
本記事は、CyberAgent Advent Calendar 2022 8日目の記事です。
はじめに
CIU (CyberAgent group Infrastructure Unit) の西北(@nishi_network)です。
普段はプライベートクラウドで使用しているデータセンターの運用やそれに伴う開発業務に従事しています。
今回は、サイバーエージェントのプライベートクラウド環境で利用されているデータセンターの運用とその課題について紹介していきます。
サイバーエージェントのデータセンター
サイバーエージェントではプライベートクラウド向けに5拠点を超えるデータセンターを運用しており、その中では1,000台を超える物理サーバーが稼働しています。CPUコア数としては85,000コアを超え、ストレージ容量は2PBを超える規模になっています。
これらのサーバー群はプライベートクラウド「Cycloud」として社内向けに提供しており、およそ180のプロジェクトが利用しています。

これらのプライベートクラウド環境で利用しているデータセンターは「CyberAgent group Infrastructure Unit」通称 CIU と呼ばれる、サイバーエージェントの様々な事業部を横断した組織が管理しています。
組織の詳細はこちらを御覧ください。
プライベートクラウドを支えるインフラエンジニア
CIU ではプライベートクラウド環境で利用しているデータセンターの運用だけではなく、社内のユーザーへ提供するためのサービスとしてOpenStackを用いた仮想化基盤やマネージドKubernetesやデータベース、GitHub ActionsのマネージドRunnerの開発・運用も行っています。
今回はサービスの開発・運用面での話はおいておき、CIUの中でも私が所属しているDCチーム(データセンターチーム)が行っているデータセンターの運用について紹介します。
安定して提供するために
プライベートクラウドを支えるインフラエンジニアとして最も重要と言えるのが、継続して既存の環境を安定運用することです。そのためには日々故障するサーバーとうまく付き合っていく必要があります。
CIUではサーバーの故障が発生した場合のフローとして、原因の切り分けは社員がリモートで行い、サーバーベンダーへの調査や現地の保守対応はデータセンターに常駐して頂いている協力会社の方に依頼する形を取っています。
これにより故障が発生した際に迅速に対応でき影響を最小限に抑えることが出来るほか、社員がデータセンターへ走る必要性が無くなり故障箇所の切り分けや対応に集中することができています。
このため、実は社員がデータセンターへ行く機会はかなり少なくなっています。
加えて、サーバーのリソース(=性能)が足りているかなど、状況を注視し必要に応じて増強のタイミングを決定することも重要な仕事の1つです。
プライベートクラウドの性質上、リソースを増強するにはサーバー機器を追加で購入する必要があります。
そのため、購入したサーバーが届くのを待つ必要があり1日や2日で増強することはできません。
さらに、昨今では半導体不足の中サーバーの納期が非常に伸びていることもあり、サーバーを購入してから届くまでに半年以上掛かることもあります。
このため、プライベートクラウドを支えるインフラエンジニアにとって、半年以上先のリソース需要を予測してサーバーの追加購入を計画していくことも重要な仕事の1つとなっています。

より長く運用していくために
もう1つ重要なのは、より長く安定運用を継続するために新しいハードウェアに対応していくことです。
ハードウェアは経年劣化や寿命などで何もしていなくても故障が発生するため、運用年数が長くなればなるほど故障のリスクが高まります。
また、サーバーベンダーによる保守年数にも限りがあったり、新しい製品が登場する中で販売終了となる製品も出てくるため、同じハードウェアを永遠に使い続けることは困難です。
最も遭遇しやすいケースとしては、リソースの増強を行いたいタイミングでこれまで購入していたサーバー製品が販売終了で入手できないなどのケースが挙げられます。この場合は新しい製品の購入を検討することになりますが、その前段階として製品の選定と検証作業を実施する必要があります。
ハードウェアとしての検証は様々な視点から行っています。一例を上げると、冗長電源が期待通りに動作するか実際に抜き挿しをしてテストを行ったり、CPUやディスクなどが正常に冷却できているか負荷試験を実施し、期待通りの動作を行っているか確認しています。
また、ソフトウェア面でも影響があります。
これまで使用してきたOSがサーバー製品に搭載されている新しいCPUをサポートしていない場合があるため、新しいサーバー上で正常に動作するとは限りません。
このような場合、これまで動作してきたシステムを新しいOS環境へ移植する作業を実施し、その上で従来通りの動作をしているか検証しています。
こういった作業は CIU の中でOpenStack環境を運用しているチームの方々と連携しながら行う場合もあります。
実際に発生したケースとしてはCentOSからUbuntuへのシステム移行などがありました。
長期間運用しているとこういったケースが増えてくるため、新しい製品の情報を継続的にキャッチアップし、必要に応じて検証や対応作業を実施することも重要な仕事の1つとなっています。
物理環境の難しさ
既存環境の増強を行う場合や新たにデータセンターを開設する場合、インフラとしての構成を決定することも重要ですが、物理面でも新たに追加する機器の設置位置や配線経路を決定する作業を行う必要があります。
こういった作業はファシリティ設計と呼ばれる部分で、CIUではファシリティ設計を行う際に次の項目を熟考しています。(一例)
・電力量
・機器本体の重量
・ラック内で干渉等が発生しないか
・その他制限で設置不可ではないか
最も判断しやすい要素として、電力面での制限が挙げられます。ラック内で使用可能な電力量は契約電力やその他制限によって決まっているため、搭載したい機器を搭載しても電力量の超過が発生しないか確認しています。特に昨今では1サーバーあたりの消費電力は増加傾向にあり、電力管理は重要な要素になってきています。
また、機器本体の重量も重要な要素です。重量のある機器をラック上部に設置するのは困難であり作業にも危険が伴うため、極力回避するようにしています。
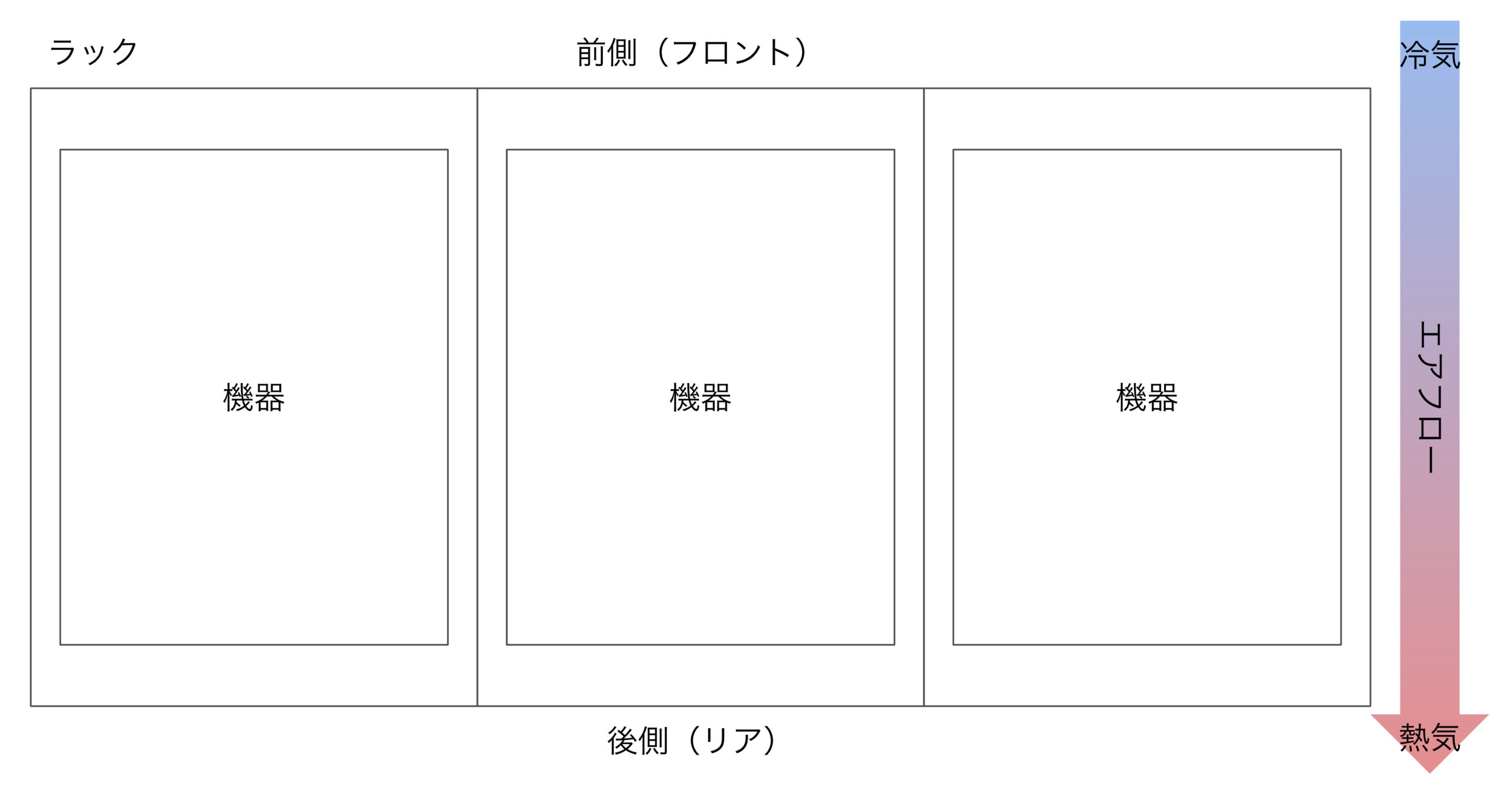
加えて、意外と見落としがちなのがラック内での干渉が原因で想定通りの位置に設置できなかったり、保守対応時に問題が生じるケースです。
特に、ストレージアプライアンスなどで多く見られる本体後ろ側からノードを抜き取るような製品の場合、設置するラックの後方にも十分な空間が必要となります。データセンターによってはラックの後方には人が入れる程度の空間しか確保されていない場合もあり、空間が足りず引き抜けなかったり様々な配線が邪魔になってしまい保守作業が困難になるケースがあります。

そのため、事前調査で念入りに確認を行い、必要であればデータセンター側に実績の確認を行うなど、疑問点が解消できるような対応を実施しています。
データセンター運用ではこういった側面があり、アプリケーション開発とは違った要素がある中で物理環境の難しさに直面することもあります。
データセンター運用上の工夫
データセンターの運用というと、障害発生時は昼夜問わず対応しなければならないイメージがあるかもしれません。実際、障害が発生した場合は夜間でも対応しなければならないケースもあります。
しかし、運用者側としてはこういった状況は極力避けたいものです。特に夜間はゆっくり寝ていたいですからね。
そのためには、緊急で対応しなければならない問題が発生しにくい状況にしておく必要があります。これを実現する最も一般的な方法として、各所を多重化した構成にして故障等が発生しても全体に大きな影響を与えないようにする方法があります。
これにより、ネットワーク機器が一部停止したりサーバー側のネットワークポートの故障など何らかの障害が発生した場合でも、もう一方の機器を使用して稼働を継続することができ、影響を最小限にした上でプライベートクラウド全体が停止するような影響が発生しないような構成にしています。
最近では、運用者が安心して寝ていられるように障害対応の一部自動化も行っています。
一例としては、ホストダウンを伴う障害が発生した場合に、その場で対応する必要が生じるVMの退避やユーザー通知を自動化しています。
これにより、最も発生しやすいと考えられるホストダウンによる障害発生時にすぐに対応しなければならない作業を無くし、翌営業日以降にダウンしたホストの原因を調査するといった余裕のある対応が出来るようにしています。
こういった自動化により、運用者が安心して寝ていられるような状況を実現しています。
また、故障が発生しうる箇所の軽減も行っています。
例えば、サーバーを構成するパーツの中で最も壊れやすいと言えるのがディスクです。CIUが運用する「TKY02」と呼んでいるリージョンでは仮想化基盤用のサーバーからディスクを全て無くし集約することで、故障原因となりやすいディスクを排除することができ安定稼働に寄与しています。
こういった工夫により現状維持に必死になることなく、余裕を持って対応できています。このようにある程度余裕がある状態を作ることで、障害の予兆となりそうな不穏な動作に気づける可能性が高くなると考えています。
高密度化に伴う課題
一方で課題も多くあります。
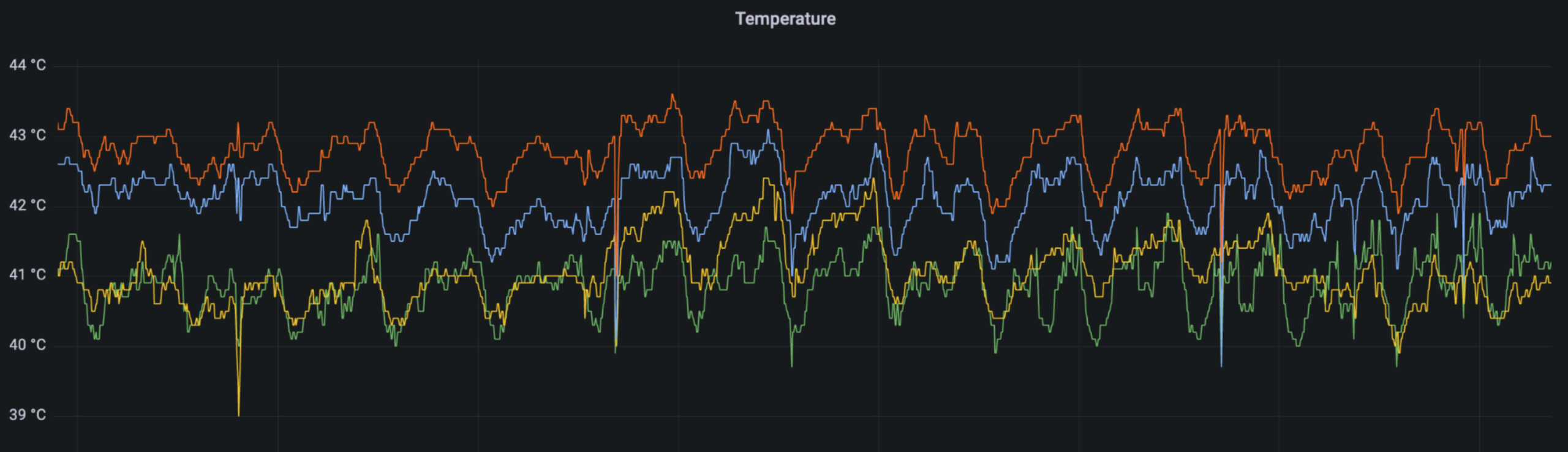
特に、近年ではサーバー単体の消費電力が増加傾向にありその分発熱量も増加しています。「TKY02」では2Uのシャーシに4つのサーバーノード搭載されたサーバーを使用して高密度化を図っており、ラック後方に排熱されたサーバーからの熱を十分に冷却しきれないなど、発熱量の増加による問題が顕著になっています。
また、設計上の課題もあります。
サーバーの高密度化を実現するため、ネットワーク機器側は100Gポート(QSFP28)を25Gポート4本(SFP28)へ分岐するブレークアウトケーブルを使用して配線しています。これは、25Gポートを持つネットワーク機器を用意するのに対して台数を減らし高密度化が実現できるとともに、サーバー側が1シャーシに4ノードあることを考えると、配線のしやすい単位でもあるからです。
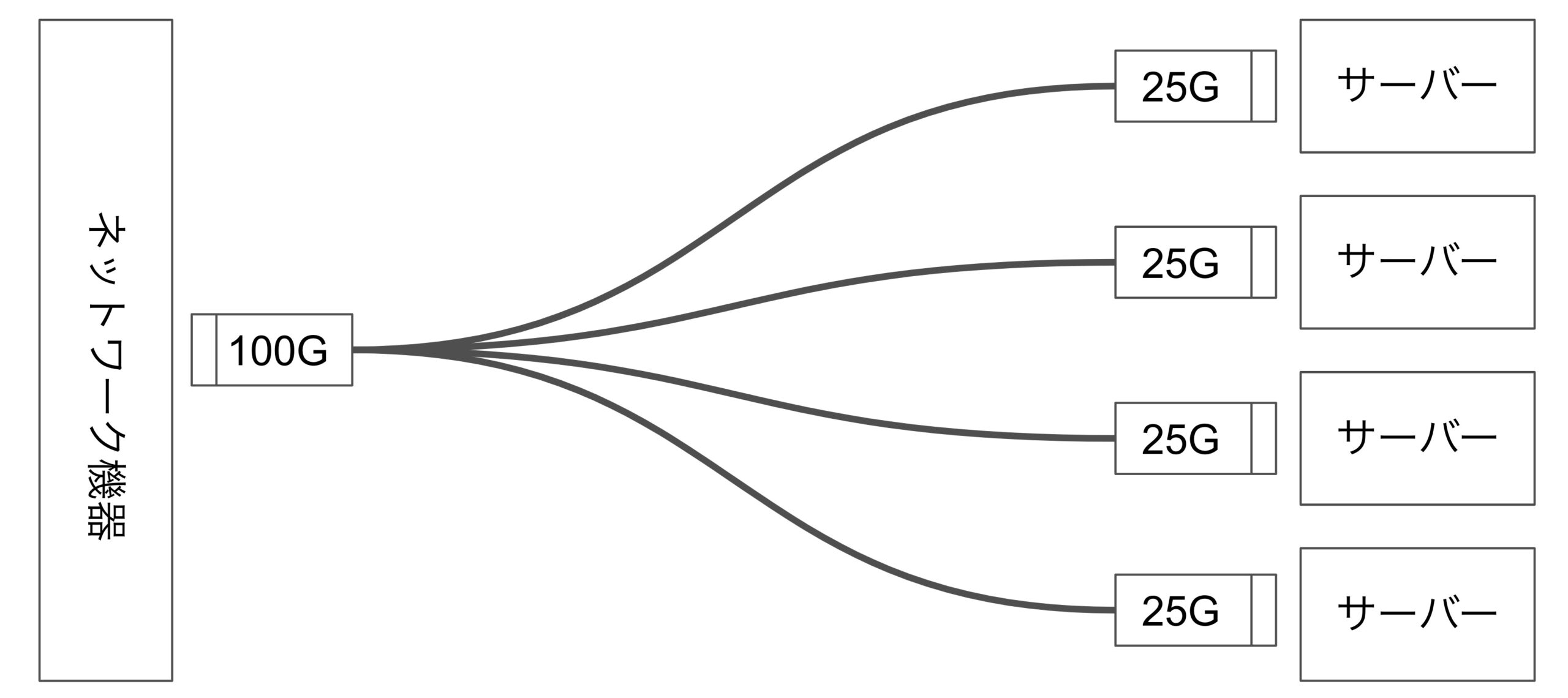
しかし、都合の悪い面も存在します。
例えば、分岐側のモジュールが1本でも故障した場合ケーブルごと取り替える必要性が生じます。そのため他の3分岐側にも影響が生じます。通常のように1:1で配線されていれば影響を受けているノードのみケーブル交換を行うことで解決出来ることを考えると、少々厄介な問題です。
おわりに
今回は、サイバーエージェントのプライベートクラウド環境におけるデータセンター運用とその課題について紹介しました。
プライベートクラウドやデータセンターの運用というと「つらそう」といった声をいただくこともあります。実際のところ、想定し得なかったような問題が発生したり、機器側のファームウェアのバグなどどうにもできない部分で問題が生じるケースもあります。
しかし、これまでデータセンターを運用してきた経験を活かし、サーバーのディスクレス化の実施や障害対応の一部自動化など、解決してきた課題も多くあります。
一方で顕在化してきた課題もあり、気にしていかなければならない課題も増えている中で今後も頭を悩ませることになりそうです。
最後に、本記事を通してサイバーエージェントのデータセンター運用に少しでも興味を持って頂けたなら幸いです。