
広告配信プロダクトのDWHにSnowflakeを採用しました
この記事は CyberAgent Developers Advent Calendar 2020 1日目 と Snowflake Advent Calendar 2020 1日目 の記事です。
AI事業本部 Dynalystで開発責任者をしている黒崎( @kuro_m88 )です。 CyberAgent Developers Advent Calendarは入社以来書き続けて6年目になりました。今年は弊社公式で開催されなかったため、有志で立ち上げてみました。 今年はSnowflakeというクラウドデータプラットフォームを自プロダクトで採用した話をさせていただこうと思います。
Snowflakeとは?
クラウド上で構築されているSaaSのデータプラットフォームです。大量のデータを取り込んだり、保管したり、それらのデータを加工したり分析したりするために使われるものです。 比較対象としてはAmazon Redshift, Amazon Athena, Google BigQueryなどが挙げられると思います。ただし、それぞれのサービスは周辺サービスとの統合など独自性があり、できることのカバー範囲は違ったりします。
AWS, GCP, Azureのいくつかのリージョンで動いており、顧客はクラウドとリージョンの組み合わせを選んで利用することができます。
Snowflakeを初めて知った方向けにSnowflakeのアーキテクチャの概要だけ紹介します。
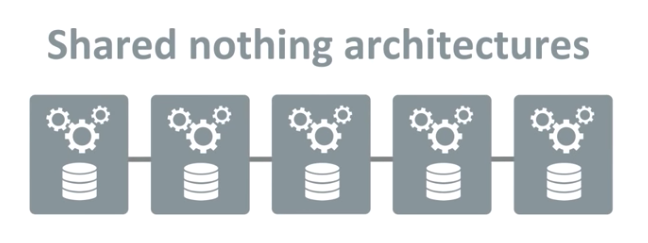
Shared Nothing Architecture
データに対して何かしらの処理をする、コンピュートノードはデータを保有していません。(shared nothing) そのため、コンピュートノード計算をすることしかできず、データは外部から取得する必要があります。
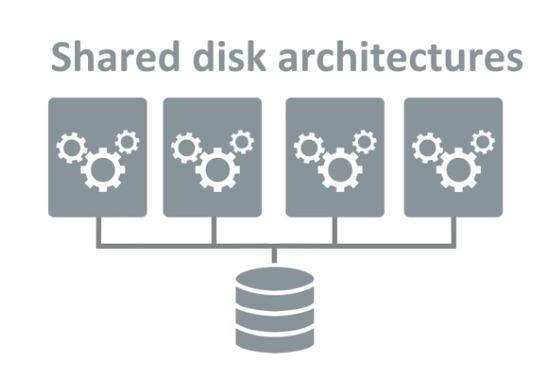
Shared Disk Architecture
コンピュートノードがデータを保有しない代わりに、外部にストレージがあり、そのストレージにコンピュートノードがアクセスすることでデータを処理します。 コンピュートとストレージが分離されているおかげで、コンピュートノードの台数を増やして処理能力をスケールさせるときにストレージのコピーなどが発生せず、処理の負荷に応じて柔軟に使用するコンピュートリソースのサイズを調整することができます。ストレージは従量課金で、構造化データと半構造化データ(JSON, Avroなど)をサポートしています。
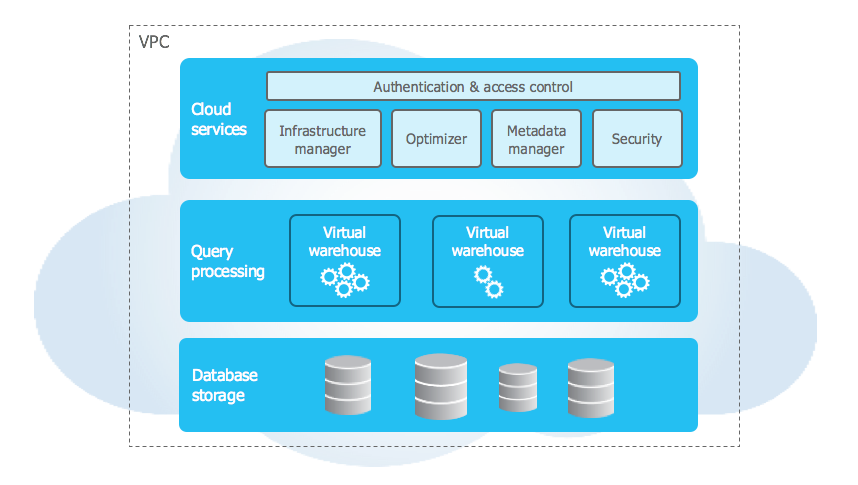
Virtual Warehouse
データに対して処理をする(SQLなどを実行する)クラスタの単位です。 XS, S, M, L, XL, 2XL, 4XLからサイズを選択します。それぞれのサイズは何台のサーバで構成されているのかなど、具体的なスペックに関しては明示されていません。起動時間単位の課金で、サイズによって時間単価が変わります。 クエリが流れていないと自動停止し、クエリが流れてきたら自動で起動させることができ、コストの節約ができます。起動時間に関して明示されてはいませんが、本番で利用している環境ではクエリを投げてから1秒もかからず起動しているように見えます。 本当に1秒以内に計算用のサーバが起動するとは思えないので、裏側には起動した状態でスタンバイしているSnowflake全体で共有のリソースプールがあり、ユーザからのリクエストが来たら動的にアサインしているのかな?と想像しています。
DynalystでのDWHの使い方
アドホックな分析用途
主にデータサイエンティストやバックエンドエンジニアが分析用途で利用しています。 後述するSnowflakeのweb UIでクエリしたり、JetBrainsのDataGripを使ったり、Jupyter上のpythonからアクセスしたりしている人が多いです。
機械学習バッチのデータソース
Dynalystでは広告のクリック率や最適な入札額推定するために機械学習を用いています。 各種機械学習モデルの学習時の条件に合うデータを抽出するためのデータソースとして利用しています。
Tableau(BIツール)上での分析や可視化
Dynalystでは分析や定常的にモニタリングしたい指標やそれらの可視化のためにTableauを利用していて、TableauはSnowflakeとインテグレーションされているのでTableauのデータソースとしても使っています。

Snowflakeの便利なところ
Snowflakeは半年くらい前から注目していて、実際に触ってみた結果よさそうだったので採用を決定しました。10月から本番利用しています。
検証してみてよかった機能をいくつか紹介します。
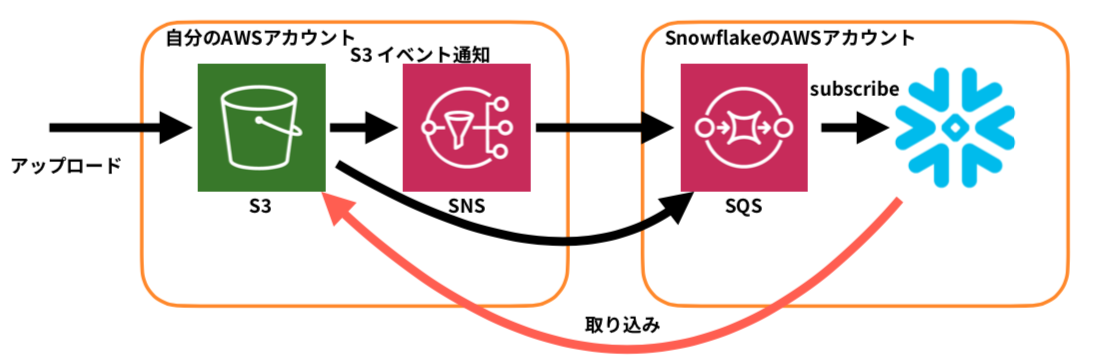
Snowpipe
S3等にデータ(オブジェクト)をアップロードするとオブジェクトのアップロードイベントをきっかけにデータを自動でSnowflakeに取り込んでくれるしくみです。 ETLを自前実装する必要がなく、1日あたり5TBくらいの流量でも、ファイルをアップロードしてから数分でSnowflakeのストレージに格納され、すぐにクエリできるようになり非常に便利です。
Task
定期実行したいようなクエリ(定時集計やテーブルのメンテナンス)がSnowflakeで完結します。 今までは外部にジョブスケジューラを立ててそこからクエリを流していましたが、簡単なものであればTaskを設定するだけで十分になりました。
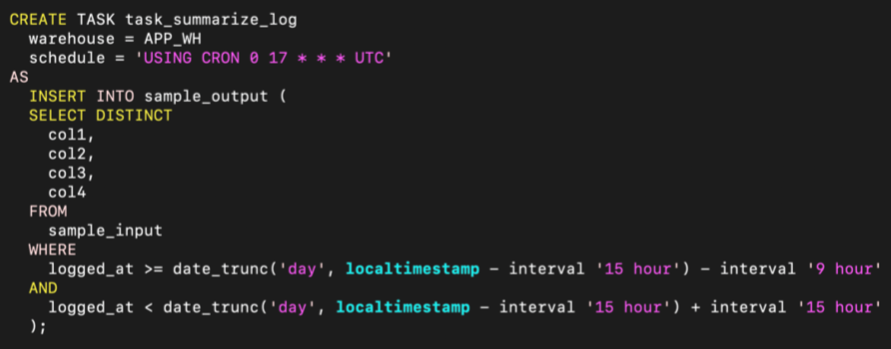
ログのローテーションのしやすさ
一定期間より古いログを削除したい場合に、追記型のDBだとdeleteをしてもストレージが開放されず、新しいテーブルにselect insertをして、新旧テーブルを置換する必要があることが多いですが、Snowflakeの場合はdeleteをするとストレージが開放されます。 ストレージ使用量が10TBのテーブルに対して2TB分のデータの削除をしましたが、クエリは数秒で完了しました。
External Tables
Snowflakeのストレージに取り込まずに、S3等にあるオブジェクトをテーブルに見立ててクエリする機能です。通常のテーブルに比べればクエリ速度は遅いですが、少量のデータや一時的なファイルに対してクエリするにはExternal Tablesで十分かと思います。 カラム定義やパーティションの定義に柔軟性があり、扱いやすかったです。

シングルサインオン
社内のID基盤とSAML認証により連携することで、パスワードレスなログイン環境(Macの指紋認証など)が作れました。 社内のID基盤のAPIと連携させ、部署異動時に自動で権限が付与されたり、退職時に自動でアカウントが停止されるようになったため、アカウントの棚卸しが不要になりました。
Work Sheets
Web UIからクエリが実行できます。
実行計画もわかりやすいです。

Snowsight
preview版のweb UIですが、クエリの補完が充実しています。また、クエリ結果を元に簡単なグラフやダッシュボードを作成し、他の人に共有することもでき非常に便利です。
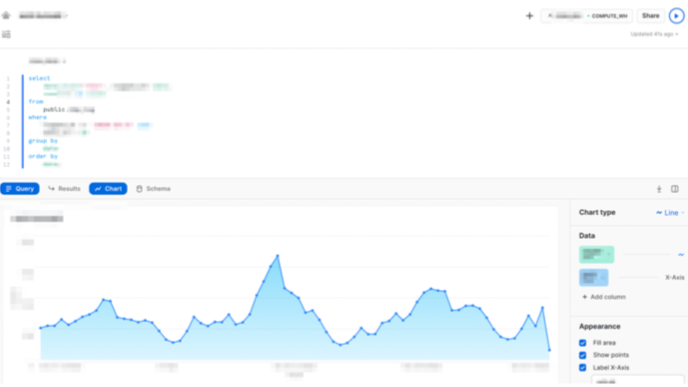
既存DWH(Amazon Redshift)からSnowflakeへの移行にあたり検証したこと
Dynalystでは元々Amazon RedhisftをDWHに使っていたのですが、Snowflakeへ移行するにあたり、今までできていたことができなくならないかや互換性の部分など、いくつか注意して検証していた部分があるので紹介します。
クエリ性能
普段分析で使うようなクエリが許容範囲の性能かどうかをみました。 日常的に使う重めのクエリは1-2分以内で応答してほしかったのでそこを重点的に検証しました。 1ヶ月分のデータをインポートして性能を計測し、3ヶ月分, 6ヶ月分とデータ量を増やしていき、性能が大幅に悪化しないことを確認しました。ウェアハウスのサイズを2倍にすると多くのケースでクエリ時間が約半分になることが確認でき、性能やスケーラビリティに問題はないことが確認できました。
DWHの安定性
クエリが集中したり、重いクエリが走っているときにクエリ時間が極端に遅くなるのは利用者にとってストレスなので避けたいです。この点Snowflakeは用途ごとにウェアハウスが作成でき、コンピュートとストレージが分離されているおかげで負荷の影響は受けなくなりました。
コスト
Snowflakeは従量課金制なのでクエリの頻度や量に注意しなければいけません。 今までは負荷分散のためにクエリが走る時間をばらけさせていたのですが、Snowflakeの場合は逆にクエリが走る時間を集中させることでウェアハウスの利用効率を上げ、ウェアハウスの起動時間が短くなるように調整しました。また、クエリの頻度を見直して、不必要に高頻度に実行されていたクエリは棚卸しすることでコストを最適化しました。
データ転送料
多くのパブリッククラウドはインバウンド(内向け)トラフィックは無料、アウトバウンド(外向け)トラフィックは有料です。大量のデータを扱うプロダクトにとってデータ転送料は問題になりやすいです。 DynalystはAWSの東京リージョンをインフラに利用していますが、SnowflakeもAWSの東京リージョンを選択することで、同一リージョン内の通信になりデータ転送料の課金は発生していません。
運用のしやすさ
クラスタのバージョンアップ作業などが不要で、基本的にはダウンタイムはなく、実行中のクエリに影響がないようにローリングアップデートされるようです。 また、ほぼすべての設定がSQLから操作でき、統一感もあってよかったです。
SnowflakeはMySQLやPostgreSQLといった普及しているプロトコルではなく、独自のプロトコルで通信するため、Snowflakeに対応していなければ直接通信できないのはデメリットだと思います。 ただし、その点をカバーすべくSnowflakeは各種アダプタやライブラリ、インテグレーションが充実しているので、Dynalystでは問題にはなりませんでした。
セキュリティ面
Snowflakeはインターネットからアクセスされる前提ですべての外部との通信は認証, 認可をした上で暗号化されています。そのためVPNを経由したりせずにどこからでも安全にアクセスすることができるようになり、いわゆる「ゼロトラスト」なDWHになりました。 安全とはいえプロダクトのセキュリティ要件で許容できない場合は通信先のIPアドレス制限やAWS Private Linkによるインターネットを経由しない通信も可能です。
クエリの互換性
自前実装しているアプリケーションであれば各種言語向けにSnowflakeが提供しているドライバーに差し替えれば接続は切り替えられるはずです。 Dynalystの場合はJDBCドライバを差し替えるだけで無事接続は切り替わりました。
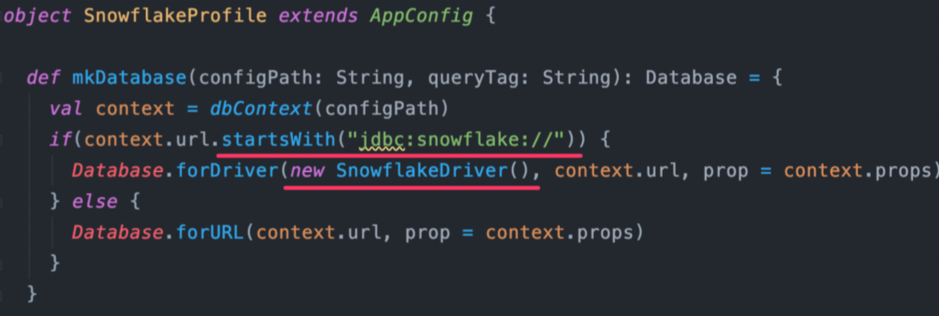
ただし、クエリ結果の挙動が変わったり、関数名が違ったり、互換性の面で考慮が必要だったりするので、必ず移行前と移行後でクエリ結果が変わらないかすべてのクエリについて検証する必要はあります。 いくつか遭遇した例としては、
- 整数どうしの除算が小数で返る
- 1 / 100 が 0 ではなく、 0.01 になる
- 整数も小数もnumber型で統一されているためこうなると思われる
- floor関数で切り落とすことで互換性を維持
- random() 関数が0〜1の範囲外の値を返す
- uniform(0.0, 1.0, random())で0〜1の範囲に丸める
- snowsql(cli)にて
- empty_for_null_in_tsv=trueを指定しないとnullが空文字として出力されない
- exit_on_error=trueを指定しないとクエリ失敗時にコマンドの終了ステータスが成功になる
- Tableauにて
- Snowflakeのint型がTableauだと小数点つきで解釈されてしまう
- 100, 200などが100.0, 200.0などになりMySQLなどとJOINできなくなる
- Snowflakeのint型はnumber(38, 0)であり、最大桁数が非常に大きいためTableauが整数として扱えない模様
- Snowflakeのテーブル定義のintをすべてnumber(18, 0)に置換することで対処
- number(18, 0)は百京以上の数字なので、実運用上問題になりませんでした
- Snowflakeのint型がTableauだと小数点つきで解釈されてしまう
今後挑戦したいこと
データレイクとしてのSnowflake
Dynalystでは現在Snowflakeのストレージを100TB程度利用しています。毎日5TBくらいログが溜まっていて、それらはAmazon S3に保存されています。 永遠に保存しつづけるとストレージコストが膨大になってしまうのでAmazon S3は1PB前後になるように古いデータから削除することでストレージコストを維持しています。 それでもS3とSnowflake両方にログを格納しているため、ストレージコストが2重になっている部分があります。月日が経過して安定稼働する実績ができ、S3上のログを直接参照することがなくなった時にはSnowflakeをすべてのデータソースとして位置づける(データレイクにする)ことも検討したいと思います。
少し話は逸れますが、Snowflakeは従量課金なのでDynalystのように比較的ストレージ使用量が多めなプロダクトでなくても(数GB/月など)コスト効率が悪くなることはなく、データレイクとして採用を検討してもよいと思います。
Apache SparkのSnowflake Driver
DynalystではApache Sparkというクラスタコンピューティングフレームワークを使ってCPU 256コア, メモリ 512GB程度のサイズのクラスタでレポーティングの集計を行っていますが、データソースとしてSparkのSnowflake Driverを使うことでデータ抽出部分の処理をSnowflakeにプッシュダウンすることができ、自前実装で複雑な計算をしたい部分とSnowflakeでデータの前処理をする部分といいとこどりができないか検討中です。
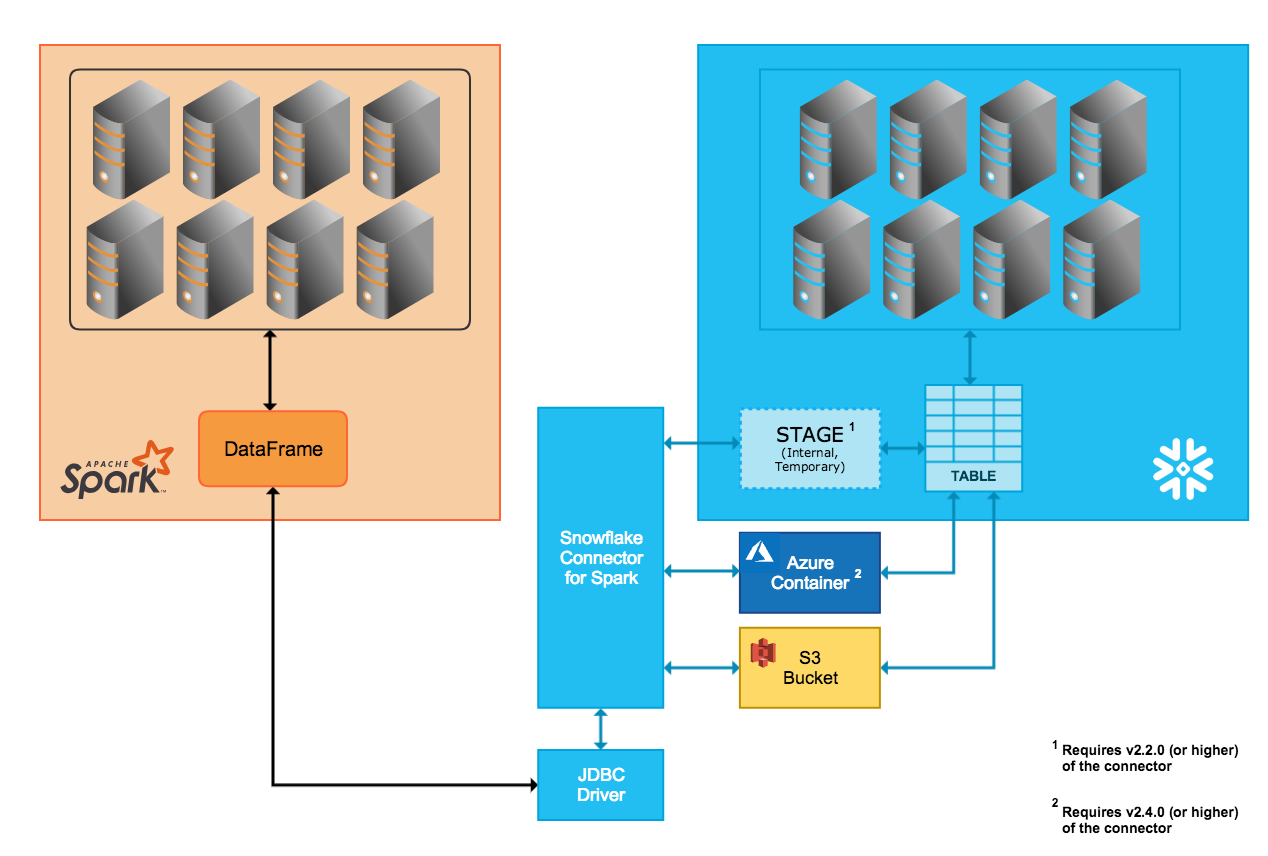
Snowpark
最近発表された機能でまだ詳細については公開されていませんが、Snowflake上でApache Sparkが動くようで、Sparkクラスタの管理は不要のようです。 こちらについてもpreview環境がもし手に入れば検討して導入の余地があるのか判断したいなと考えています。 ( https://www.snowflake.com/news/snowflake-announces-new-features-to-mobilize-the-worlds-data-in-the-data-cloud/ )
まとめ
DynalystでSnowflakeというクラウドデータプラットフォームを採用したことについて紹介させていただきました。 明日のCyberAgent Developers Advent Calendarはなんと…埋まっていません!日付が変わっても埋まっていなかったら明日も記事を書こうと思います。