
この記事は CyberAgent Developers Advent Calendar 2022 の5日目の記事です。
AI事業本部でソフトウェアエンジニア(機械学習 & MLOps領域)をしている yu-s (GitHub: @tuxedocat) です1。現在は 極予測LP という、広告ランディングページの制作をAIにより刷新するという目標のプロダクトに関わっています。 この記事では本プロダクトのMLOpsの取り組みのうち、特に深層学習モデルをデプロイして運用する基盤についての技術選定を振り返ってみます。 タイトルにあるとおり Triton Inference Server というOSSの推論基盤を導入しました。
前置き: プロダクトやチームなどの環境と経緯
本記事は筆者が所属するプロダクトにおける深層学習モデル用推論基盤の問題を技術選定で改善した事例について、特に Triton Inference Server に関連する内容を中心に導入の経緯やその評価、そして所感を書きました。 また、参考のため Triton Inference Server の概略や簡単な実装サンプル、細かいTipsなども含めるようにしました。 複数の深層学習モデルを構築しデプロイする必要がある場合に、もしかしたら役に立つかもしれない内容です。
この記事で対象となる環境は以下のような感じです。 本プロダクトは Google Cloud Platform (GCP) をメインの環境としており、またGoogle Kubernetes Engine (GKE) 上にデプロイされるサービスが多数を占めています。特に研究開発や他のプロダクトへの展開の都合上、社内のk8sベースのML基盤上でのデプロイも想定していたため、SageMakerやVertex AIの提供する end-to-endなサービスまたはマネージド推論サーバーは初期の検討で候補から外れました。
本プロダクトで扱う推論ワークロードの特性は、画像やテキストなどを扱うマルチモーダル性と、数百万件程度のバッチ処理とユーザーが利用するインタラクティブな利用が混在しているという点です。

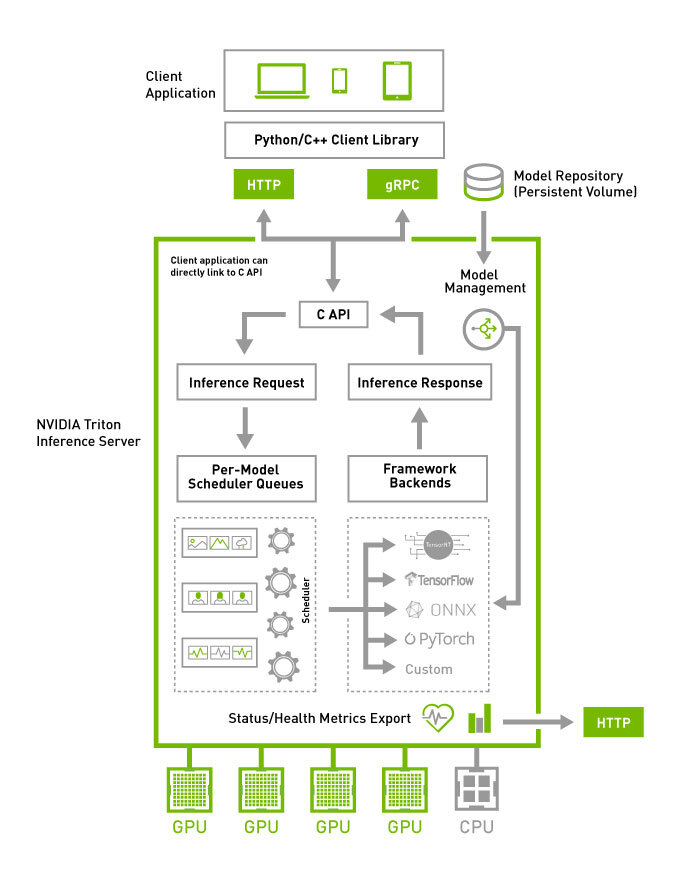
上の図は本プロダクトのアーキテクチャ図のうち、推論サーバー周辺のものを抜粋したものです。 特徴的なのは、広告LP制作だけでなく配信まで行うというプロダクトであるため、主なサービス(バックエンドやフロントエンド、配信用ビルドサーバー、その他)はTypeScriptで実装しています。
一方でデータサイエンティストや機械学習エンジニアの環境ではPythonを使うことが多いです。 推論サーバーはこうした異なる環境から異なる利用のされ方をすることになります。
最後にプロダクト開発チームの体制について。 弊社のAI事業本部、特にAIクリエイティブ領域では、多くの場合はプロダクト単位で数名から数十名規模という比較的小規模な開発チームを構成しており、またそれぞれのチームにデータサイエンティストやリサーチエンジニアのような役割を担うメンバーが在籍しています。
また、同じ事業部内には CyberAgent AI Lab という研究組織もあります。 プロダクト側と研究側それぞれには異なるミッションがありますが、たとえば問題設定段階での相談や外部研究機関との共同研究、そして実際の広告制作データや配信実績データについて相互に協調しています。 プロダクト側にも研究開発を遂行できるメンバーがいるため、プロダクション化だけをプロダクト側がやるという一方向のフローではない点は、個人的には動きやすいです。 たとえば、Slack上のカジュアルな会話から共著で論文を書くプロジェクトが発生することもあり、組織の壁を感じることはないという印象です。
……なにやら広告っぽくなってきたのでこのあたりで次の内容に移ります。
はじまり: ナイーブな推論サーバー
立ち上げからしばらくは、Python言語のウェブサーバーフレームワークであるFastAPIで実装した推論サーバーを利用していました。 内部ではPyTorchなどの深層学習フレームワークを用いて推論実行を行うという簡単なつくりです。
当初から複数のモデルを利用することを想定して、リポジトリ上でモデル定義を管理する仕組みや簡易的なバージョニングの仕組みも用意していました。
嬉しい悲鳴: スケールについていけない?
(これは完全に良いことなのですが)事業がスケールし始めメンバーが増えて色々な機能や手法の応用を考え出すフェーズになったとき、推論サーバーに対するワークロードが急に厳しくなってきました。 モデル数やそのスケール(パラメータ数)とリクエスト数が当初より急に大きくなりました。
特に当時検証中であった「とある新機能」により、広告デザイナーがインタラクティブに利用中にもバッチ予測寄りの性質の大量の推論リクエストが発生することになったことが主因です。
これに対して推論サーバーのデプロイ構成変更やサーバーのパラメータ調整による対応を頻繁に行っていました。 具体的には、用途別に推論サーバーの Node Pool や Replica Set を分けたり、GPU 対応 Node Pool を用意したり、Ingress (L7LB) の Balancing rule を確認したり、Horizontal Pod Autoscalerが反応する条件を変えたり、FastAPI(というかUvicorn)のパラメータを調整したり、GunicornとUvicorn Workerのパラメータを調整したり……という試行錯誤をしていました。
当時のcommitを見ると、n1-standard-16 インスタンスを24ノードまでオートスケールさせつつ、Replica Setは256までオートスケールするようにしていました2。 CPUインスタンスであっても結構なコストになってきていました。
いちばんの問題は処理時間のばらつきでした。 この対応中、ネットワーク周りも含めた全体の推論実行時間の分布を見て評価をしていたのですが、試行錯誤してもレスポンスが返ってくるまでの時間のばらつきは大きく、広告LP制作ツールのUXにとっても、また大規模バッチ処理の安定性にとってもなかなか厳しい状況でした。
パフォーマンス面以外の課題: 推論サーバーのAPIと責務の話
推論サーバーとその周辺のサービスの関係性について、少し寄り道をさせてください。 事業の方針が明確化するとともにプロダクトのコードベースは(ときに紆余曲折を経て)成長・成熟していきます。そして最適(だと思う)設計も変わっていきます。 推論サーバーにおいても、プロダクトのスタート当初から想定されつつもうまく実現できていなかった問題が顕在化しはじめていました。 特に、推論APIや前処理・後処理の責務をどこに持たすかという2つの問題です。
まずは推論APIについて。 先に述べたとおりこのプロダクトでは JavaScript/TypeScript 系の技術スタックが主に利用されています。 推論APIについては利用経験があった TensorFlow Serving の API に似せた構造にしていました。といっても、実際に授受されるペイロードについては場当たり的な定義になっていて、また、TypeScript 実装のバックエンドサービスと Python 実装のサービスとでスキーマをうまく共有するところでは苦労が多かったです。 FastAPI の機能で OpenAPI 定義を生成することができますし、OpenAPI 定義からのコード生成ツールもいくつかあります。しかし、TypeScript への対応度合いや使用しているフレームワークとの兼ね合いで、推論サーバーが扱うようなシンプルな API の場合は結局別々に実装するほうが楽でした。
そして責務の境界について。 このプロダクトでは画像や可変長のテキスト、あるいはページや広告自体のメタデータなど、マルチモーダルで多様なデータ構造を推論時に扱います。 研究開発時に用意した前処理コードが想定している入力に変換するために、バックエンドサービス側で TypeScript で前処理のための前処理を実装する……というように、推論サーバーを利用するサービス側でも機械学習モデルのことを意識したコードが混入しはじめていました。 バックエンドはよくあるレイヤードアーキテクチャに近い形になっているので、直接の影響は大きくはないものの、ドメインモデルを扱うべきレイヤーにもそうしたコードが見え隠れするようになってきました。
もう少し細かく、しかし機械学習パイプラインとしては致命的かもしれない困りごとの例を挙げます。 研究開発時に実装した前処理では TorchVision や Pillow を使って画像を処理していた一方、プロダクション化の際には Sharp.js を使って同様の処理を実装しようとしたことがあります。 ベースとなっているライブラリ群 (libjpeg, libpngなど?) は同等であったとしても、ちょっとしたフィルタ処理のパラメータの意味やデフォルト値が異なる場合があり、推論結果に微妙な差が生じることがありました。 二度手間なうえに結果も異なる可能性がある、というのは完全に設計でミスをしたと反省しました。
Triton Inference Server の概略
Triton Inference Server は NVIDIA が中心となって開発している推論サーバーのOSS実装で、複数の機械学習フレームワークの推論実行に対応したサーバーを提供するものです。
以下のとおり主流のフレームワーク(モデルフォーマット、ランタイム含む)に対応しています3。
- PyTorch
- TensorFlow
- TensorRT
- OpenVino
- ONNX
複数フレームワーク・ランタイムへの対応とともに特徴的なのは、Triton Inference Serverは推論サーバーとしての機能が豊富な点です。
- C/C++実装の高速で堅牢な推論サーバー
- k8sからエッジ向けまでさまざまな環境を想定
- KServe API準拠のgRPC/HTTP API
- 内包する各モデルへの推論リクエストに対するスケジューリング機能
- 前処理・後処理等のための簡易的なパイプラインのDAG記述 (“Ensemble scheduler” というちょっとややこしい名前)
最後に、コンテナとしてのデプロイを念頭に置いた設計になっている点も付け加えておきます。 コンテナイメージを用いる利点のひとつとしての環境の再現性や可搬性についてですが、Triton Inference Serverは研究開発の段階でよく利用する NVIDIA NGCの各種コンテナイメージ群 と同様のバージョンや構成の仕様となっている点が都合がよかったです。
デプロイの面では、現在ではAWS SageMaker やGCP VertexAI PredictionなどのマネージドMLサービスでの利用もサポートされています。
公式リポジトリにHelm Chartが用意されている のでk8s上へのデプロイもしやすいと思います。
今すぐ使ってみたい方へ
Quick Start ガイド が公式リポジトリに用意されています。 先に挙げた機能はそれぞれ細かい粒度で example が提供されているのですが、より実用時の雰囲気に近いかもしれない例を本記事末尾に付録として記載していますので、よろしければどうぞ。
類似の推論サーバー実装とTriton Inference Server選定の理由
ちなみに、似たような汎用的な推論実行ランタイム兼サーバー実装としては ONNX Runtime4, TensorFlow Serving, TorchServe なども挙げられます5。
これらは複数モデルの実行をサポートしていたり、(KServe Inference APIを含め)gRPC/HTTP API を持ち簡易 DAG 記述を備えている点では Triton Inference Server に近い機能を備えています。 バージョンタグによる振り分けを利用したA/Bテスト風の機能など、特徴的な差分もあります。
しかし本事例の検討時点ではこれらの機能は現状とは異なっていたことや、またこのチームでは研究開発段階ではチーム内でも AI Lab との協調においても複数の深層学習フレームワークを利用するという条件もあり、これらの採用は見送りました67。 これらの多くは KServe API 準拠の API を備えているので、今後もし移行する際にもそれほど苦労しないかもしれないと考えています。
ここまで書いて忘れていましたが、k8s環境であれば KServe を利用するのも有力な選択肢かもしれません。 機械学習モデルの推論実行環境がk8sのCRDとして記述されていることで、k8sとの親和性が高いのはメリットです。 しかし、Kubeflow 自体を既存の Cluster へ導入し、技術スタックに加えてメンテナンスしていくことは、小規模なチームにとっては負担が大きいと判断しました。 マネージドサービスではどうか、という点では本プロダクトでは Vertex AI Pipelines をはじめとして Kubeflow の検証もおこなっていました。当時 alpha 版であった Vertex AI の機能セットは既存のワークフローを移植するには不十分で、またマルチモーダルな問題設定でそれなりに大きめのモデルを利用する都合上、統合的なパイプラインや推論環境よりも、Custom Container TrainingとTriton Inference Serverによる推論実行に落ち着くだろうという答えになりました。
深層学習モデルの推論実行基盤のみであれば、技術スタック的にも開発者のリソース的にも自前GKEクラスタを持つよりGPUが使えるCloud Runがあれば良いのかもしれません。 仮にそうなった場合でも Triton Inference Server や類似アーキテクチャで設計された推論サーバー実装を利用すれば、その恩恵は受けられるという将来的な期待もあります。
Triton Inference Serverを導入する
まず簡単に導入時の方針を書いておきます。
今回の問題は主に推論サーバーのスケジューリングやGPUリソースの共有に関する問題だったため、モデル自体の最適化はこの段階ではやらずに、簡単にPyTorchからTorchScript化できるモデルは pytorch (LibTorch) backend での実行へ移行させ、論文実装の時点で複雑な前処理・後処理が含まれているものは python backend で実装して、移行の可否を検証することを優先しました。
デプロイに関しては先に述べたとおり、公式リポジトリで提供されている Helm Chart の例をベースに、k8s の resource を定義していきました。 執筆時点では、GKE の Ingress NEG での Pod レベルの負荷分散は gRPC に対応していない8 ため、Cloud Load Balancing によるL4 LBを使用することにしました。 PodレベルではなくNodeレベルですが、今回の事例でのTriton Inference Serverのユースケース上、1Pod/Node という構成でも問題ない9 です。
つぎに、クライアント側を Triton Inference Server の gRPC API に対応させる方法について。 Python実装のサービスについては Protobuf からコードを生成しなくても tritonclient というクライアントライブラリが提供されているので、こちらを使うのがおすすめです。 Numpy, PyTorchとのTensorの相互変換のようなユーティリティが実装されていて、単にgRPCクライアントを生成するより使い勝手がかなり良くなっています。
一方、TypeScriptについては Triton Inference Serverの Protobuf からコード生成することになります。 Client実装のリポジトリ にあるとおり、C++, Python, Javaについては(自動生成だけではない)実装が提供されています。 公式リポジトリで提供されているJavaScript向けのClientコード生成の例 は実用上不十分なので、別途調査してTypeScript向けにコードを生成するとともにユーティリティを追加してNPMパッケージ化しました。 TypeScript向けのClientコード生成の話題はこちらに書いています。
評価
Triton Inference Serverを導入してどうだったか、という評価に入ります。 結果としては(僕は)大満足です。
の分布")
このプロットは推論実行速度(実環境のネットワークレイテンシー等を含む)の分布です。横軸のスケールは都合によりマスクしています。 推論サーバー単体での比較ではなく実際の環境で比較しているため、デプロイ条件は異なります。 Python+FastAPI実装の旧推論サーバーはk8s上で16Nodes, 256Podsまでオートスケールさせている一方、Triton Inference Serverは2 Nodes, 2 Podsで動かしています。 推論サーバーのインスタンス数はかなり異なるものの、十分なパフォーマンスが出ていました。
実際にはその後も 負荷試験ツール k6 や Performance Analyzer を用いた詳細なスケジューラーのパラメーター調整や、Node.js 側の GC の調整などを継続的におこない、推論時のパフォーマンスを向上させています。
技術選定の観点ではどうだったか。今回はパフォーマンス面での優劣が移行の理由となりましたが、導入時の学習コストや継続的なメンテナンスコストなども考慮に入れていました。 考慮に入れたとはいえ、少人数かつ異なる専門性のエンジニアで構成されたチームではこうした点を比較しにくく、その機能やサービスや技術領域を担当するメンバー(今回は自分)のバイアスがかかってしまう点は否めません。
学習コストやその後の開発体験についてはあくまで感覚的なところではありますが、書いてみます。 まず、学習コストに関しては、Triton Inference Server はドキュメントやサンプル実装は多く提供されているため、学習リソースは十分だと思います。一方、元の KServe API との差分(たとえば推論結果の値は raw_output_contents にバイナリで格納される)のように、実際に利用する際には必ず直面する課題が見つけにくい場合があるので、ソースコードや Issue を漁る必要はかなり感じました。OSSの推論基盤の良いところでもあります。
また、開発体験については良し悪しあると思っています。 推論サーバーの実装が提供されていることで、深層学習モデルそれ自体とその入出力テンソルに近いところだけを触ればよい、というコンテキストの分離ができるのはよかったです。 あまり必要が感じられない「たらい回し」的な推論APIサーバーを書いたりメンテしたりなくてもよくなったことで、注力すべき問題に集中できるので。 一方、前処理・後処理などのコードを移植する際に NGC Container 内の各種ライブラリとのバージョンの差異に起因する問題を見つけるのは、それなりに面倒でした。
しかしパフォーマンス面でのメリットはこれらを帳消しにして余りあるように思います。 現在は、今回紹介した事例に比べてさらに推論基盤に課せられる要件が厳しくなっているものの、その対応はかなり楽になっています。
以下に、この事例について良かったと感じたところと、まだ改善が必要なところをまとめます。
良かったこと
まず、ポジティブなところから。たくさんあってうれしいですね。
- 当時のパフォーマンスまわりの悩みが解決した。
- 現在はさらに要件が厳しくなったものの、スケールアップ・スケールアウトがしやすい基盤となったため、対応がしやすくなった。
- 研究開発寄りのメンバーと実運用化寄りのメンバーとで、やることの境界が明確になった。
- たとえばリサーチエンジニアはTorchScriptやONNX形式に正しく出力するところまで、MLエンジニアは前処理・後処理含めたモジュール化とモデル本体のTritonへのデプロイ、という感じになる。
- 最近活発に利用されているHugging Face Hub のように、可搬性とデプロイ容易性がある程度保たれた形式に変換できるようなモデルにしておくと、研究側・開発側ともにうれしい。
- 前処理や後処理をモジュール化して推論サーバー側に持たせることができたため、バックエンドサーバーではドメインモデルだけを考えれば済むようになった。
- 推論APIやペイロードのデータ構造に悩む必要がなくなった。
- GunicornやUvicornのパフォーマンスチューニングに悩まなくて良くなった。
- GPU利用時のボイラープレート的なコードがなくても安全に複数モデル間でGPUを共有できるようになった。
- 複数の深層学習フレームワークを共存させるコンテナイメージのビルドで苦労することがなくなった。
- 複数のモデルを安全に動かせるようになった。
- デプロイ環境のバージョンと依存関係の仕様が安定するようになった。
- gRPCにより通信の効率が良くなった(たぶん)。
- gRPC, 特にコード生成まわりのことがちょっとわかって楽しかった。
やり残したこと、改善したいこと
一方で、まだ改善すべきことは残っています。やりたいこと、興味があるトピックも数多くあります。
- 技術スタックが重くなってしまった。特にgRPCの作法とKServe/Triton独自の仕様が研究者には学習コストが高いかも。
- モデル定義やNVIDIAコンテナイメージなどの各種制約を把握する必要がある点は、モデルの単体でのリリースにも活用できる知識なので(少なくとも自分が)研究をやるときには無駄にはならないとは思います。
- 一方、gRPCまわりに関しては研究開発における技術スタックとはギャップがある気がします。
- Python backendを利用して実験用スクリプトをそのまま動かすことは可能ですが、それでもTriton Inference Serverの仕様に合わせたモジュールとしてラップしなくてはならないため、気軽ではないかもしれません。
- コンテナイメージの容量は依然として大きいまま。
- PyTorch (LibTorch) のみ、TensorFlowのみ、という場合であれば少し容量の小さいバージョンのイメージも提供されています。
- 6GB ~ 10GBという容量をどう考えるか……。
- GKEの場合、Image Streamingを使うことでNodeのメモリ使用量と引き換えにpullを高速化できる とのことですが、劇的な差は感じられませんでした。
- 推論実行のためのモデル自体の高速化はまだできていない。
- パフォーマンス面を考えると、TorchScriptより推論用ランタイムの最適化度合いが高いTensorRT backendやONNX Runtime形式にするのが良いかもしれません。
- 特にONNX向けのモデル変換については弊社 AI Labの兵頭さんがその深淵に迫っています。
- リアルタイム・エッジ向けとは制約の厳しさが異なるかもしれませんが、それでもモデル最適化は有効な手段なので、改善幅の大きいところから試していきたいですね。
- 汎用的な技術だと思うのでMLOpsに関する一事例として他のプロダクトにも共有していきたい。
まとめ
この記事では深層学習モデルの推論サーバーとしてTriton Inference Serverを導入したという事例を紹介しました。 これ自体は当時抱えていた課題が改善され、現在も進む事業スケールの発展に対して対応できている点ではとても満足いく結果となりました。 一方で、もう少しスコープを広げて考えると課題はたくさん残っています。
機械学習・深層学習を利用したプロダクトにおいては、推論サーバーはある意味で中心部分にはいるものの、全体として機能を果たすにはデータパイプラインやオンライン実験管理基盤、場合によっては人手によるアノテーションを用いた学習データ収集および評価の仕組みまで広げて、MLOpsの観点から考えることが必要だと思っています。 この記事では触れていませんが、そうした技術的施策も進めています。
うまくいったとき、あるいは意味のある失敗をした場合は、また記事にしたいと思います。
(付録)Triton Inference Serverを使ってみよう
tuxedocat/triton-client-polyglot-example というサンプルリポジトリを用意しました。 ここからはリポジトリ内のコードを用いて説明していきます。
ここでは Triton Inference Server の特徴である機能をカバーする事例として、OpenAI CLIP という現在 “Vision and Language” 深層学習分野においてよく参照・利用されるモデルをデプロイすることを試みます。 CLIPを選んだ理由はその研究上のインパクトや汎用性だけでなく、(1)画像とテキストのマルチモーダルな入力とそれらの前処理が必要である点、(2)最近の実用的なモデルのなかでもサンプルとしてちょうどよいスケールと複雑さである、(3)実ユースケースでは埋め込みベースの画像検索のインデックス構築などの大規模な推論ワークロードが想定される、という点で推論基盤のデモにはぴったりだと思うからです。
本サンプルの開発環境など
このサンプルは以下の環境で作成して動作を確認しています。
- 開発環境(※exportや推論サーバーの実行はコンテナ上で行なっています)
- OS: Debian 10.13 (Linux kernel 4.19.0-22-cloud-amd64)
- コンテナ実行環境: nvidia-docker 2.10.0
- NVIDIA GPU Driver: 515.48.07
- Export時のNotebookコンテナのベースイメージ:
nvcr.io/nvidia/pytorch:22.10-py3- Ubuntu 20.04 x86_64
- CUDA 11.8.0, cuDNN 8.6.0
- Python 3.8
- PyTorch 1.13.0a0+d0d6b1f
transformers==4.24.0(via pip)sentencepiece==0.1.97(via pip)
- Triton Inference Serverのベースイメージ:
nvcr.io/nvidia/tritonserver:22.10-py3- Ubuntu 20.04 x86_64
- CUDA 11.8.0, cuDNN 8.6.0
- Python 3.8
- PyTorch 1.13.0 (via pip)
transformers==4.24.0(via pip)sentencepiece==0.1.97(via pip)
- Client例
tritonclient[grpc],numpy,pillow,typerが動作するバージョンのPython処理系であればOK
Triton Inference Serverの “model repository”
本論に入る前に、まずは Triton Inference Server においてどのようにモデルを準備するかについて触れます。
Triton Inference Server上で機械学習・深層学習モデルを動かすには、以下のような構造でモデルを定義します:
model_repository/
MODEL_NAME/
# 1. モデル定義
config.pbtxt
# 2. 各バージョンのモデル重みやPython backendの実装
# VERSIONは1以上の整数ID
VERSION/
model.(onnx|pt|trt|py)各モデルは “model repository” というディレクトリ内に配置されます。 また各モデルはProtocol Buffer Text形式で書かれた定義と、それぞれのバージョンの重みあるいは実装スクリプトに分離されています。
CLIPをONNX形式に変換する
ここでは Hugging Face Transformers / CLIP をTriton Inference Serverにデプロイしてみます。 オリジナルのOpenAI/CLIPからでも変換は可能ですが、Hugging Face版ではONNX形式へ変換する際に便利なユーティリティや入出力などの設定 (CLIPOnnxConfig) が提供されているため、この例ではこちらを使用します。
Export to ONNX を参考にCLIPをONNX形式に変換します。
from transformers import CLIPProcessor, CLIPModel
from transformers.models.clip import CLIPConfig, CLIPOnnxConfig
from transformers.onnx import export
# モデルのロード
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
config = CLIPConfig()
onnx_config = CLIPOnnxConfig(config)
onnx_path = "clip.onnx"
onnx_inputs, onnx_outputs = export(processor, model, onnx_config, onnx_config.default_onnx_opset, onnx_path)無事に変換できたかどうかを確認します。 Netron というGUIのツールでONNX形式のモデルを眺めてみます。 問題なくONNXフォーマットの計算グラフが表示されることを確認できました。
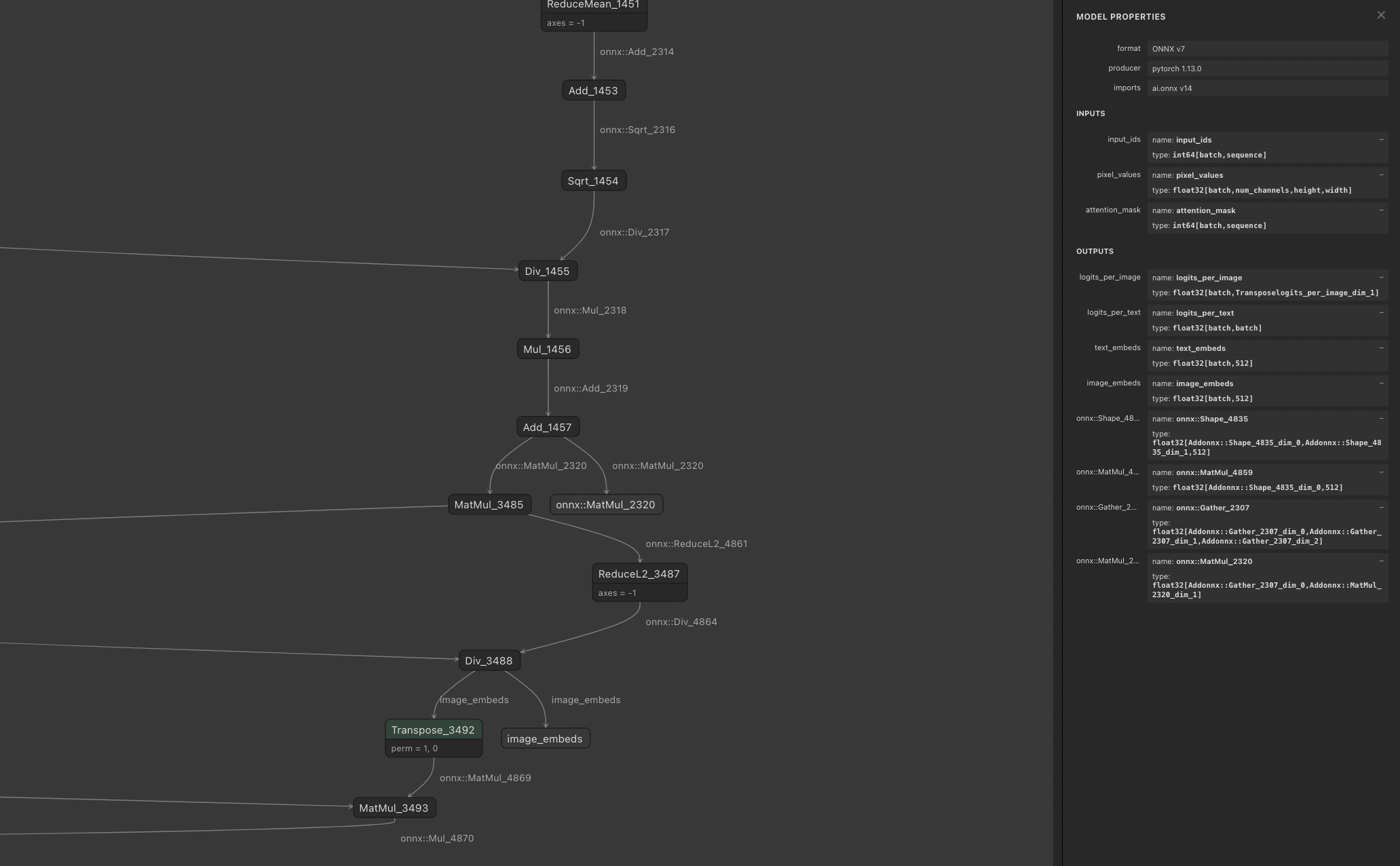
入出力のNode定義はTriton Inference Serverのモデル定義を書くときに必要になるのでメモしておきましょう。
- 入力
- 画像
name: pixel_values type: float32[batch,num_channels,height,width]- テキストのSubword ID
name: input_ids type: int64[batch,sequence]- テキストのAttention Mask
name: attention_mask type: int64[batch,sequence] - 出力
- 画像の埋め込み
name: image_embeds type: float32[batch,512]- テキストの埋め込み
name: text_embeds type: float32[batch,512]
当然ですが、ONNX形式のモデルはONNX Runtimeで単体で実行可能です。 CLIPProcessor による画像とテキストの前処理が必要な点に注意しつつ、ONNX Runtimeでの推論実行をしてみます。
import onnx
import onnxruntime
onnx_model = onnx.load("clip.onnx")
onnx.checker.check_model(onnx_model)
# 適当な画像がPIL.Imageあるいはnumpy.arrayになっているとして
# 前処理をおこない、画像やサブワードID列, Attentionを得る
inputs = processor(
text=["a photo of a cat", "a photo of a dog"],
images=image,
return_tensors="np",
padding=True)
session.run(output_names=['text_embeds', 'image_embeds'], input_feed=inputs.data)
# 画像・テキストそれぞれの[batch_size, 512] のTensorが得られるCLIPのモデル定義を書いてみる
まずはCLIPのencoder本体(Transformer LMとViT)を clip-core として定義してみます。 config.pbtxt に表れるTriton Inference Serverの設定やデータ型についてはTritonのモデル定義のドキュメント を参照してください。
name: "clip-core"
backend: "onnxruntime"
platform: "onnxruntime_onnx"
max_batch_size: 128
# 自動batch化を有効にする
# このとき各入力・出力の次元は batch_size の次元が増える
# オプションはドキュメントを参照のこと
dynamic_batching {
# 例: 100ms 単位で自動バッチ化する場合
max_queue_delay_microseconds: 100000
# 例: タイムアウト時にリクエストを破棄する場合
default_queue_policy {
timeout_action: REJECT
allow_timeout_override: true
default_timeout_microseconds: 5000000
}
}
# 重みファイルを 1/clip.onnx, 2/clip.onnx のように配置する
default_model_filename: "clip.onnx"
input [
{
name: "pixel_values"
data_type: TYPE_FP32
# ONNX側は float32[batch,num_channels,height,width] のように可変次元のTensorに対応している
# ここではRGB画像に限定している
dims: [ 3, -1, -1 ]
},
{
name: "input_ids"
data_type: TYPE_INT64
# このCLIP text encoderは77 tokenまでだが
# ONNXモデルの入力自体は可変長となっている
dims: [ -1 ]
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
output [
{
name: "text_embeds"
data_type: TYPE_FP32
dims: [ 512 ]
},
{
name: "image_embeds"
data_type: TYPE_FP32
dims: [ 512 ]
}
]
instance_group [
{
count: 1
# GPUが使用可能なときはGPUを利用する
kind: KIND_AUTO
}
]これ自体だと結局Client側で画像やテキストの前処理が必要となってしまいます。 ここでTriton Inference Serverの “Ensemble scheduler” という簡易ワークフロー記述機能を使います。
まず、CLIPProcessor による前処理をPython backendのモデルとして記述します。
name: "clip-preprocess"
backend: "python"
max_batch_size: 128
dynamic_batching { }
input [
{
# Base64化された画像が渡される例
name: "BASE64IMAGE"
data_type: TYPE_STRING
dims: [ 1 ]
},
{
name: "TEXT"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
# CLIPProcessorの出力の型に合わせる
output [
{
name: "IMAGE_NCHW"
data_type: TYPE_FP32
dims: [ 3, -1, -1 ]
},
{
name: "SUBWORD_IDS"
data_type: TYPE_INT64
dims: [ -1 ]
},
{
name: "ATTENTION_MASK"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
instance_group [
{
count: 1
# CPUのみ使用する例
kind: KIND_CPU
}
]Python backendのモデルは config.pbtxt に加えて、その仕様に沿ったPython実装 を用意する必要があります。 以下のsnippetは例として最低限の記述に絞っています。
import triton_python_backend_utils as pb_utils
import json
import numpy as np
import numpy.typing as npt
from PIL import Image
from io import BytesIO
import base64
from transformers import CLIPProcessor
from pathlib import Path
def load_image(b64bytes: bytes) -> Image.Image:
return Image.open(BytesIO(base64.b64decode(b64bytes))).convert("RGB")
def decode_string(byte_array: npt.NDArray) -> str:
return "".join([b.decode("utf-8") for b in byte_array])
class TritonPythonModel:
def initialize(self, args):
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def execute(self, requests):
responses = []
for request in requests:
img_batch = [
load_image(b64bytes)
for b64bytes in pb_utils.get_input_tensor_by_name(
request, "BASE64IMAGE"
)
.as_numpy()
.astype(np.bytes_)
]
txt_batch = [
decode_string(byte_array)
for byte_array in (
pb_utils.get_input_tensor_by_name(request, "TEXT")
.as_numpy()
.astype(np.bytes_)
)
]
inputs = self.processor(
text=txt_batch, images=img_batch, return_tensors="np"
)
image_out = pb_utils.Tensor(
"IMAGE_NCHW",
inputs.data["pixel_values"].astype(np.float32),
)
subword_out = pb_utils.Tensor(
"SUBWORD_IDS",
inputs.data["input_ids"].astype(np.int64),
)
attn_out = pb_utils.Tensor(
"ATTENTION_MASK",
inputs.data["input_ids"].astype(np.int64),
)
inference_response = pb_utils.InferenceResponse(
output_tensors=[image_out, subword_out, attn_out]
)
responses.append(inference_response)
return responses
def finalize(self):
passここで transformers パッケージが利用されていますが、Triton Inference ServerのDockerイメージには含まれていません。 このようにPython backendで必要な追加パッケージがあるときは、いくつかの方法で対応できます。 簡単なのは以下のように直接パッケージを追加する方法です。Python backendで複数のモデルが稼働したり衝突しうる複雑な依存関係を扱わない場合は楽です。 PyTorchも依存関係に入れているのは、Triton Inference ServerのデプロイイメージにはLibTorchしか含まれていないからです。
実用上はPython処理系のバージョンにも注意する必要があります。 そうした情報は NVIDIA NGCの各種コンテナイメージのバージョン仕様 で確認します。 現状最新の r22.11 であってもPython 3.8系なのが地味につらいとこです10。
またとても細かい点ですが、このベースイメージのPyTorchはPyTorchの公式リリース版とは異なりNVIDIAのパッチが当たったバージョンである場合があります。 たとえばこれはCLIPとは別のモデルに関するIssueですが、GELUの内部実装がエクスポート時に使用するPyTorchとTriton Inference ServerのLibTorchとで異なっていることで、推論サーバーの起動時にエラーとなる例です。 可能であればTorchScriptのJITトレース時には Triton Inference Server と同じようにNVIDIAが提供するPyTorchのイメージを利用すると、こうした問題を回避できるのでおすすめです。
ARG TRITON_IMAGE_TAG=22.10-py3
FROM nvcr.io/nvidia/tritonserver:${TRITON_IMAGE_TAG}
ENV PYTHONUNBUFFERED 1
ENV PIP_NO_CACHE_DIR 1
ARG HUGGINGFACE_VERSION=4.24.0
ARG PYTORCH_VERSION=1.13.0
RUN pip3 install \
opencv-python-headless \
"transformers~=${HUGGINGFACE_VERSION}" "sentencepiece~=0.1.97" "torch~=${PYTORCH_VERSION}"つぎに、CLIPの本体 clip-core と前処理 clip-preprocess を “Ensemble scheduler” を用いてパイプラインとして統合します。 利用する側から見たらこうして統合されたパイプラインも単体と同じように利用できますが、そのモデル定義は少し異なっています。
name: "clip"
platform: "ensemble"
max_batch_size: 128
# Ensembleを利用する際は自動batchingはそれぞれの内部モデル側で処理される
# dynamic_batching { }
input [
{
# Base64 encoded image
name: "BASE64IMAGE"
data_type: TYPE_STRING
dims: [ 1 ]
},
{
# UTF-8 encoded text
name: "TEXT"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
output [
{
name: "IMAGE_EMB"
data_type: TYPE_FP32
dims: [ 512 ]
},
{
name: "TEXT_EMB"
data_type: TYPE_FP32
dims: [ 512 ]
}
]
# 個々のモデルの入出力を繋ぎ合わせてパイプラインを構成する
ensemble_scheduling {
step [
{
model_name: "clip-preprocess"
model_version: -1
input_map {
key: "BASE64IMAGE"
value: "BASE64IMAGE"
}
input_map {
key: "TEXT"
value: "TEXT"
}
output_map {
key: "IMAGE_NCHW"
value: "image"
}
output_map {
key: "SUBWORD_IDS"
value: "subword_ids"
}
output_map {
key: "ATTENTION_MASK"
value: "attention_mask"
}
},
{
model_name: "clip-core"
model_version: -1
input_map {
key: "pixel_values"
value: "image"
}
input_map {
key: "input_ids"
value: "subword_ids"
}
input_map {
key: "attention_mask"
value: "attention_mask"
}
output_map {
key: "text_embeds"
value: "TEXT_EMB"
}
output_map {
key: "image_embeds"
value: "IMAGE_EMB"
}
}
]
}これでモデルが定義できました。この時点で model_repository/ ディレクトリはこのようになっています。
model_repository/
├── clip
│ ├── 1
│ └── config.pbtxt
├── clip-core
│ ├── 1
│ │ └── clip.onnx
│ └── config.pbtxt
└── clip-preprocess
├── 1
│ └── model.py
└── config.pbtxt推論サーバーを動かしてクライアントから推論実行を試みる
準備はできたのでTriton Inference Serverを起動しましょう。
# 先のDockerfileでイメージをビルドしてあるとして...
docker run --rm -it --name triton-example-server \
--runtime=nvidia --gpus=1 \
--shm-size=1g --ulimit stack=67108864 \
-p 8000:8000 -p 8001:8001 -p 8002:8002 \
-v $(realpath ./model_repository):/model_repository \
triton-example:22.10 \
tritonserver \
--disable-auto-complete-config \
--strict-readiness=true \
--exit-on-error=true \
--model-repository=/model_repository \
--model-control-mode=explicit \
--load-model=clip \
--load-model=clip-preprocess \
--load-model=clip-core \
--log-verbose=1確認用のClientを書いてみます。 CLIPは画像とテキストを同じ空間に埋め込むことができます。 これは画像とテキストを入力すると、それらのCLIP埋め込みのCosine類似度を出力するという簡単な例です。
#!/usr/bin/env python3
import numpy as np
import numpy.typing as npt
from pathlib import Path
import tritonclient.grpc as triton_client
from io import BytesIO
import base64
import typer
import logging
from typing import Tuple
from PIL import Image
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__file__)
def get_clip_embs(
endpoint: str,
image_path: Path = typer.Option(Path("input.png"), help="input image"),
input_text: str = typer.Option("hello猫"),
batch_size: int = typer.Option(8),
) -> Tuple[npt.NDArray, npt.NDArray]:
img = Image.open(image_path).convert("RGB")
# 少し迂遠ですがTriton側の型に合わせるため画像をBASE64エンコードし文字列に変換します。
# Pillowは `data:image/png,` のMIME文字列をサポートしないので入っている場合は削除しておきましょう。
with BytesIO() as f:
img.save(f, "png")
f.seek(0)
b64img = base64.b64encode(f.read())
# この例では意味はありませんが、Triton側のモデルはミニバッチ推論に対応しているので
# 単純に同じ事例を複製してミニバッチを構成しています。
# 実用時には推論パフォーマンスとペイロードサイズとの兼ね合いでバッチサイズを調整します。
img_batch = (
np.array([b64img for i in range(batch_size)]).astype(np.bytes_).reshape([-1, 1])
)
txt = np.array([bytes(input_text, encoding="utf-8")], dtype=np.bytes_)
txt_batch = txt[np.newaxis, :]
txt_batch = np.repeat(txt_batch, batch_size, axis=0)
img_input = triton_client.InferInput("BASE64IMAGE", img_batch.shape, "BYTES")
img_input.set_data_from_numpy(img_batch)
txt_input = triton_client.InferInput("TEXT", txt_batch.shape, "BYTES")
txt_input.set_data_from_numpy(txt_batch)
inputs = [img_input, txt_input]
with triton_client.InferenceServerClient(endpoint) as client:
response = client.infer("clip", inputs, outputs=None)
result = response.get_response()
# PythonのtritonclientはこのようにNumpy arrayに変換してくれます。
# 一方、JavaScriptのようにgRPCからclientを生成する場合は
# `response.outputs` にあるそれぞれの出力の型に応じて
# `response.raw_output_contents` を適宜 decodeする必要があります。
txt_emb = response.as_numpy("TEXT_EMB")
img_emb = response.as_numpy("IMAGE_EMB")
logger.info(f"Shape: {txt_emb.shape, img_emb.shape}")
cossim = np.dot(txt_emb[0], img_emb[0]) / (
np.linalg.norm(txt_emb[0]) * np.linalg.norm(img_emb[0])
)
logger.info(f"Cosine Similarity: {cossim}")
return txt_emb, img_emb
if __name__ == "__main__":
typer.run(get_clip_embs)ここで下の猫の写真11とテキストの類似度を測ってみましょう。

$ ./example_clip.py localhost:8001 --image-path tabby-cat.png --input-text "tabby cat"
...
Cosine Similarity: 0.260699987411499
$ ./example_clip.py localhost:8001 --image-path tabby-cat.png --input-text "shiba dog"
...
Cosine Similarity: 0.18734708428382874どうやらちゃんと動いているようです。
(おわり)
- データサイエンティスト職となっていますが、最近は機械学習システム、MLOpsまわりの設計や実装の割合が高い気がするので。優柔不断なのでどう名乗るのかいつも悩んでいます。↩︎
- Uvicorn/Gunicornのパラメータチューニングは諦めて、結局Worker数は1にして、k8s側でスケールアウトしようとしていた。↩︎
- ONNXおよびTensorRT形式のモデルが推論実行できるので、実質ほとんどすべてに対応?↩︎
- 比較するのであればONNX Runtime Serverが最も近いかなと思ったのですが、現在ではONNX Runtimeのうち推論サーバー機能については開発が停止しています。↩︎
- 他に Seldon core, BentoML, MLFlow Models などもありますね。これらは推論サーバーの実装というより汎用MLOpsフレームワークという様相であるため、本プロダクトでは取り回しの面で候補から外れました。All in Oneな環境も魅力的ですし、もちろんつまみ食い的にモジュール単位での利用も可能ですが、推論サーバー自体はTriton Inference Serverをバックエンドにしていたり、シンプルなAPIにとどまっていたりするなど、用途が異なる面もあるためです。↩︎
- 現在ではTorchServeはONNX RuntimeやTensorRT形式のモデルの実行にも対応しています。↩︎
- TensorFlow Servingではserving実行可能なモデルやバックエンドを”Servable”という抽象化で扱っていて、そこをカスタムすれば他のフレームワークのモデルも動かせますが、今回の用途だとすでに対応しているもののほうが都合が良かったです。↩︎
- Envoy Proxyを利用する方法 など。手間がかかりそうだなという印象でした。↩︎
- GPU Time-sharing や Multi-instance GPU を利用すれば、複数のPodでGPUリソースを共有できます。ただし、後者はA100インスタンスでのみ対応しています。その他GPUメモリの管理や演算ユニットのスケジューリングなど、まだ検証が足りていないため本番環境では利用していません。↩︎
- Python 3.8 はNGC以外にもVertex AIやGoogle Colabなどの機械学習研究開発環境で未だに使用されていることが多いバージョンの処理系です。他のサービスは3.10などの最近のバージョンを使っているのに……ということはよくあります。つらい。↩︎
- 昔イスタンブールに旅行したときにアヤソフィア寺院で出会った有名なキジトラ猫さんです。↩︎