
人事の小澤です。今回は技術本部サービスファシリティグループで1ヶ月間インターン生として参加してくれた黒岩さんの記事をご紹介させていただきます。
はじめに
技術本部サービスファシリティグループの黒岩です。1ヶ月間インターン生として勤務させて頂きました。私はインターンの業務として、Dockerのマルチホストネットワークについて調査を行いました。この記事ではその調査結果について報告します。
具体的には、DockerオーバーレイネットワークとCalicoの比較を行いました。結果として、使い勝手の良さとパフォーマンスはCalicoに軍配が上がりましたが、導入には2つの課題が見つかりました。第一に、Calicoによってルータのルーティングテーブルが肥大化します。第二に、Calicoを用いてコンテナでL3DSRを構成する場合は、Calicoにパッチを当てる必要があります。
Dockerのマルチホストネットワークとは
Dockerを大規模に運用する際、多数のコンテナが相互に通信することが想定されます。例えば、ウェブサーバとDBサーバの通信です。
同じサーバ上にコンテナが配置されていれば話は簡単です。しかし実運用では、複数の異なるサーバ上にコンテナが分散して配置される状況が考えられます。
このような状況においては、マルチホストネットワークを利用することで、異なるサーバ上のコンテナ同士は相互に通信することができます。
次項で説明するように、コンテナ同士の通信にはサーバでのNAPTを用いることもできます。しかし、サーバでNAPTを行うとコンテナ、サーバ、ポートの対応関係が膨大になり管理には煩雑です。一方でマルチホストネットワークであれば、管理対象はコンテナのIPアドレスのみです。また、異なるサーバ上の複数のコンテナをグループでまとめることもできます。
調査した技術について
通常のDockerネットワーク
通常のDockerネットワークは、サーバ毎に独立しています。下の図のように、サーバ上のコンテナはdocker0という仮想ブリッジに接続されています。同じサーバ上におけるコンテナ同士の通信は、docker0を経由して行われます。
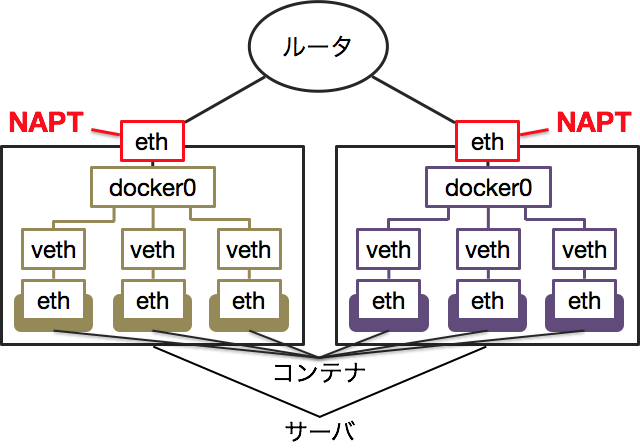
コンテナがサーバ外へ通信を行う場合はNAPTが行われます。コンテナからサーバの外部へ向かうパケットがサーバを通過する際、送信元のIPアドレスとポートがサーバのIPアドレスとポートへ変換されます。反対に外部からコンテナへパケットを送信する際は、サーバのIPアドレスとポートを送信先にすれば、サーバを通過する際にコンテナのIPアドレスとポートへ変換されます。
NAPTを行うのは、ルータからコンテナへの経路が存在しないためです。一方、コンテナのホストとなるサーバには、コンテナと直接接続されているため経路があります。
下の図はNAPTを用いた通信の流れです。サーバA上のコンテナ1のX番ポートからサーバB上のコンテナ2のW番ポートへ通信を行います。この時、コンテナ2のポートWをサーバBのポートYへNAPTしています。
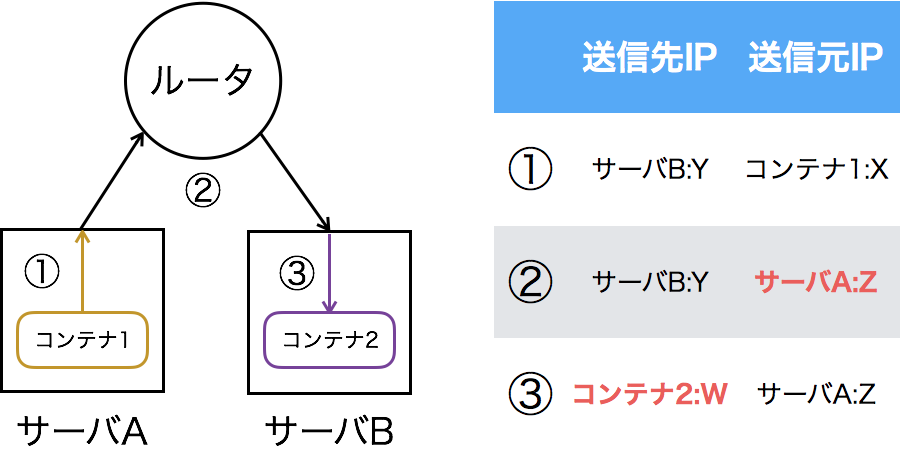
この方法で異なるサーバ上のコンテナ同士が通信することもできます。しかしサーバやコンテナが増えると、コンテナ、サーバ、ポートの対応関係が膨大になります。また、コンテナを複数のグループに分けて管理することも困難です。
Dockerオーバーレイネットワーク
Dockerオーバーレイネットワークはマルチホストネットワークを実現する技術の1つです。異なるサーバ上の複数のコンテナを同じネットワークに配置することができます。また、同じサーバ上でも複数のコンテナを異なるネットワークに配置することが可能です。この時、所属するネットワークが異なるコンテナは異なるブリッジに接続されます。
図では赤のコンテナと青のコンテナが異なるネットワークに配置されています。
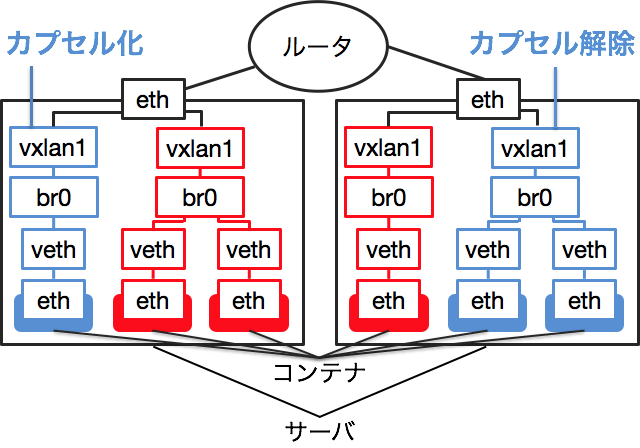
通常のDockerネットワークで説明したように、ルータからコンテナへの経路はありません。そこで、VXLANという技術を利用します。
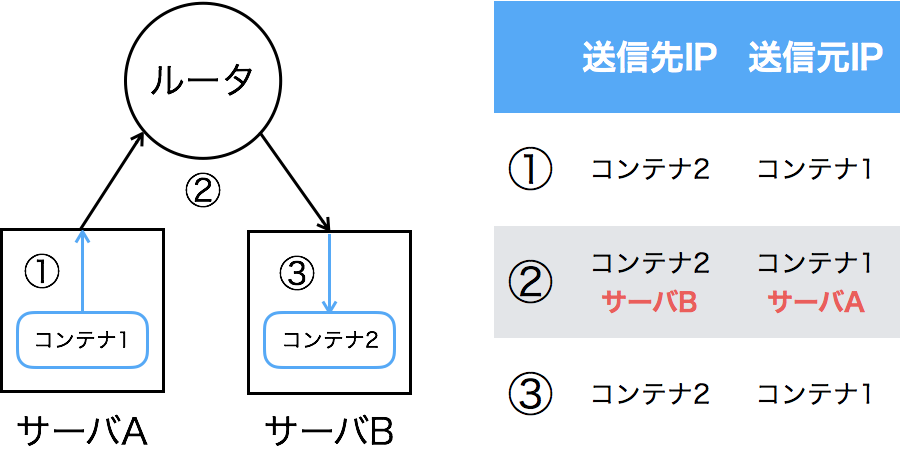
下の図はDockerオーバーレイネットワークにおける通信の流れです。コンテナ1からコンテナ2へのパケットがサーバから送出されるとき、送信元がサーバA、送信先がサーバBのUDPパケットとなるようにカプセル化されます。ルータはサーバBへのルーティング情報を持っているので、サーバBまでパケットを転送することが可能です。パケットがサーバBに届くと、カプセル化が解除されてコンテナ2へ到達します。なお、パケットのカプセル化と解除は、vxlan1というインターフェースで行われています。
コンテナから見れば、同じサーバ上の他のコンテナに通信するのとなんら変わりはありません。L2ネットワークとして通信可能です。
設定方法は公式ドキュメントを参考にしてください。有志による日本語訳もあります。
Calico
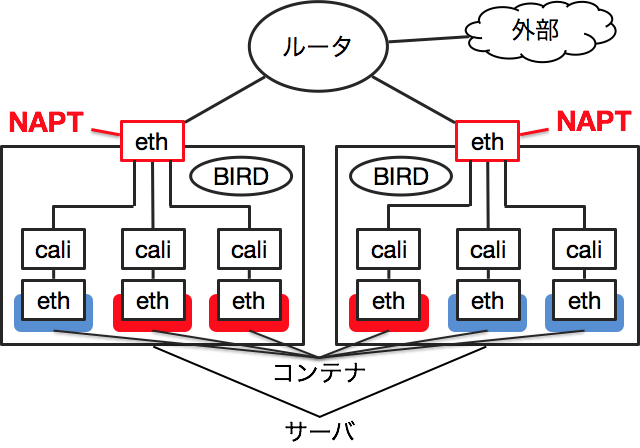
Calicoとは、L3のルーティングを用いてコンテナのネットワークを管理する技術です。Calicoの仕組みはシンプルで、ただのL3ネットワークです。各コンテナには/32でIPアドレスを割り当てます。コンテナはサーバ側のcaliで始まる名前のデバイスとvethのペアで接続されます。
サーバはルータとBGPのpeerを張ってルーティング情報を交換します。これにより、各サーバからコンテナへのルーティング情報がルータと他のサーバに伝わり、コンテナへのパケットが適切にルーティングされます。
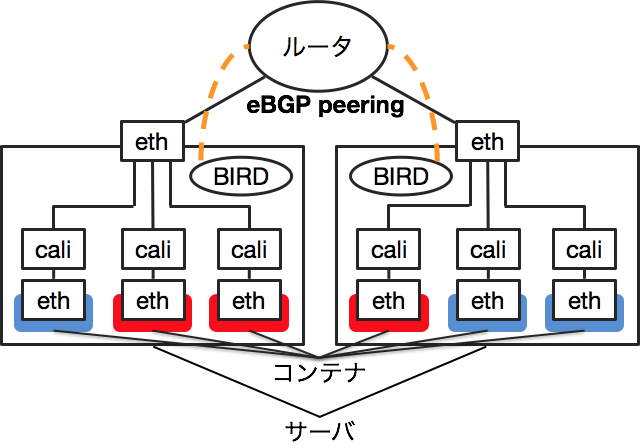
CalicoはBGPのpeeringにBIRDというルーティングデーモンを使用します。上の図ではeBGPでpeeringしていますが、iBGPを使用することも可能です。
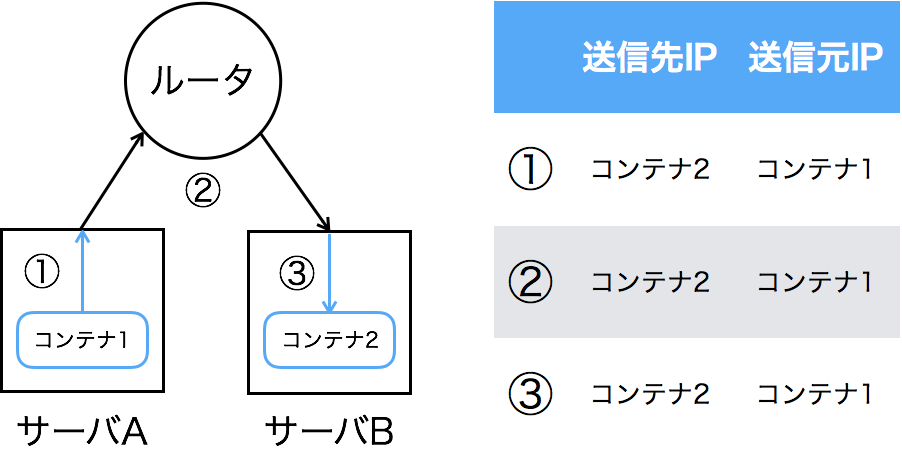
Calicoが行うのは単なるIPルーティングです。下の図はCalicoでの通信の流れです。図からわかるように、IPアドレスやポートの変換、カプセル化は行われません。
また、コンテナをprofileというグループでまとめることができます。profileはAWSのセキュリティグループのように、他のprofileやネットワークとの通信をルールで制御します。これによって、コンテナのネットワークを分割することができます。
設定方法は公式ドキュメントを参考にしてください。Docker Swarmやdocker networkと組み合わせることもできるようです。
それぞれの機能について
以下に挙げる機能について、DockerオーバーレイネットワークとCalicoの比較を行いました。
- 外部との通信をどのように実現するか
- マルチキャストは利用可能か
- スループット
- L3DSRは利用可能か
外部との通信をどのように実現するか
例えば、コンテナをWebサーバとして公開する場合、コンテナが外部と通信可能である必要があります。
Dockerオーバーレイネットワーク
Dockerオーバーレイネットワークではコンテナ同士の通信しか想定されていません。
そのためDockerはコンテナと外部を通信させるために、Docker Gateway Bridgeという別のネットワークを用意しています。これは通常のDockerネットワークと同様にサーバ毎に1つ存在し、NAPTを使って外部と通信可能です。ただし、同じサーバ上のコンテナに通信することはiptablesで禁止されています。
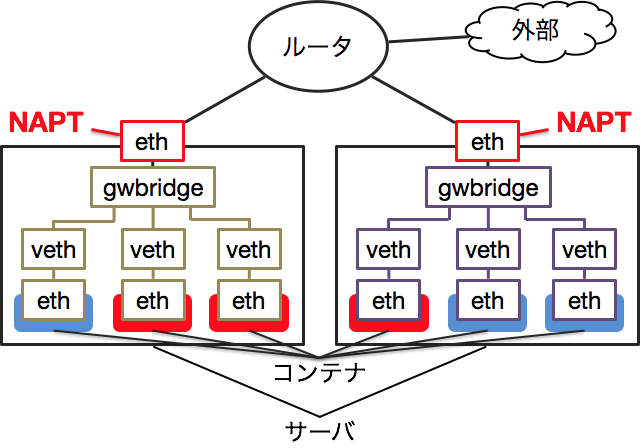
Calico
Calicoは単なるIPルーティングなので、IPアドレスを割り当てたサーバをインターネットに公開するのと同様です。Global IPを割り当てるか、Private IPを割り当てて外部との境界になるルータでNAPTします。
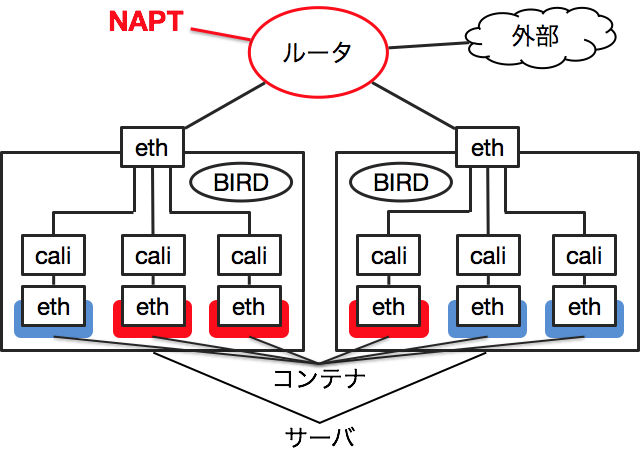
Calicoの機能を使って、サーバでNAPTすることもできます。この場合は
$ calicoctl pool add 192.168.0.0/16 --nat-outgoing
のように、コンテナに割り当てるIPのプールを確保する際に–nat-outgoingオプションをつければSNATすることが可能です。DNATをする場合は、docker runの-pオプションを使うのではなく、iptablesで設定を行う必要があります。
マルチキャストは利用可能か
一部のミドルウェアでは冗長化等にマルチキャストを利用する場合があるため、その利用可否を調査しました。
Dockerオーバーレイネットワーク
マルチキャストについて、Dockerのネットワーク管理を実装しているlibnetworkのGitHubリポジトリにissueが立てられています。
こちらによると、Dockerオーバーレイネットワークでのマルチキャストは現時点では実装されていません。今後実装される可能性はあります。
Calico
CalicoはL3のルーティングを使用します。マルチキャストをルーティングするにはIGMPが必要です。しかし、Calicoのルーティングに使われるBIRDはIGMPをサポートしていません。よって、Calicoのネットワークにおいてもマルチキャストは利用不可能です。
スループット
物理サーバ2台をルータの両端に接続し、それぞれにKVMで仮想マシンを作成し、iPerf3でスループットを計測しました。以下の3項目について比較を実施しました。
- KVM同士の通信
- KVM上のDockerオーバーレイネットワークに属するコンテナ同士の通信
- KVM上のCalicoコンテナ同士の通信
物理サーバ及びKVMのOSはCentOS7で、コンテナはnginxのイメージで起動しました。ルータはCisco ASR 1001で、サーバとの接続には1Gbpsのインターフェースを使用しました。
結果は以下のグラフのようになっています。CalicoはiBGPでもeBGPでも差がなかったため、eBGPの結果を用いました。
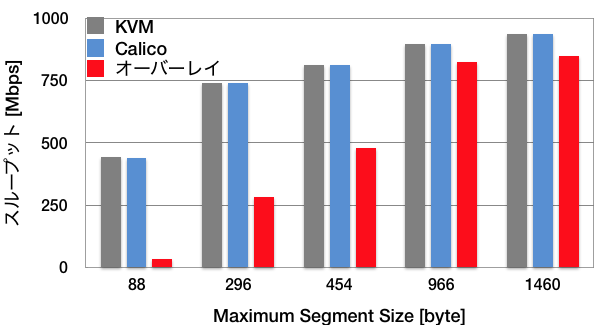
上記の結果より、KVM同士の通信とCalicoコンテナ同士の通信においては差がないことがわかります。
一方で、Dockerオーバーレイネットワークでの通信はややオーバーヘッドが大きいです。これはカプセル化と解除の処理があるためだと考えられます。
L3DSRは利用可能か
DSRとはDirect Server Returnの事で、ロードバランサを用いた構成の一種です。負荷低減やサーバ配置の自由度を高めるために用いられます。現在、サイバーエージェントでもDSRの一種であるL3DSRを利用しています。そのため、マルチホストネットワークでもL3DSRが可能なのかを検証しました。
今回は、ロードバランサのVIPの背後に配置したサーバのループバックインターフェースに、VIPと同じIPアドレスを割り当てました。それから、サーバでIPIPトンネリングを有効にすることでL3DSRを構成しました。
L3DSRでの通信の流れは下の図のようになっています。ロードバランサは、クライアントからパケットが到達するとIPIPでカプセル化し、パケットをサーバに転送します。サーバでパケットのカプセル化を解除すると、その送信先はサーバのループバックインターフェースのIPアドレスに一致します。サーバはパケットを受け取り、そのままクライアントへ返りのパケットを送信します。返りのパケットはロードバランサを通りません。

今回はこちらのガイドに従ってBIG-IPにL3DSRを設定しました。なお、BIG-IPの開発元であるF5社はL3DSRをlayer 3 npathと呼称しています。
Dockerオーバーレイネットワーク
DockerオーバーレイネットワークのコンテナでL3DSRを構成する際、コンテナをロードバランサと通信させるために、サーバにNAPTします。したがって、ループバックインターフェース等の設定はサーバに対して行います。
L3DSRでは送信先IPアドレスだけではなく送信先ポートの変換も行われません。ロードバランサのVIPと背後に配置するサーバとは、外部からのパケットを受け付けるポートが一致していなければなりません。1つのポートには1つのコンテナしか割り当てられないので、1つのVIPの背後に配置できるコンテナはサーバ1台あたり1つだけになります。つまり、同じサーバ上にある複数のコンテナにパケットをロードバランシングすることはできません。
Calico
CalicoはNAPTではなくIPルーティングです。そのため、1つのVIPの背後に同じサーバ上の複数のコンテナを配置することが可能です。
また、ループバックインターフェース等の設定もコンテナに対して行います。ここで3つ注意する点があります。
第一に、コンテナにアタッチしてループバックインターフェースやIPIPトンネリングを設定しようとしても、権限の問題で拒否されてしまいます。Dockerのホストサーバ側からコンテナの使用するネットワークの名前空間に入って設定する必要があります。
第二に、rp_filterの無効化が必要です。rp_filterとはReverse Path Filterのことで、Linuxカーネルの機能です。ネットワークインターフェース毎に有効無効を設定します。
あるパケットに対する返りのパケットがインターフェースを通過する時、もし元のパケットがそのインターフェースを通過していなければ、返りのパケットは破棄されます。つまり、rp_filterは別のインターフェースから入って来たパケットへの返信をフィルタリングします。
L3DSRでは、コンテナがロードバランサからIPIPでカプセル化されたパケットを受け取って、クライアントへ直接返りのパケットを送信します。IPIPでカプセル化されたパケットの送信元と返りのパケットの送信先は一致しません。rp_filterには元のパケットなしに返りのパケットが送信されたように認識され、破棄されてしまいます。
パケットが通過するインターフェース全てでrp_filterを無効化していないと、クライアントとの通信はできません。私はコンテナとサーバを接続するcaliインターフェースでrp_filterを無効化するのに気づかず、しばらくハマりました。
第三に、iptablesです。Calicoはfelixというプロセスでiptablesに自動でルールを追加します。その中に、L3DSRと干渉するルールがあります。
具体的には、FORWARDチェインで参照される、コンテナから出て来るINVALIDステートに一致するパケットを破棄せよというルールです。以下のようにiptablesコマンドで確認することができます。
$ sudo iptables -L -v
(略)
Chain felix-FORWARD (1 references)
pkts bytes target prot opt in out source destination
0 0 DROP all -- cali+ any anywhere anywhere ctstate INVALID
(略)
問題はrp_filterと似ています。クライアントとTCPのコネクションを確立する際、コンテナはロードバランサからIPIPでカプセル化されたSYNパケットを受け取って、クライアントへ直接SYN,ACKパケットを返します。しかし、IPIPでカプセル化されたSYNパケットの送信元と、コンテナから出るSYN,ACKパケットの送信先は一致しません。iptablesはSYNパケットを受け取っていないのにSYN,ACKパケットが送信されたと認識します。これがINVALIDステートに一致するため、iptablesによってパケットが破棄されてしまいます。
このルールを削除や上書きしても、felixに自動で差し戻されてしまいます。解決には、Calicoにパッチを当てる必要があります。
導入に向けた検討
総合的に見ると、私はCalicoの方が使いやすいと考えます。
Dockerオーバーレイネットワークを使用する場合、外部と通信するにはコンテナをサーバ側でNAPTする必要があります。そのため、コンテナ、ポート、サーバの対応を管理するのが煩雑になります。一方でCalicoはただのIPルーティングなので、管理するのはコンテナのIPアドレスのみです。
スループットもCalicoの方が高いです。また、Dockerオーバーレイネットワークでは、カプセル化するため50byteだけMaximum Transmission Unitが減少してしまいます。
L3DSRを使用する場合、Dockerオーバーレイネットワークでは同じサーバ上の複数のコンテナにロードバランシングできないという制約があります。これに対してCalicoは、iptablesについてのパッチを当てる必要があるものの、Dockerオーバーレイネットワークのような制約はありません。
Calicoを使う場合、peeringに使用するプロトコロルはiBGPとeBGPから選ぶことができます。iBGPでは、フルメッシュ構造でpeeringすると接続が膨大になり、ルートリフレクタを用意すると一部のルータに接続が集中します。一方、eBGPなら隣接するルータやサーバ同士のみのpeeringで済みます。したがって、eBGPの方がシンプルです。ただし、あまりにサーバが多いとAS番号が枯渇する可能性があります。
Calicoの問題点としては、ルーティングテーブルの肥大化が挙げられます。
CalicoではサーバとルータがBGPのpeeringを行い、ルーティング情報を交換します。各コンテナは/32でIPアドレスを持つので、基本的には1コンテナにつき1行がルーティングテーブルに追加されます。そのため、コンテナの数に比例してルーティングテーブルが大きくなっていきます。ルータの性能を把握した上で検討しないと、肥大化したルーティングテーブルによる負荷が障害を引き起こす可能性があります。
また、AWSやGCPなどのパプリッククラウド環境ではサーバとルータのpeeringができないので、そもそも導入が不可能です。
まとめ
eBGPでCalicoを運用するのが、シンプルでパフォーマンスも高いため望ましいと考えられます。ただし、想定されるルーティングテーブルの規模とルータの性能を付き合わせて検討する必要があります。また、L3DSRで運用する場合はCalicoにパッチを当てなければならないことを忘れてはいけません。
最後に、時に厳しく時に優しく指導してくださったメンターの十場さんをはじめ、ネットワークチーム、サービスファシリティグループの皆さんに感謝します。
インターンではこの調査タスク以外にも、小規模ネットワークの設計・構築を行いました。設計を考えてコンフィグを入れたりネットワーク構成図を書いたりしたことはもちろん、ネットワーク機器をラックにマウントしケーブルをつなぐという物理的作業はとても貴重な経験でした。この調査も自分で設計・構築した検証環境の上で行うことができたため、大変感慨深かったです。とても素晴らしい1ヶ月間だったと思います。
皆さん、本当にありがとうございました。