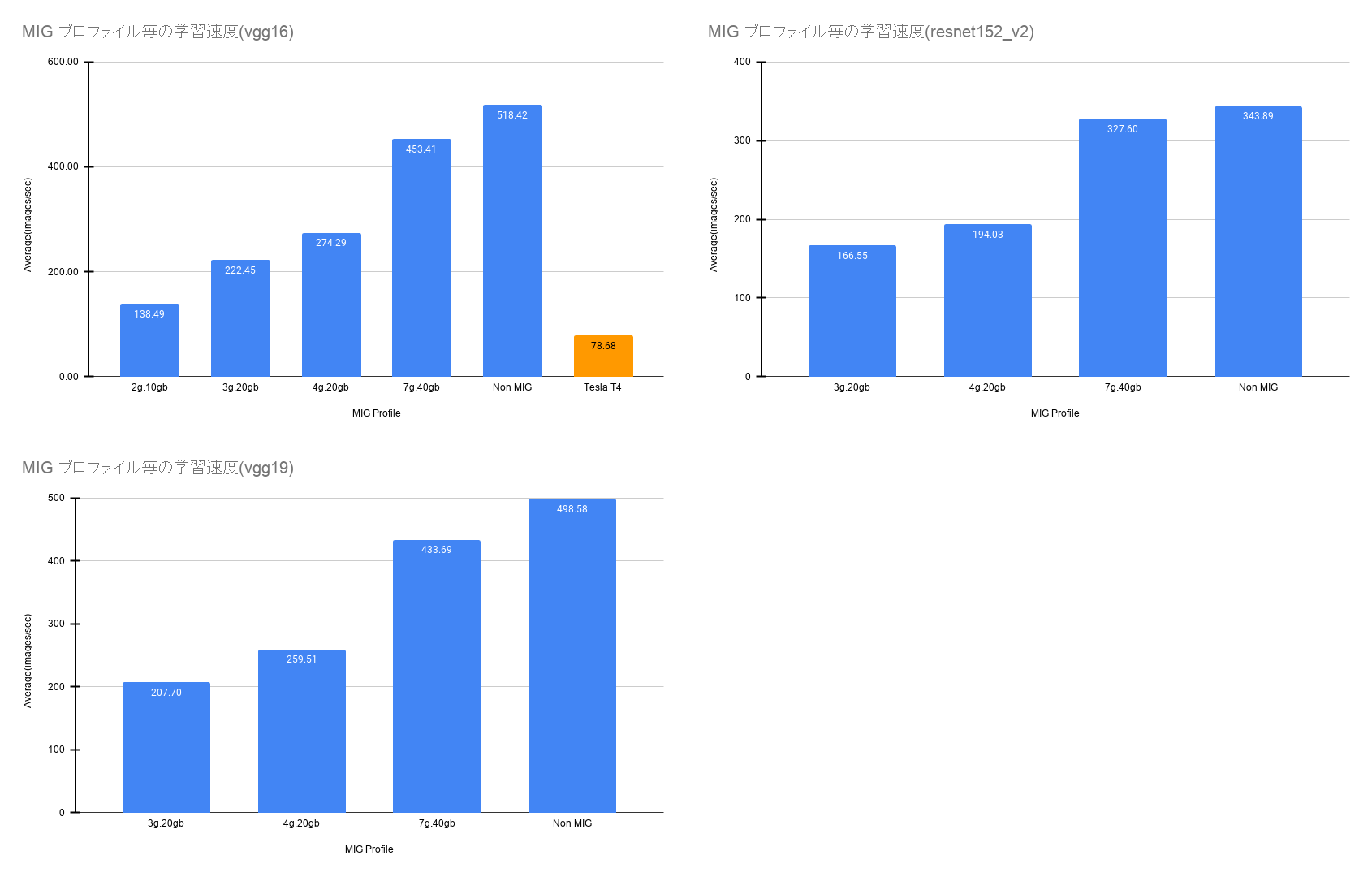
ベンチマーク結果2
備考
ベースイメージに nvcr.io/nvidia/cuda:11.0-cudnn8-devel-ubuntu18.04 を使用する場合,以下のバグに遭遇します.これの解決策として Issue でも提案されているコードを挿入するか, export TF_FORCE_GPU_ALLOW_GROWTH=true を設定することで回避可能です.
また,tf-nightly-gpu 2.4.0.dev20201021 以上の tensorflow-gpu を使用すると以下のバグに遭遇するので,動作と直接的に関係はありませんが,tf-nightly-gpu 2.4.0.dev20201020 の使用をお勧めします.
上記2つのエラーを回避する方法として NVIDIA が提供している最新の tensorflow-gpu 同梱コンテナイメージの nvcr.io/nvidia/tensorflow:20.10-tf2-py3 を使用することで上記2点のエラーを回避することができます.なお,nvcr.io/nvidia/tensorflow:20.09-tf2-py3 以前ではエラーを回避できないので気をつけてください.
Kubernetes と MIG
SIA では以下のように DGX A100 を Kubernetes Cluster の一部として取り込むことを目指しています.
そこで今回シングルノードクラスタで MIG を使用する検証を行いました. なお本記事では K8s の構築方法については記述しません. kubeadm の公式ドキュメントに従って構築してください.
MIG の構成
NVIDIA 公式ドキュメントに従って MIG デバイスを構築します. 今回は以下の構成で構築しました.
$ nvidia-smi -L
GPU 0: A100-SXM4-40GB (UUID: GPU-hoge-hoge)
MIG 3g.20gb Device 0: (UUID: MIG-GPU-hoge-hoge/1/0)
MIG 3g.20gb Device 1: (UUID: MIG-GPU-hoge-hoge/2/0)
GPU 1: A100-SXM4-40GB (UUID: GPU-hoge-hoge)
MIG 3g.20gb Device 0: (UUID: MIG-GPU-hoge-hoge/1/0)
MIG 3g.20gb Device 1: (UUID: MIG-GPU-hoge-hoge/2/0)
GPU 2: A100-SXM4-40GB (UUID: GPU-hoge-hoge)
MIG 3g.20gb Device 0: (UUID: MIG-GPU-hoge-hoge/1/0)
MIG 3g.20gb Device 1: (UUID: MIG-GPU-hoge-hoge/2/0)
GPU 3: A100-SXM4-40GB (UUID: GPU-hoge-hoge)
MIG 3g.20gb Device 0: (UUID: MIG-GPU-hoge-hoge/1/0)
MIG 3g.20gb Device 1: (UUID: MIG-GPU-hoge-hoge/2/0)
GPU 4: A100-SXM4-40GB (UUID: GPU-hoge-hoge)
MIG 3g.20gb Device 0: (UUID: MIG-GPU-hoge-hoge/1/0)
MIG 3g.20gb Device 1: (UUID: MIG-GPU-hoge-hoge/2/0)
GPU 5: A100-SXM4-40GB (UUID: GPU-hoge-hoge)
MIG 3g.20gb Device 0: (UUID: MIG-GPU-hoge-hoge/1/0)
MIG 3g.20gb Device 1: (UUID: MIG-GPU-hoge-hoge/2/0)
GPU 6: A100-SXM4-40GB (UUID: GPU-hoge-hoge)
MIG 3g.20gb Device 0: (UUID: MIG-GPU-hoge-hoge/1/0)
MIG 3g.20gb Device 1: (UUID: MIG-GPU-hoge-hoge/2/0)
GPU 7: A100-SXM4-40GB (UUID: GPU-hoge-hoge)
MIG 3g.20gb Device 0: (UUID: MIG-GPU-hoge-hoge/1/0)
MIG 3g.20gb Device 1: (UUID: MIG-GPU-hoge-hoge/2/0)
各コンポーネントのデプロイ
k8s-device-plugin と gpu-feature-discovery を MIG 対応させた上でデプロイします. Kubernetes において MIG のタイプは以下三種類から選択できますが, 今回は mixed を選択します.
1. none: なし(デフォルト)
2. sigle: 全 GPU 同じサイズの仮想 GPU を作成している場合
3. mixed: GPU 毎に バラバラのサイズ or 同じサイズの仮想 GPU を作成している場合
helm リポジトリを登録して各コンポーネントをデプロイします.
$ # helm リポジトリの登録
$ helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
$ helm repo add nvgfd https://nvidia.github.io/gpu-feature-discovery
$ helm repo update
$ # nvidia-device-plugin のデプロイ
$ helm install \
--version=0.7.0 \
--generate-name \
--set migStrategy=mixed \
nvdp/nvidia-device-plugin
$ # gpu-feature-discovery のデプロイ
$ helm install \
--version=0.2.1 \
--generate-name \
--set migStrategy=mixed \
nvgfd/gpu-feature-discovery
以下のように node へラベルが付与されている状態と MIG デバイスが認識されていることがわかります.
$ # node ラベルの確認
$ kubectl get node -o json | jq '.items[0].metadata.labels | with_entries(select(.key | startswith("nvidia.com")))'
{
"nvidia.com/gpu.product": "A100-SXM4-40GB",
"nvidia.com/mig-3g.21gb.count": "16",
"nvidia.com/mig-3g.21gb.engines.copy": "3",
"nvidia.com/mig-3g.21gb.engines.decoder": "2",
"nvidia.com/mig-3g.21gb.engines.encoder": "0",
"nvidia.com/mig-3g.21gb.engines.jpeg": "0",
"nvidia.com/mig-3g.21gb.engines.ofa": "0",
"nvidia.com/mig-3g.21gb.memory": "20096",
"nvidia.com/mig-3g.21gb.multiprocessors": "42",
"nvidia.com/mig-3g.21gb.slices.ci": "3",
"nvidia.com/mig-3g.21gb.slices.gi": "3",
"nvidia.com/mig.strategy": "mixed"
}
$ # MIG デバイス検出の確認
$ kubectl logs -n kube-system nvidia-device-plugin-1603994565-dcmhz
2020/10/29 18:06:59 Loading NVML
2020/10/29 18:06:59 Starting FS watcher.
2020/10/29 18:06:59 Starting OS watcher.
2020/10/29 18:06:59 Retreiving plugins.
2020/10/29 18:06:59 Starting GRPC server for 'nvidia.com/mig-3g.20gb'
2020/10/29 18:06:59 Starting to serve 'nvidia.com/mig-3g.20gb' on /var/lib/kubelet/device-plugins/nvidia-mig-3g.20gb.sock
2020/10/29 18:06:59 Registered device plugin for 'nvidia.com/mig-3g.20gb' with Kubelet
また,MIG デバイス構成を変更した場合は k8s-device-plugin Pod の再起動が必要になります.
Pod の起動
以下のようなサンプルマニフェストを作成し,デプロイします.
apiVersion: v1
kind: Pod
metadata:
name: gpu-example
spec:
containers:
- name: gpu-example
image: nvcr.io/nvidia/cuda:11.1-cudnn8-devel-ubuntu18.04
command:
- "nvidia-smi"
resources:
limits:
nvidia.com/mig-3g.20gb: 1
nodeSelector:
nvidia.com/gpu.product: A100-SXM4-40GB
以下の様にPod に MIG デバイスがマウントされてコンテナ内から見えることがわかります.
$ kubectl apply -f simple-mig-pod.yaml
$ kubectl logs gpu-example
Thu Oct 29 20:11:56 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-SXM4-40GB On | 00000000:0F:00.0 Off | On |
| N/A 24C P0 42W / 400W | N/A | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 2 0 0 | 11MiB / 20096MiB | 42 0 | 3 0 2 0 0 |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Golang と MIG
Golang から MIG を操作することが可能になれば K8s のカスタムコントローラなどの作成が可能になります.
NVIDIA では GPU 用に NVML という C言語ライブラリが用意されており,それを Golang で使用できる様になっている物が以下の NVIDIA が提供しているコンテナ用モニタリングツールのリポジトリにあります.
https://github.com/NVIDIA/gpu-monitoring-tools/tree/master/bindings/go/nvml
以下の様にライブラリを使用することで MIG の操作が可能になります.
func main() {
nvml.Init()
defer nvml.Shutdown()
device, err := nvml.NewDevice(uint(0))
if err != nil {
log.Panicln("Error getting devices:", err)
}
// set gpu instance profile id 19
nineteenGIP, err := device.GetGPUInstanceProfileInfo(0)
if err != nil {
log.Panicln("Error getting 19GIP: ", err)
}
// create gpu instance to use gpu instance profile 19
_, err = device.CreateGPUInstance(&nineteenGIP)
if err != nil {
log.Panicln("Error create GI to use 19: ", err)
}
fmt.Printf("create GI to use profile 19\n")
migDevice, err := device.GetMigDeviceHandleByIndex(0)
if err != nil {
log.Panicln("Error getting mig device handle by index:", err)
}
isMigDevice, err := migDevice.IsMigDeviceHandle()
if err != nil {
log.Panicln("Error getting mig device handle:", err)
}
fmt.Println("mig device handle: ", isMigDevice)
// get gpu instance id
gpuInstanceId, err := migDevice.GetGPUInstanceId()
if err != nil {
log.Panicln("Error getting GI ID: ", err)
}
fmt.Printf("get gpu instance id that mig device is 0 in Physical GPU 0: %v\n", gpuInstanceId)
}
注意点として GPU Instance Profile ID を指定方法が異なる点です.具体的には GIP 19 の時は 0 を GIP 14 の時には 1 を指定することで呼び出すことが可能です.
参考資料
- MIG とは
- https://docs.nvidia.com/datacenter/tesla/mig-user-guide/
- Kubernetes と MIG
- https://docs.google.com/document/d/1bshSIcWNYRZGfywgwRHa07C0qRyOYKxWYxClbeJM-WM/edit?pli=1
- https://docs.google.com/document/d/1mdgMQ8g7WmaI_XVVRrCvHPFPOMCm5LQD5JefgAh6N8g/edit?pli=1#
- Golang と MIG
- https://pkg.go.dev/github.com/NVIDIA/gpu-monitoring-tools/bindings/go/nvml
- https://docs.nvidia.com/deploy/nvml-api/group__nvmlMultiInstanceGPU.html#group__nvmlMultiInstanceGPU
おわりに
今回のインターンではなかなか触ることができない NVIDIA DGX A100 を触ることができ,MIG の検証を行うことができました.本記事が MIG を理解することの助けになれば幸いです.
また,本インターンではフルリモートという難しい状況の中トレーナーの方や SIA の方々,人事の方々のサポートにより最後まで成し遂げることができました.この場を借りて深くお礼申し上げます.