

はじめまして、サイバーエージェントでアメブロのフロントエンドを担当している侯と申します。
アメブロは今年React/Reduxを採用し、Node.jsをサーバーにして、フロントエンドとサーバーサイドで同じコードを共有できるIsomorphicシステムに移行しました。その結果、パフォーマンスとUXが大幅向上したとともに、PVなどのメディア指標も上がりました。先日、原が「アメブロ2016 ~ React/ReduxでつくるIsomorphic web app ~」でアメブロ2016システム移行のことを紹介しました。今回はIsomorphic JavaScriptの詳細とパフォーマンスチューニングの詳しいお話をさせていただきます。
なぜIsomorphic JavaScriptを使うのか
昔のフロントエンド開発はほぼ完全にSSR(Server-side Rendering)に依存していました。生成されたHTMLファイルをブラウザに渡してそのまま描画していたのです。メリットとしてはページロード速度は早く、SEOにもより有効です。逆にそのデメリットは次のページに遷移するたびに、フルページを読み込む必要があります。そのため、UXがあまりよくないです。
UXを向上するため、リッチなクライエントになることを目指して、SPA(Single Page Application)が生まれました。AngularJSはその代表的なフレームワークの1つです。SPAでは、すべてのロジックをJavaScriptで書いてブラウザで実行されるので、複雑なインタラクションも実現できるようになります。しかし、SPAはブラウザ上でレンダリングします、そのためページの表示にJSの実行が必須になります。その結果として、最初の1ページ目の読み込み速度は遅く、SEOも難しくなります。多くのSPAを採用したサイトはプリレンダリングを使い、検索エンジンのBotを発見したらレンダリングされた静的なページを返します。
ReactはVirtual DOMという仮想DOMを採用し、直接HTMLを書き出すことではなく、処理されたVirtual DOMでHTMLに変換する仕組みです。そうすると、サーバーサイドではNode.jsで同じVirtual DOMを生成して、HTMLレンダリングすることができます。ユーザーはどのページにアクセスしても、最初の1ページ目はサーバーレンダリングしてそのまま見えます。そして、ページ内のリンクをクリックしたら、サーバー経由ではなくブラウザ上でサーバーと同じロジックを使って次のページを生成できます。現在多くのWebサイトがIsomorphic Web Applicationを採用しているのは、Isomorphic Web ApplicationがSSRとSPA両方の優位点を併せ持っているからではないでしょうか。しかし、Isomorphicを導入するためには、サーバーサイドとフロントエンド両方を考慮する必要があり、問題点としてその実装の難易度にあります。
下記の表ではSSR、SPA、Isomorphicの特徴を簡単に比較しています。
| SSR | SPA | Isomorphic | |
|---|---|---|---|
| 最初の1ページ目の表示速度 | 速い | 遅い | 速い |
| 2ページ目からの表示速度 | 遅い | 速い | 速い |
| SEO | 良い | 悪い | 良い |
| 実装難易度 | 低い | 中 | 高い |
問題点はIsomorphic実装難易度です。では、アメブロのIsomorphicの実装方法と実装する際にあった問題及びその解決策をお伝えします。
ちなみに、Michael Jackson氏はIsomorphic JavaScript ではなく、 Universal JavaScript と呼ぶべきだと主張しています。私たちはIsomorphic JavaScriptという名前で使うのに慣れたので、ここでは*Isomorphic JavaScriptと記述します。
AmebloのIsomorphic
技術選定
先に結論をあげます:React + Redux
技術選定の基準は下記となります。
- 安定さ。基本的にプロダクト環境で使える正式版があること。
- アクティブな開発。
- よいコミュニティ。技術の周りに大きいコミュニティが育っていること。
- 実績がある。
まずView層のライブラリの選定です。このプロジェクトは2016年1月にスタートしました。当時、上で掲げた条件をすべて満たすVirtual DOMベースのライブラリはあまり多くありませんでした。Angular 2.0はまだbeta版で安定さにかけており、大規模サービスの実績もなかった。Cycle.jsとRiotはIsomorphicをサポートしていますが、コミュニティは小さいですし、実績もあまりありません。結果的に、Viewのライブラリは定番のReactにしました。条件がすべて満たされていますしし、特にFacebook社は最も重要なプロダクトであるFacebookサイト自体にReactを使っています。信頼性と将来の開発を考えると、Reactは間違いないでしょう。
Isomporphicの基本条件としては、サーバー側でレンダリングしたあとにその状態をブラウザに同期し、ブラウザで引き続き処理することです。Fluxアーキテクチャでは、状態をうまく管理できます。Fluxアーキテクチャの構成要素はAction・Dispatcher・Store・Viewです。リクエストやクリックなどすべての処理はActionからスタートします。発火されたActionはデータを持って、dispatch経由してStoreに発行されます。Storeは渡されたActionと既存のステートを加工し、次のステートを生成します。ViewはStoreの状態が変わった際に、新しいステートで再描画します。そうすると、一方通行へデータが流れるようになり処理の流れは明確になります。Storeが管理された状態をサーバー側からフロントに渡して、フロント上でStoreを回復します。そしてアプリケーションをブートストラップすると、サーバーとフロントの状態同期が実現できます。
しかし、世の中にFluxアーキテクチャであるフレームワークは数多く存在しています。比較した上で、最後にReduxとyahooのfluxibleが残りました。fluxibleのキャッチコピーは「Build isomorphic Flux applications」ですので、Isomorphic JavaScriptのため設計されました。そして社内実績もあります。Reduxは今年から非常に人気になって、単一のStoreと関数型のプログラミングを提唱して、コミュニティも壮大になっていました。更にUberのような大規模の事例も現れました。Reduxと特徴は単一のStoreですので、アプリケーションの実装とテストもより簡単になります。ちなみにRedux作者のDan AbramovさんはReactチームのコアメンバーですので、今後の開発にも安心です。その結果、Reduxにしました。
Isomorphicの実装
サーバーとフロントのエントリーファイル
コンポネントはサーバーとフロントの共通部分として存在していますが、当然サーバー側とフロントのエントリーファイルが違います。
まずはサーバーエントリーファイルのロジックです。
- Storeを準備する。必要なデータを取得して、Storeに反映する。
- react-routerを利用して、リクエストURLをマーチングしレンダリングする必要なコンポネントを抽出する。
- react-router-hookを利用して各コンポネントが必要なデータを取得し、Storeに反映する。
- HTMLファイルをレンダリングする
- body部分をレンダリングする(ReactDOMServer.renderToString)
- Storeをシリアライズし、レンダリングされたbody部分と結合して、最終HTMLを生成する
アメブロでは、サーバーのエントリーファイルをbabelをコンパイルして、そのままNode.jsで実行しています。
そして下記はフロントのエントリーファイルのロジックです。
- Storeをデシリアライズする
- ComponentとStoreでレンダリングして、DOMにマウントする。(ReactDOM.render)
フロントのエントリーファイルをwebpackに設定します。コンパイル後、CDNに配布されます。

Storeの初期処理はサーバーとクライエントで異なります。サーバーとクライエントの共通部分(Isomorphic部分)はcomponentsです。
フロントとサーバー側のエントリーファイルを見ると、相違点は大体Storeの準備段階だけです。レンダリング部分に関して、完全に同じコードを使っていますので、Isomorphicを実現することができました。
StoreのシリアライズとデシリアライズはJSONを使っていますが、そのままstringifyとparseを使うと、エラーがおきます。原因はこちらです。解決方法について、MDNに記載されたことの他、serialize-javascriptはオススメです。
コンポネントのIsomorphic
Reactのコンポネントはサーバー側で実行・レンダリングすることができますが、具体的に若干動作が違います。図でこれを説明します。

これはReact Componentのライフサイクルです。サーバー側で実行される部分はcomponentWillMount → renderまでです。つまりcomponentDidMountなどのライフサイクルメソッドはサーバーでは実行されません。この特性を利用して、サーバーとフロント両方実行する必要な部分はconstructorやcomponentWillMountで書かれ、フロント専用のロジックはcomponentDidMountやupdate系のライフサイクルメソッドで書かれます。
アメブロではデータ取得処理に関して、componentWillMountやcomponentDidMountを利用していないです。全部react-router-hookを利用し、ルート初期化またはルートチャンジのタイミングで必要なデータを読み込んでいます。
スタイルシートなどの静的なファイルのIsomorphic
スタイルシートなどの静的なファイルのIsomorphicは一番ハマっていたところの1つです。
Node.jsはcssなどの静的なファイルを直接にrequireできません。その解決案について、まず考えたことは CSS in JS でした。CSS in JSはJavaScriptのオブジェクトでcssを書き、Reactコンポーネントにそのままスタイルを付与することです。代表のライブラリとして、Redium、react-styleなど数多く存在しています。CSS in JSの一番よいところはシンプルで実装しやすいですし、完全にコンポーネント毎に分割もできます。スタイルをすべてDOMに組み込むことにより、レンダリング速度も早いと想定されます。デメリットとしては、まずJavaScriptで書かれるので、cssの機能を全部カバーできません。例えばメディアセレクタが必要となるときに、サーバーサイドで情報を取れないので、うまくレンダリングできないです。さらに、開発者として重大な問題は、非常に便利なstylelintなどのコードチェックツールと自動補完ツールも使えないです。
やはりスタイルはcssで書くほうがいいなと思っていたところ、css modulesが我々の視野に入りました。css modulesはまずすべてのスタイルはcssで書きます。書かれたcssファイルをコンパイルして、クラス名がハッシュ化されたcssファイルとクラス名のマッピング情報があるjsかjsonを生成します。そうすると、各CSSルールはそれぞれコンポーネント内に閉じられます。コンパイルされたjsファイルを参照しコンポーネントにクラス名を付与すると、スタイルルールが適応されます。css modulesの一番有名なインプリメンテーションはwebpackのcss loaderです。webpackですから、stylelintなどはもちろん、sass、PostCSSなどのcssツールも使えるようになります。アメブロではcss modulesを採用しました。
Node.js側でコンパイルされたファイル情報を参照するため、webpack-isomorphic-tools を使っています。webpack-isomorphic-toolsを使うと、cssだけではなく、画像がフォントなどの静的なファイルもjsでrequireができるようになります。
しかしcss modulesも完璧ではありません。css modulesを使う場合、コンポーネントに付与するのは実際のスタイルではなく、cssクラスの名前です。スタイルコンポーネントから独立になるので、完全にコンポーネント毎にコードを分割するのは多少難しいです。より良さそうな解決策はscoped cssですが、残念ながら今年whatwg標準仕様の提案から撤下されました。
環境変数のIsomorphic
12-factor にとても重要なルールは設定を環境変数に格納することです。アメブロでは、この理念を従って、すべての設定を環境変数に入れています。それに dotenv を使い、envファイルと環境変数が両方を使える柔軟な仕組みを取り込んでいます。一番大きいメリットはステージング環境でテスト済みのコードがそのまま本番環境にデプロイできます。
しかし、クライエント側のコードはCDNに配布されているものです。サーバーで設定を環境変数にしてもクライエントはハードコーディングすると、環境変数に格納する意味はなくなってしまいます。
アメブロでは、これを解決するために環境変数もIsomorphicにしています。すべての環境変数を使うときに、Node.js標準のprocess.envを使っています。サーバー側で最終のHTMLを生成するときに、サーバーの環境変数からクライエント使用可の物をフィルタリングし、window.process.env = ${JSON.stringify(CLIENT_ENV)}の形でHTMLに書き込みます。ページが読み込まれるときに、先にprocess.envが初期化され、Node.jsっぽい環境変数のグローバル環境を作ります。
ちょっと注意しないといけないところは、webpackがコンパイルする際に、勝手にprocessオブジェクトを作ります。webpackの設定にnode.processをfalseにすれば解決します。詳しいことはwebpackのドキュメントを参照してください。
データ処理問題
最初の1ページ目はSSR、2ページ目はSPA、その2ページ目からフロント側でサーバーを引き継いで処理することがIsomorphicの基本的な要求です。それに速度の改善は今回システム移行のかなり重要な目標でした。画面上の内容はStoreに保存されているデータにより表示されるので、データロードがうまくできればユーザー体験も向上できます。
そのため、適切なタイミングで適切なデータロードすることは不可欠の要件になります。
これは適切なタイミングに関連する問題点です。
- サーバーとフロント
- ルート遷移の前後
- ページの上から下へスクロール
これは適切なデータにより関連する問題点です。
- 重複リクエストの回避
- データ依存関係の解消
- サーバーしかできない処理
【適切なタイミング1】サーバーとフロント
「この部分はサーバーでローディングし、フロント上で表示されたら、引き続き他のデータをローディングする」という場面がよくあります。但し、一旦SPAに入ると、すべてのデータをローディングする必要があります。
アメブロではreact-router-hookを利用して、コンポーネントにhookメソッドを書いて、サーバーとクライエントで異なる動作をします。
// SpComponent.js
@routerHooks({
fetch: async ({ dispatch, getState, params }) => {
// 略
},
defer: async ({ dispatch, getState, params }) => {
// 略
},
done: async ({ dispatch, getState, params }) => {
// 略
},
})
export class SpComponent extends React.Component {
// 略
}
コンポーネントの実装例です。ここにjavascript-decoratorを使っています。
// app.js (サーバーのエントリーファイル)
triggerHooksOnServer( // react-router-hookのメソッド
// renderPropsはreact-router match()の結果です。
// 表示すべきコンポーネントはrenderPropsに含まれます
renderProps,
['fetch', 'defer'],
{
dispatch: store.dispatch,
getState: store.getState,
},
{
onComponentError: (err) => {
// エラー処理(略)
},
},
);
サーバー側でコンポーネント内に書かれたfetch()とdefer()メソッドを実行します。
// react-router-hookミドルウェアを作成する
const routerHookMiddleware = useRouterHook({
routerWillEnterHooks: ['fetch'],
routerDidEnterHooks: ['defer', 'done'],
locals,
onError,
onStarted,
});
// ミドルウェアをreact-routerに入れる
ReactDOM.render(
<Provider store={store}>
<Router
history={history}
render={applyRouterMiddleware(routerHookMiddleware)}
>
{routes}
</Router>
</Provider>,
element,
);
クライエント側でhookメソッドを設定すれば、順番通り実行されます。ここにfetch()とdefer()がサーバーとクライエント両方で二重実行されますが、実際にstoreに保存されたデータの有り無しを判定してから、データ取得を行います。done()はクライエント専用ですから、サーバー上で実行したくない部分をdone()に入れています。
【適切なタイミング2】ルート遷移前と遷移後
routerWillEnterHookとrouterDidEnterHookを設定して、ルート遷移するときに必ず一回fetch()→defer()→done()を実行します。この区別はrouterWillEnterHooksの実行が終わらないと、コンポーネントをレンダリングしないです。routerDidEnterHooksはコンポーネントと同時に走ります。
アメブロでは基本的に非同期でデータ処理とレンダリングが同時に走りますが、一部の極少ないコンポーネントは要件に応じてfetch()を持っています。
別の視点でみると、サーバーとフロントも、ルート遷移前と遷移後も同じくURLの変化がある時のデータローディングです。

サーバーとフロント、ルート遷移前と遷移後のまとめです。
【適切なタイミング3】ページの上から下へスクロール
ページの上から下へスクロールに合わせてデータローディングするのはLazy Loadの一環です。ここに rrr-lazyを使っています。rrr-lazyはコンポーネントのレンダリングを遅延させるだけではなく、react-router-hookと一緒に使ってデータローディングも遅延させることができます。サーバー上でコンポーネントをLazy化にしてデータローディングを遅延させます。そして、スクロールするときにrrr-lazyは事前に設定された閾値で位置に合わせて、fetch()・defer()・done()をコールします。
サーバー上でいち早くレンダリングするため、アメブロではメインコンテンツとページ上部のコンテンツ以外のコンポーネントはほぼすべてLazy化されています。
【適切なデータ1】重複リクエストの回避
モジュールが多くなれば多くなるほど、データ読み込みも複雑になります。例えばページ上の2つモジュールが同一のデータに依存して、表示する際にデータ取得も同時に走って、重複リクエストが発生してしまいました。
これを回避するため、Reduxのプラグインredux-dataloaderを導入しました。redux-dataloaderはPromiseを利用して、一定の時間内に同じ非同期actionが発火しても、一個しか実行させません。
アメブロでは、それぞれのデータ取得処理をそれぞれのdataloaderを定義しました。具体的に、ブログ情報の取得処理を例として説明しましょう。
まず非同期アクションの要素として、リクエスト・成功・失敗それぞれを定義します。
// blogAction.js
import { load } from 'redux-dataloader';
// リクエスト
export function fetchBlogRequest(blogId) {
// load()はPromiseを返します。
return load({
type: FETCH_BLOG_REQUEST,
payload: {
blogId,
},
});
}
// 成功アクション
export function fetchBlogSuccess(blogId, blog) {
return {
type: FETCH_BLOG_SUCCESS,
payload: {
blogId,
blog,
},
};
}
// 失敗アクション
export function fetchBlogFailure(blogId, error) {
return {
type: FETCH_BLOG_FAILURE,
payload: {
blogId,
error,
},
error: true,
};
}
そして、非同期アクションFETCH_BLOG_REQUESTに対応しているdataloaderを用意します。
// blogLoader.js
import { createLoader } from 'redux-dataloader';
import * as blogAction from './blogAction.js';
export const blogLoader = createLoader(blogAction.FETCH_BLOG_REQUEST, {
success: ({ action }, data) => {
const { blogId } = action.payload;
return blogAction.fetchBlogSuccess(blogId, data);
},
error: ({ action }, error) => {
const { blogId } = action.payload;
return blogAction.fetchBlogFailure(blogId, error);
},
fetch: async ({ action }) => {
const { blogId } = action.payload;
const data = fetchBlog(blogId); // データを取得する
return response.data;
},
shouldFetch: ({ getState, action }) => {
// getState()で現在のステートにより、fetch()を実行するかどうか判定します。(略)
},
}, {
retryTimes: 0, // 失敗となるときに、リトライもサポートしています。
ttl: 10000, // 10秒以内に重複リクエストが発生しないように
});
用意されたdataloaderをredux-dataloaderミドルウェアに登録して、非同期アクションの作成が完了です。
必要なところに非同期アクションを発火させ、データ取得を行います。こうすることで無駄なリクエストが発生しないです。
// SpBlogTitle.js
const defer = async ({ dispatch, params }) => {
const blogId = params.blogId;
await dispatch(fetchBlogRequest(blogId));
};
@routerHooks({ defer })
export class SpBlogTitle extends React.Component {
// 略
}
// SpBlogContent.js
async function defer({ params, dispatch, location, getState }) {
const blogId = params.blogId;
await dispatch(fetchBlogRequest(blogId));
// 他の処理
}
@routerHooks({ defer })
export default class SpBlogContent extends React.Component {
// 略(
}
SpBlogTitleとSpBlogContentが同時に表示される場合でも、ブロガー情報の取得が1回しか走りません。
【適切なデータ2】データ依存関係の解消
データが依存関係を持つことはよくあります。これもredux-dataloaderを使って解決しています。
例えばBlogger's Avatar => Blogger => Blogのような依存関係がある場合、下記のようにBlog => Blogger => Blogger's Avatarの順番で取得することができます。
// SpBlogContent.js
async function defer({ params, dispatch, location, getState }) {
// blogを取得します
const blogId = params.blogId;
await dispatch(fetchBlogRequest(blogId));
// fetchBlogRequest()の実行が終わるまで待ちます
const blog = getState().blogMap[blogId] || {};
// bloggerを取得します
const bloggerId = blog.bloggerId;
await dispatch(fetchBloggerRequest(bloggerId));
const blogger = getState().bloggerMap[bloggerId];
// bloggerのAvatarを取得します
const avatarId = blogger.avatarId;
await dispatch(fetchAvatarRequest(avatarId));
}
@routerHooks({ defer })
export default class SpBlogContent extends React.Component {
// 略(
}
パフォーマンスを向上するため、Promise.allを使って依存性が無いデータに対して平行で取得することができます。
【適切なデータ3】サーバーしかできない処理
Isomorphicですが、全て同じ構造で書くわけにはいけません。例えば内部API、認証APIなど叩くときに、サーバーしかできない処理もあります。
サーバーだと関数を呼び出すだけで処理を実行できますが、SPAになるとクライエントからHTTPリクエストで同じ関数を呼び出さないと実行できないです。これを解決するために、Yahooのfetchrを導入しました。
各処理をServiceで定義して、fetchrに登録したらサーバー側とクライエント側両方とも同じ使い方で呼び出す事ができます。アメブロではfetchrをredux-dataloaderのコンテキストに登録して、redux-dataloaderを合わせて使っています。そうすると、fetchrによりの重複リクエストも回避できます。
// blogLoader.js
import { createLoader } from 'redux-dataloader';
import * as blogAction from './blogAction.js';
export const blogLoader = createLoader(blogAction.FETCH_BLOG_REQUEST, {
success: ({ action }, data) => {
const { blogId } = action.payload;
return blogAction.fetchBlogSuccess(blogId, data);
},
error: ({action},error) => {
const{blogId} = action.payload;
return blogAction.fetchBlogFailure(blogId,error);
},
fetch: async({fetchr,action}) => {
const{blogId} = action.payload;
constresponse = awaitfetchr.read('blog')
.params({
blogId,
}).end();
return response.data;
},
shouldFetch: ({getState,action}) => {
//getState()で現在のステートにより、fetch()を実行するかどうか判定します。(略)
},
}, {
retryTimes: 0,//失敗となるときに、リトライもサポートしています。
ttl: 10000,//10秒以内に重複リクエストが発生しないように
});
redux-dataloaderのfetch()メソッドでfetchrを使うときの様子です。

react-router-hook・dataloader・fetchrを一緒に使う時のデータ取得フローです。
パフォーマンスチューニング
Isomorphic Web Applicationのパフォーマンスチューニングは特別な特徴があって、サーバーとブラウザ両方を考慮しないといけないです。
パフォーマンスの問題は下記の4つあります。
- サーバーCPUによりパフォーマンス問題
- ブラウザCPUによりパフォーマンス問題
- サーバーメモリによりパフォーマンス問題
- ブラウザメモリによりパフォーマンス問題
サーバーのCPU系
今回のフロントシステム移行では、実装がほぼ終わったタイミングで負荷試験を行いました。その結果は非常に悪かったです。
ローカルで負荷試験を実行してみて、結果は大体下記のようになります。
| 同時リクエスト数 | スループット | 平均レスポンスタイム |
|---|---|---|
| 5 | 17.57rps | 283.334ms |
| 10 | 20.34rps | 928.175ms |
| 20 | 19.88rps | 964.580ms |
| 40 | 19.70rps | 1887.422ms |
そのままだと完全に使えるものにならないです。パフォーマンスに対して我々は色々なチューニングしました。
パフォーマンスが良くない原因を調査するには、ひとまずProfileツールで調べました。ちょうどその時にNode.jsがChrome上でProfileできるようになり、早速使ってみました。
node --inspect server.jsを実行し、コンソールで表示されたchrome-devtools://から始まるURLをコピーしてChromeで開きます。
そして、「Profiles」に切り替え、「Record JavaScript CPU Profile」を選択し「Start」を押して記録がは始まります。負荷試験ツールでしばらく負荷をかけ続けて、最後に「Stop」を押したら結果が表示されます。
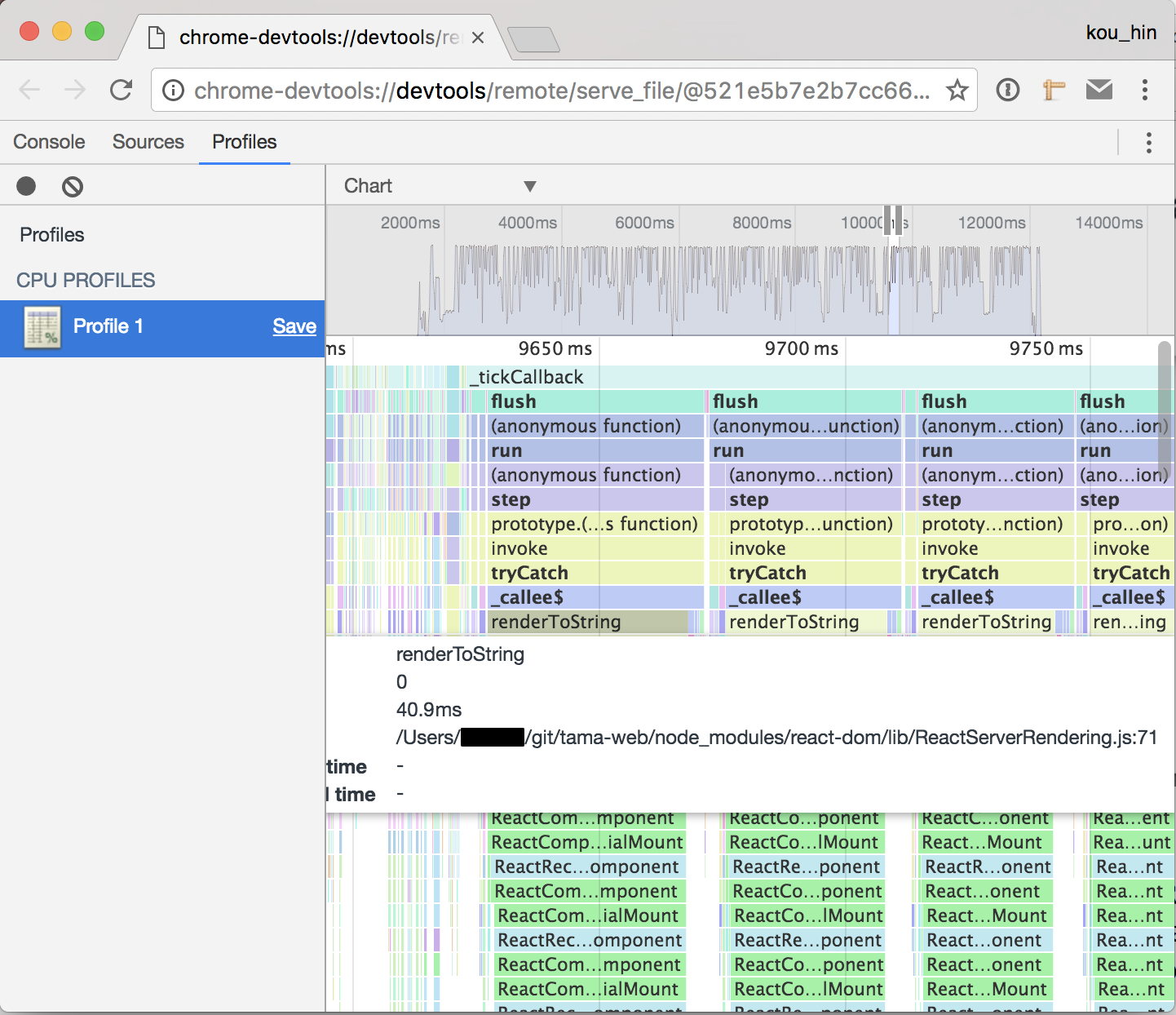
このフレームチャートは各関数の実行時間と呼び出すスタックを表示しています。調べてみると、ReactのrenderToString()は1つだけで40msぐらいかかりました。それにNode.jsはシングルスレッドですので、renderToString()は並行ではなく、必ず一個ずつ実行されます。そうすると、単純に1000ms / 40msで計算して、スループットは25rpsです。更に一番上の_tickCallbackが214msかかりました。この214msの間にはI/Oから返されたイベントは受け取れないです。Node.jsの最大な特徴は「ノンブロッキングI/O」ですが、この場合I/Oをブロックしてしまいました。
ブラウザでのレンダリング場合、1つのブラウザスレッドは一人にサービスを提供するので、ほぼ大丈夫です。但し、サーバーの場合1つのスレッドは同時に複数の人にサービスを提供しています。これは大変なことになります。
これの解決方法は大体下記の2点となります。
- 適切なところに
setTimeout(fn, 0)を入れて、長時間の処理を細かく裁ける。 - メイン容以外の内容を遅延ロードにして、
renderToString()の時間を短縮する。
チューニングの結果、下記となります。
| 同時リクエスト数 | スループット | 平均レスポンスタイム |
|---|---|---|
| 5 | 23.32rps | 212.992ms |
| 10 | 36.57rps | 265.269ms |
| 20 | 46.57rps | 418.849ms |
| 40 | 52.63rps | 692.833ms |
それに、キャッシュを導入してrenderToString()を通すことなくページを返します。キャッシュサーバーはmemcachedを採用しています。現在memcachedのヒットレートは73%ぐらいなっています。キャッシュされたページのレスポンスタイムは50ms以下になっています。
ちなみに一番最初にmemcachedではなく、Redisを使いました。しかし、Redisにおいてオブジェクトのサイズが10kbを超えて、特にevictionが発生するとパフォーマンスが急激に落ちます。そのため、途中memcachedに切り替えました。
フロントのCPU系
フロントのパフォーマンスはUXに直結するので、結構大事です。ここにパフォーマンス問題はサーバーとほぼ一緒、速度が下がる原因は主にブラウザのシングルスレッド仕組み+Reactのレンダリングアルゴリズムです。チューニングの方法もサーバーと一緒です。
ちなみに、iOSとAndroidのシステムによってパフォーマンスが大分違います。iOSでスムーズに動作するところ、Androidでは若干FPSが落ちます。原因はまだ不明ですが、デスクトップ版のSafariでデバッグする時に、タイムラインで長時間の処理がなさそうです。
サーバーのメモリ系
フロントの場合はメモリリークが発生しても、動作が遅くなったりブラウザが落ちったりしますから、サービス自体に影響はあまりないです。サーバー上でメモリリークが発生すると、サービス全体が落ちる可能性があります。
Node.jsは基本非同期で処理しますので、スレッドセーフ問題を注意しないといけないです。例えばRedux Storeの作成は必ずリクエストが来る時に新しいStoreを作成しなければなりません。
今回の移行で一番印象深いメモリリークはdefaultPropsです。「ES6 + React + defaultProps」で検索すると、書き方ほぼ下記のようになります。
export class SomeComponent1 extends React.Component {
static defaultProps = {
// ...
}
// ...
}
// または
class SomeComponent2 extends React.Component {
// ...
}
SomeComponent2.defaultProps = {
// ...
}
export SomeComponent2;
この書き方はフロントではほぼ問題ないです。しかし、サーバーだとこのコンポーネントクラスとdefaultPropsは1回しか初期化されません。もしdefaultPropsに配列の値が存在して、処理の際に配列に新しい中身をどんどん追加すると、この値はどんどん大きくなります。結果としてメモリリークになります。
これを回避するために、下記の書き方がおすすめです。
export SomeComponent extends React.Component {
static get defaultProps() {
return {
// ...
};
}
}
この書き方は毎回defaultPropsを取得する時に、新しいオブジェクトを生成します。先程のメモリリークを回避することができます。
正直なところサーバー上のメモリリークを完全に回避することは難しいです。負荷をかけ続けてメモリの状況を観察することで少しでも多くのメモリリークを減らす努力はした方がよいでしょう。
フロントのメモリ系
フロント上で小さいメモリリークが発生する時は気づきにくいです。SPAだと、ページ遷移を何度もしてメモリを観察する方法があります。
メモリリークがよく発生するところはReactのライフサイクルです。Reactはコンポーネント内部のstateが更新されると、shouldComponentUpdate() → componentWillUpdate() → render()で実行されます。componentWillUpdate()やrender()の中でstateを更に更新したら、もう一回走り、無限ループになる原因となります。その場合コールスタックがいっぱいになります。メモリ使用量が急に増えます、CPUもいっぱいになります。
明らかに動作が遅くなったら、CPUとメモリの使用量が上がったりしていないかをChrome DevToolsを使って確認して解決できます。
まとめ
アメブロ2016のシステム移行でReactとReduxを使い、Isomorphic JavaScriptを実装しました。Reactは両方のレンダリング部分を担当し、Reduxはその間のステート維持する部分を担当しています。Isomorphic JavaScriptはサーバーとフロントの壁を突破し、サーバーとフロントは完全に1つのアプリになっています。これは今まで進化し続けてきたフロントとサーバー技術の結果だと考えられます。しかし、サーバーはすべてのユーザーにサービスを提供し、フロントは一人のユーザーにサービスを提供することがサーバーとフロントの大きい差異です。この差異により実装の際にいろいろな落とし穴を踏んできましたが、システム移行を無事完遂しました。
本当に辛かったところはシングルスレッドとReact同期型のレンダリングアルゴリズムのところでした。Reactチームはこの問題をすでに気づいていますので、React Fiberというアーキテクチャを提案し、絶賛開発中のようです。。非常に大きな期待を抱いています。
システムの移行は完了しましたが、まだまだパフォーマンスを向上させる余地はあると思うのでチューニングしていきます。
アメブロシステム移行に関するその他の記事・スライドは下記をご覧ください!
◆アメブロの大規模システム刷新と それを支えるSpring