
株式会社サイバーエージェントメディア事業部に所属しているMLエンジニアの松月です。本記事では2022年8月30日に開催された「メディアサービスにおけるデータ・AIの活用事例」というイベントについての開催レポートをお届けします。どんな内容のイベントであったか?を表現するために、一部の発表をピックアップし簡単に紹介します。こちらのイベントではオフライン+オンラインによるハイブリッド形式でのイベント開催を予定しておりましたが、新型コロナウイルスの拡大に伴いオンラインのみの開催となりました。オフライン開催を楽しみにしていた参加希望者の方々、重ねてお詫び申し上げます。 
イベント概要
当イベントはサイバーエージェントのメディアデータを活用した機械学習の取り組みやデータサイエンティストの業務、組織としてメディアデータをどう扱っているか?ということをテーマで開催しました。事前の参加登録では110人もの参加希望者にご応募いただきました!当日のタイムスケジュールは以下のように実施されました。
| 時間 | コンテンツ |
|---|---|
| 19:00 | zoomオープン |
| 19:10 – 19:15 | オープニング |
| 19:15 – 19:30 | 「AbemaDataCenterにおけるデータ活用への取り組み」岸 良 「サイバーエージェント、メディア事業における機械学習の紹介」數見 拓朗 |
| 19:30 – 19:45 | 「ABEMAのレコメンドにおける基盤とA/Bテスト」 山口 達輝 |
| 19:45 – 20:00 | 「Amebaにおけるコンテキスト広告配信のこれまでとこれから」 加藤 諒 |
| 20:00 – 20:15 | 「マッチング理論に基づく推薦とそれを支えるMLOps開発」 松月 大輔, 冨田 燿志 |
| 20:15 – 20:20 | クロージング |
| 20:20 – 21:00 | 登壇者への質問会 |
オープニング終了後はサイバーエージェントのメディア事業部では組織としてどのようにデータ活用・機械学習を扱っているか?について紹介され、その後メディア事業部のサービスであるABEMA、Ameba、タップルで実際にどのようなことをやっているか?が紹介されました。 本記事では「ABEMAのレコメンドにおける基盤とA/Bテスト」、「マッチング理論に基づく推薦とそれを支えるMLOps開発」について簡単に紹介します。
ABEMAのレコメンドにおける基盤とA/Bテスト
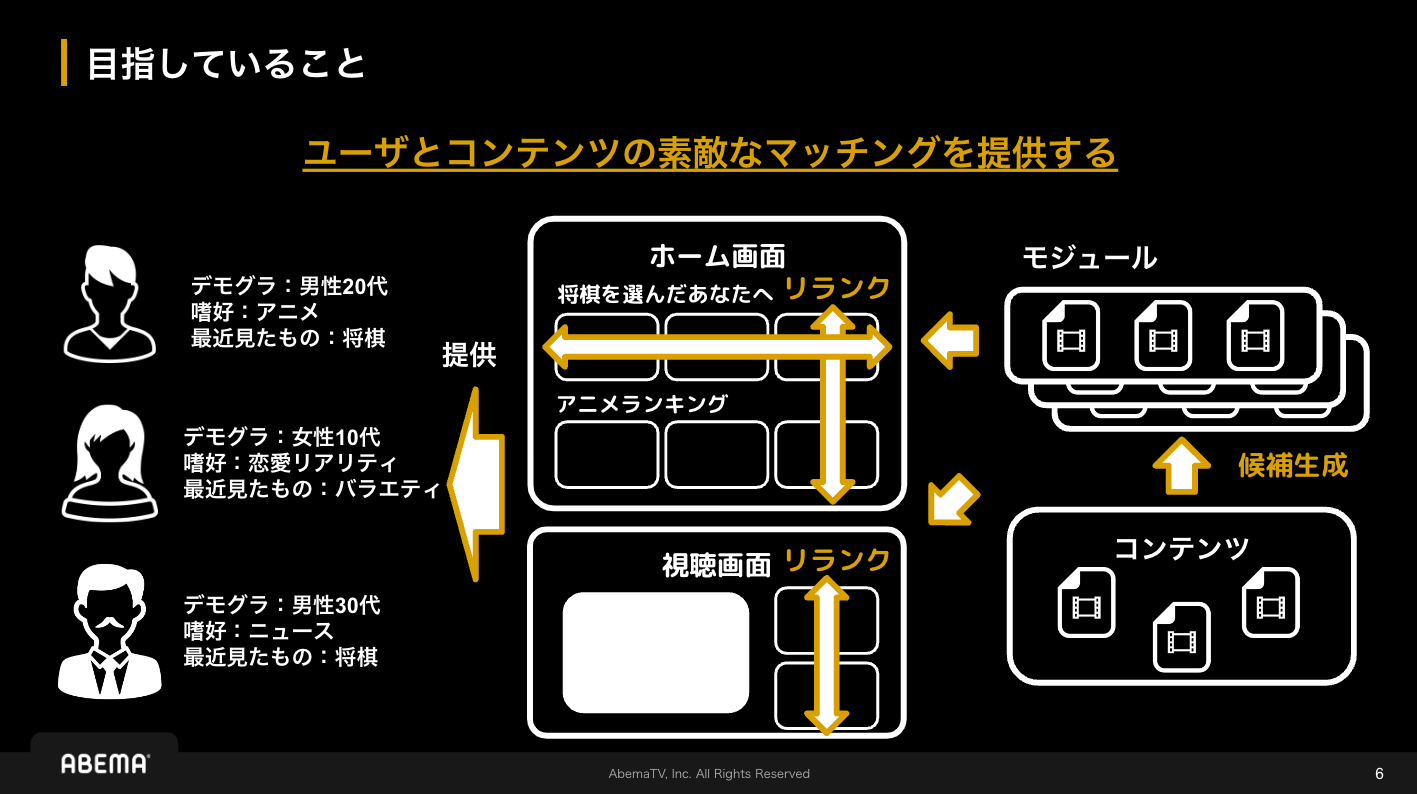
こちらのセクションでは新しい未来テレビ「ABEMA」におけるレコメンド基盤とA/Bテストについて発表されました。 ABEMAのレコメンドでは、コンテンツ単位、コンテンツをまとめたモジュール単位といったリランクの適用単位に加え、ホーム画面、視聴画面のような画面適用単位などを考慮して「ユーザとコンテンツの素敵なマッチングを提供する」ことを目指しています。(図1を参照) これを実現するためにABEMAでは図2に示すような要素に分けて開発を行っています。今回の発表内容は①基盤技術について紹介されました。ここではその中でも開発しているレコメンド基盤について少し紹介します。
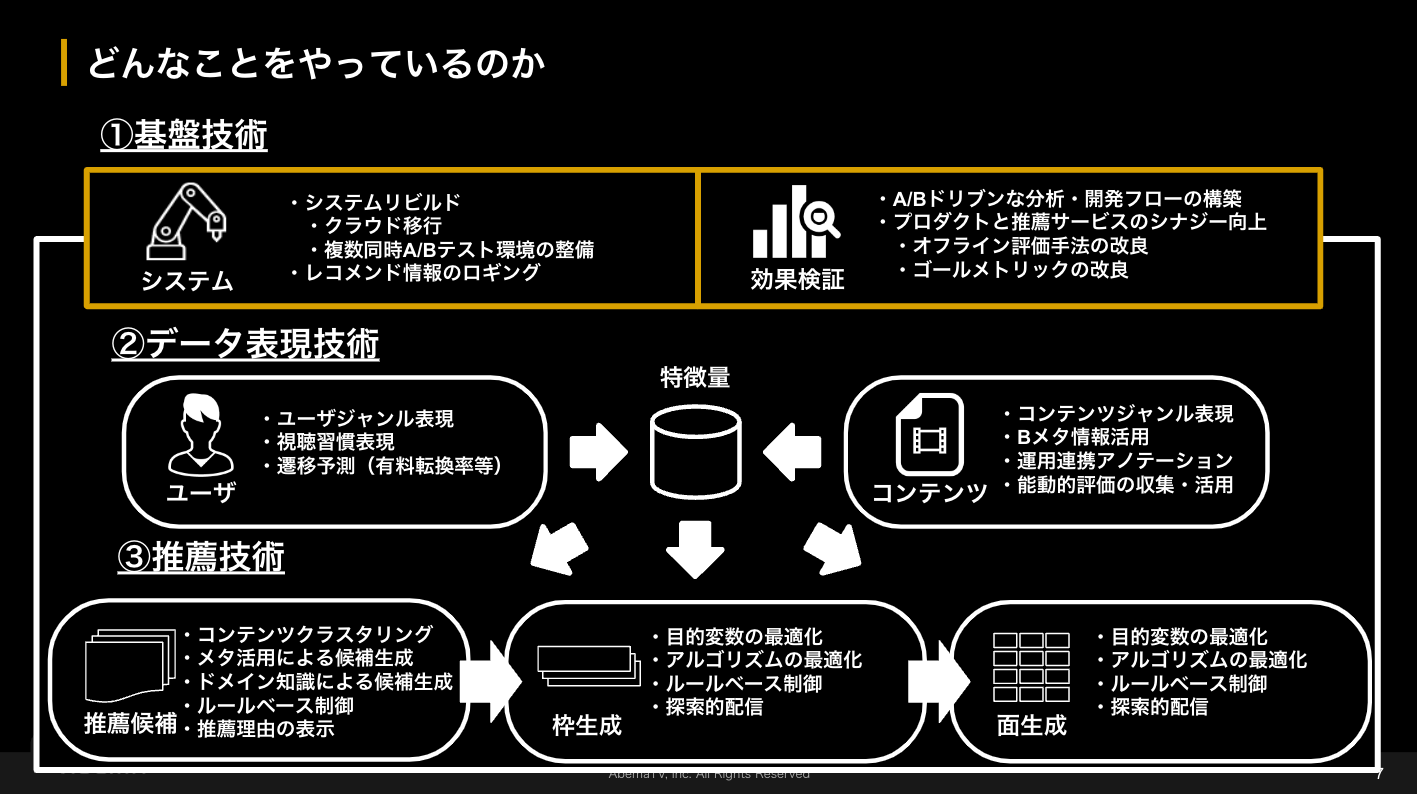
ABEMAの推薦基盤を設計する上では図2で示すような開発における要素技術を運用するような機能要件だけではなく、ビジネス要件に答えることも重要となります。 この要件は施策単位で求められていることが異なるため、多様な活用シーンに適した推薦手法の提供が必要になります。
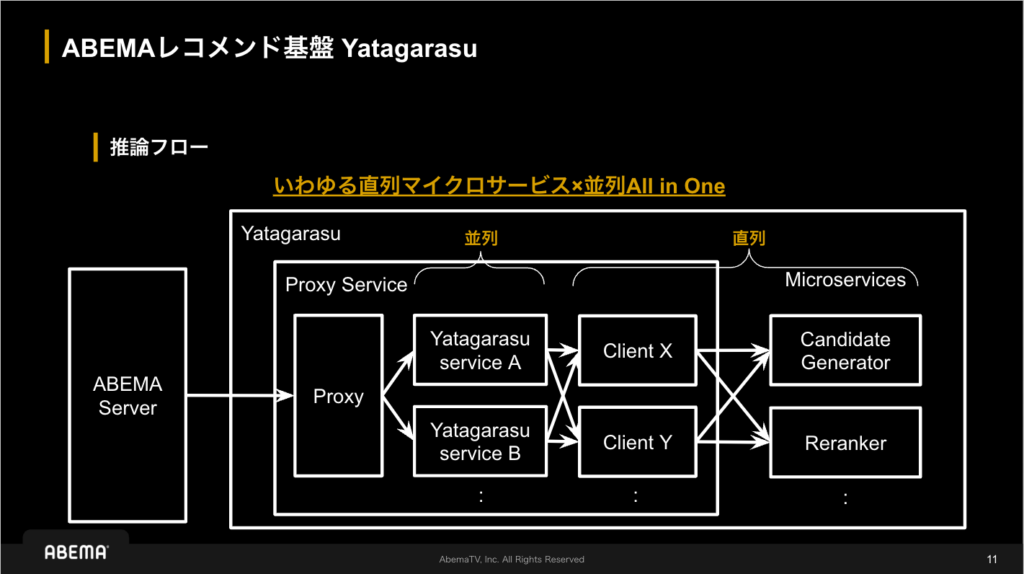
ABEMAではレコメンド基盤Yatagarasuの開発に取り組んでおり、この課題解決を目指しています。(図3を参照) Yatagarasuはマイクロサービスアーキテクチャを採用しており、要件さえ満たせばどんなロジック/実行環境でも施行することが可能で、ロジックの使い回しが可能になっています。これは車輪の再発明を防ぐ意味でも、オンライン検証まで素早く実行するためにも大きなメリットがあります。
詳しい発表内容及び、ここで紹介しきれなかったA/Bテストについては以下の発表資料でまとめられれています。是非ご覧ください。
マッチング理論に基づく推薦とそれを支えるMLOps開発
こちらのセクションではマッチングアプリ「タップル」のレコメンド改善と、それを支えるMLOpsについて発表されました。 タップルのレコメンドの面白い要素として、推薦者と被推薦者の双方向の嗜好を考慮する必要がある点が挙げられます。例えば、ユーザーAがユーザーBに強く興味を持っていても、ユーザーBがユーザーAに興味がない場合は推薦効果が小さくなります。この問題を解決するために、相互推薦システム(Reciprocal Recommender Systems; RRS)を開発しています。(図4を参照)
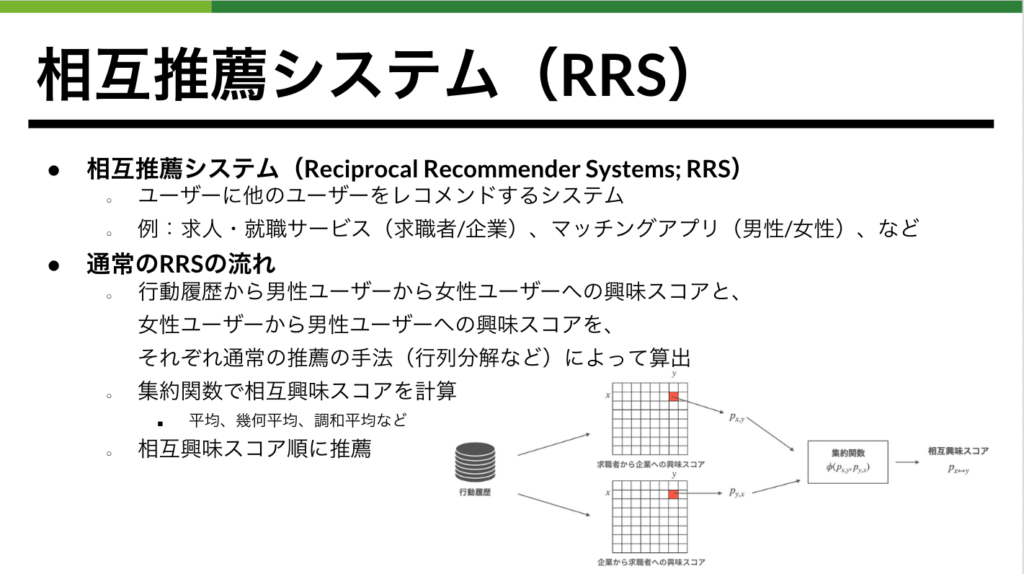
双方向性を考慮できるRRSですが挙げられる課題として、被推薦機会の集中・不平等が挙げられます。これは一部の人気ユーザーは、多くの人から興味スコアが高くなるため集約された相互興味スコアも人気ユーザーは高くなりやすく、被推薦機会が集中することを意味します。その逆も然りです。(図4の「通常RRSの流れ」を参照するとわかりやすいです) 登壇者であるAILabの冨田はこの問題を解決すべくマッチング理論を応用することで、推薦機会集中の緩和に着手しました。この結果は推薦システム分野におけるトップカンファレンスRecSys2022インダストリアルセッションのポスター発表に採択されました。発表の詳しい内容は論文も公開されているのでご覧ください。
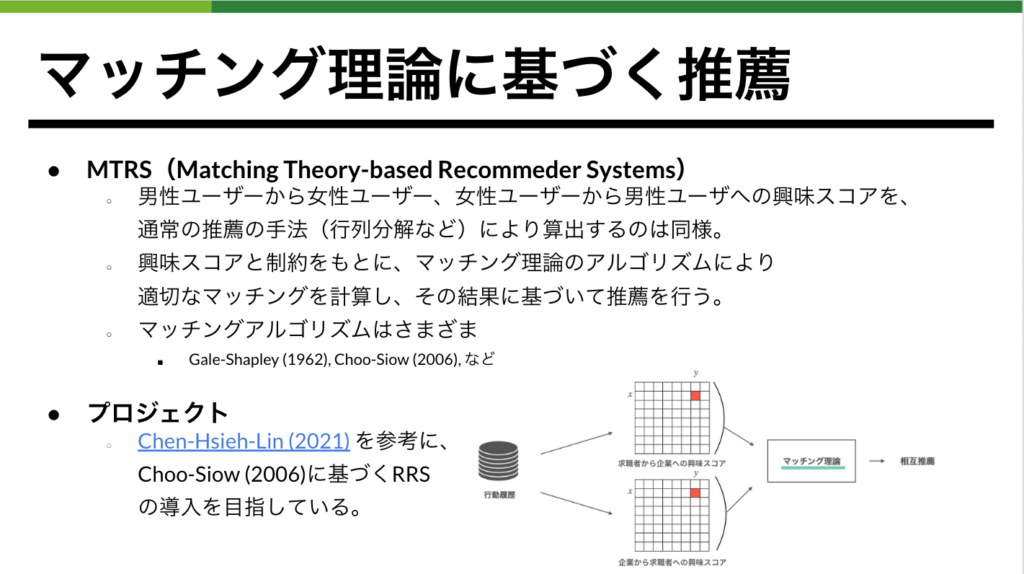
冨田が開発したマッチング理論に基づくレコメンド手法などリサーチャーや機械学習エンジニアが開発したレコメンド手法はどのような環境で開発されているのでしょうか? 本発表では次にタップルのレコメンドシステムにおけるMLOpsについて紹介されました。タップルのレコメンドシステムは大まかに以下のような要件から2021年5月にリリースされたVertexAIを用いた開発に着手しています。
- GCP製品と親和性が高い
- BigQueryやCloud Storageを使用することが多い
- FeatureStore
- オフラインバッチ処理による特徴量保存ストアを使用したい
- Endpoint
- オンライン予測をしたい
- Pipelines
- MLエンジニア、データサイエンティスト、リサーチャーが開発に従事するため、機能や役割ごとの開発を行いたい
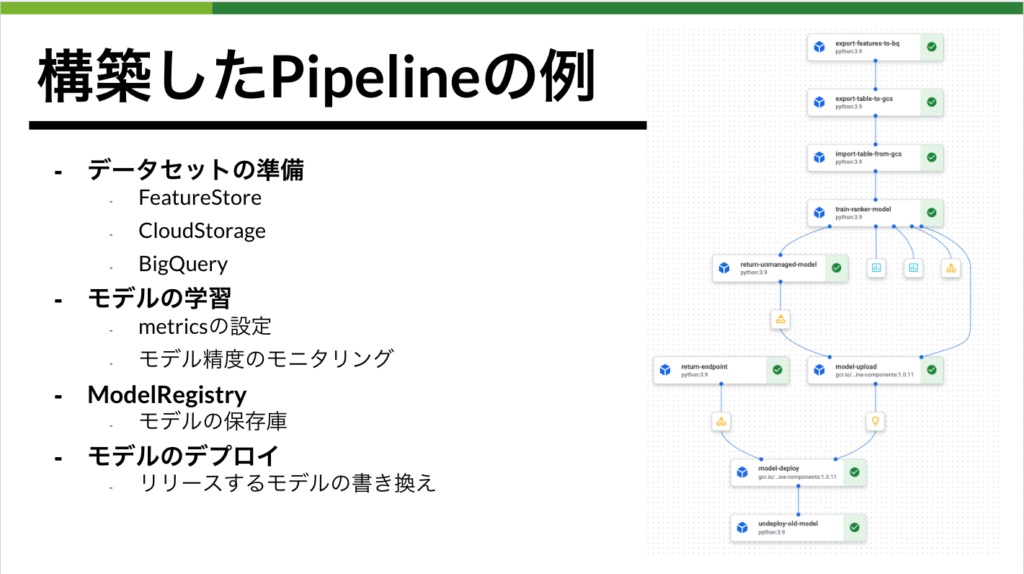
図6はデータの準備、モデルの学習、モデルのデプロイ、エンドポイントの発行までを実装したPipelineの例です。比較的簡単にレコメンドモデルのデプロイまでのプロセスを設計でき、且つ中間生成物(Artifact)も全てGCP上で完結することができるので、チームとして運用のルールを設計しやすい事も良い部分であると感じています。
こちらも詳しい内容については以下の発表資料をご覧ください。
最後に
本エントリでは、2022年8月30日に開催された「メディアサービスにおけるデータ・AIの活用事例」のイベント開催レポートをお届けしました。次回開催時期は未定ですが、発表時間の調整やよりデータ活用技術に深ぼった内容にアップデートを予定しています。当イベントの開催についてはconnpassで公開いたしますので是非グループメンバーへの追加をお願いいたします。