
CTO統括室の黒崎(@kuro_m88)です。今回はAWS Lambdaの高速なコンテナロードの仕組みについて紹介します。
AWS Lambdaはサーバレスなマネージドサービスであり、難しいことを知らなくてもユーザ(私たち)は簡単にアプリケーションをホストでき、簡単にスケールします。
ユーザから見るとシンプルですが、その裏側では様々な仕組みがあったり最適化が行われたりしています。
マネージドサービスの裏側を必ずしも知る必要はありませんが、仕組みを知っておくとより使いこなせるはずですし、自信を持って技術選定ができるはずです。(そして何より裏側を知ることは楽しい!🤗)
本記事はUSENIX ATC 2023で発表された論文「On-demand Container Loading in AWS Lambda」の内容に基づいて、読んでいて面白かったポイントをまとめています。
On-demand Container Loading in AWS Lambda | USENIX
AWS Lambdaのコンテナロードの仕組み
Lambda Functionは秒間1.5万回も起動されているようです。仮に全てが10GiB(Lambdaのコンテナイメージの最大サイズ)のコンテナを起動するとすると、秒間150TBのデータ転送が発生します(論文では150Pb/sと書かれていますが、1.2Pb/sな気がしています)。
理論上の値なので実際にはこれほどのデータ転送は必要ないかもしれませんが、現実的にコンテナロードだけのためにこの規模のデータ転送性能を担保するのは厳しいはずです。
そこで、AWSではコンテナイメージの実世界での利用パターンを分析し、コンテナイメージの読み込みを最適化しています。
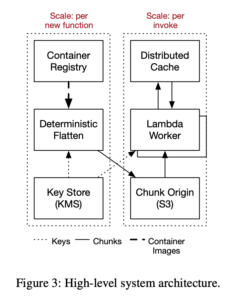
論文を読んで、肝になる技術はオンデマンドな読み込み(とCopy-on-Write)、収束暗号化、イレイジャーコーディングの3つだと感じました。この3つのキーワードだけ聞いてなんとなく実装のイメージが湧く人はこの記事を読む必要はないかもしれません。
AWS Lambdaにおけるコンテナイメージの特性
Docker Hubの統計データを利用して計算したところ、
- コンテナイメージのデータのうち起動時に必要なデータは平均6.4%程度
- 大半のコンテナイメージはベースがalpineやubuntu、nodejsなどで、ベースが共通のコンテナイメージが多いことから全体としては重複データが多い
という調査結果があるようです。
AWS Lambdaの環境でも新規に登録されるLambda Functionのコンテナイメージのチャンク(後述)のうち、ユニークなチャンクは平均4.3%程度、中央値で2.5%程度だったようです。
大半のデータが重複だったり、すぐには読み込まれないため、コンテナの読み込みを最適化する余地が大きいことがわかります。
オンデマンドなコンテナロード
Lambda Functionの起動時に必要なのはコンテナのデータのうち一部で、全てのデータが必要なわけではないことが多いことがわかっています。
そこで、必要な部分だけを読み込めるようにします。必要ない領域はそもそもロードしない戦略です。
OCI image(いわゆるDocker image)は階層構造になっており、ベースとなるイメージに変更を加える場合は差分のレイヤを重ねていく仕組みになっています。
このままだとLambdaとしては扱いづらいので、一度ext4ファイルシステムに全て展開してしまい(flattening)、固定長に分割(チャンク)しS3に保存するようです。
論文中でもあえて「コンテナイメージ」ではなく、「コンテナ」という表現をしているのはこのあたりに理由があるのではないかと推測しています。この時点で良く見知ったDockerコンテナではなくなっています。
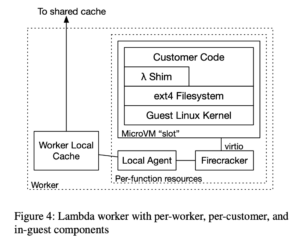
Workerと呼ばれるサーバ内にはFirecrackerという軽量な仮想化機能があり、この上に複数のMicro VMが作成され、この中でCustomer Code(ユーザがデプロイしたアプリケーション)が実行されます。
Worker側にはLocal Agentというエージェントがおり、このエージェントがブロックデバイスとして振る舞います(virtio-blk)。Micro VMの視点だとブロックデバイス上にext4ファイルシステムが構築されているように見えるのみであることから、非常にシンプルです。
Local AgentはMicro VMからのブロック読み出しの要求に応じてS3に保存されたチャンクを読み込みます(キャッシュ機構については後述)。読み込みの要求がなかったチャンクは一切アクセスされません。これによりコンテナの読み込みを最小限に抑えられます。
Lambda Functionではローカルのファイルシステムに書き込みが可能なので、ブロックデバイスには書き込みの要求も来ます。
キャッシュ自体を書き換えると他のLambda Functionとコンテナのキャッシュの共用ができなくなってしまうため、書き換えはせずにWorker内のストレージにコピーし書き込みます。一般的にこの挙動は「Copy-on-Write (CoW)」と呼ばれます。
仮にストレージの読み書きを頻繁に行うCustomer Codeだった場合、独自実装のブロックデバイスへの読み書きの要求が頻繁に来るとなるとパフォーマンス面への影響を懸念するかもしれませんが、そこまで心配する必要はなさそうです。
前述のとおりMicro VMの視点では単なるext4のファイルシステムが見えているだけなので、Micro VM側のLinuxのページキャッシュが機能し、ストレージ(Local Agent)へのI/Oに対してキャッシュが効きます。
Local AgentはRustで実装されていて、選定理由としてはAWS内でパフォーマンスと信頼性の実績があったからのようです。Amazon S3チームでは熟練していない(non-expertな)プログラマであってもRustのコードの正しさを形式手法を用いて検証できていることも安心材料としてあったようです。
コンテナのキャッシュ
AWSの視点で見ると大半のイメージ内のブロックは重複が多いことがわかっています。重複しているブロックをキャッシュすることで、コンテナの読み込みをさらに最適化します。
ここで、セキュリティの問題が発生します。AWS Lambdaはマルチテナントなサービスです。AWSアカウント間で暗号化されていないコンテナイメージのキャッシュを共有したり、全体で1つの鍵を共有したりすると、AWS Lambdaの基盤のソフトウェアのバグや脆弱性が原因でアカウントをまたいでコンテナ上のデータが漏洩するリスクがあります。一方で、アカウントごとにキャッシュに暗号化のキーを生成するような手法を取ると、仮に異なるアカウントで全く同じ内容のコンテナが実行されたとしてもデータが異なるために重複排除ができず、キャッシュ効率が大幅に低下してしまいます。
収束暗号化
マルチテナントな環境下のデータの暗号化と重複排除の要件を同時に満たすのが収束暗号化(Convergent Encryption)です。
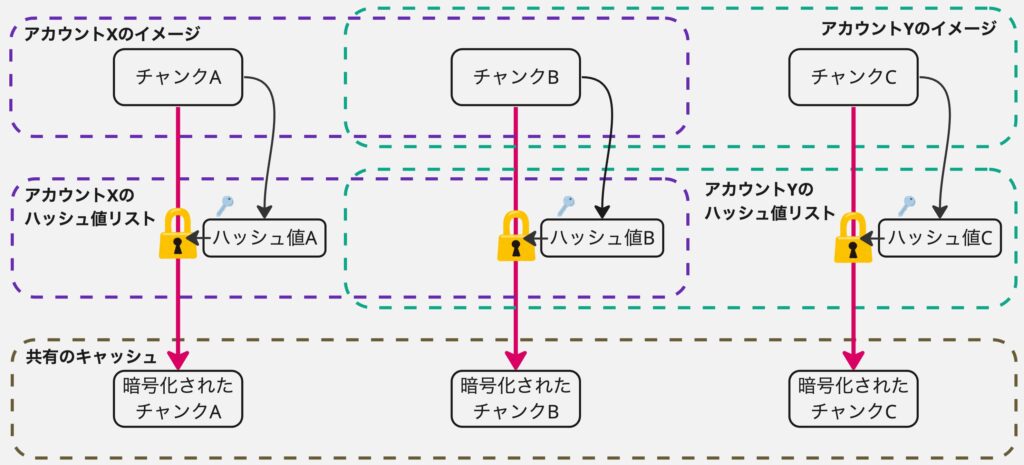
収束暗号化は一言で説明すると「暗号化対象のデータの暗号化の鍵をそのデータのハッシュ値にする暗号」です。
非常にシンプルな手法ですが、テナント(AWSアカウント)が違っても暗号化対象のデータが同じであれば必ず同じ暗号化結果になるため、重複排除が可能になります。
復号するためには元のデータのハッシュ値を知っている必要があるため、コンテナイメージがLambdaに登録された時にハッシュ値の一覧を計算し、この一覧自体はテナントごとの鍵で暗号化して保存します。
これにより「サービス全体でテナントをまたいでデータを暗号化したまま重複排除しキャッシュするが、元のコンテナイメージを持っているテナントのみデータを復号可能」な特性が得られます。
階層化キャッシュ
チャンクの参照には局所性があるため、3層にわけて階層化されたキャッシュを導入します。
- L1: Workerのローカル
- L2: データセンタレベルの分散キャッシュ
- L3: Amazon S3
多くの場合キャッシュを階層化すればデータの読み込みは高速化され満足する気がしますが、AWS Lambdaではキャッシュからデータを取得する際のtail latencyが問題になったようです。特にL2キャッシュが問題になったようです。
L1はWorker内であることからレイテンシの問題は発生せず、L3はAmazon S3であることからキャッシュというよりはストレージのような扱いです。
イレイジャーコーディング
tail latencyを改善するには、キャッシュシステムの安定性が求められます。キャッシュミスによるパフォーマンス悪化を防ぐためには、キャッシュの冗長化が必要です。
分散システムにおいて個々のノードが常に健全であることを保証するのは現実的ではありません。一方で、同じキャッシュを2つのノードにコピーして冗長性を担保することを考えると2倍のキャッシュ容量が必要になってしまい非効率です。そこでイレイジャーコーディングを利用します。
イレイジャーコーディング(Erasure Coding、消失訂正符号)は大規模なストレージ、特にオブジェクトストレージでよく使われる技術です。
誤り訂正の技術を利用しており、K個のデータにN個の誤り訂正用のデータを付与しK+N個のデータを分散して保存すると、N個のデータが失われてもK個のデータから元のデータを復元できます。
LambdaのL2キャッシュではK=4、N=1のイレイジャーコーディングを利用しています。
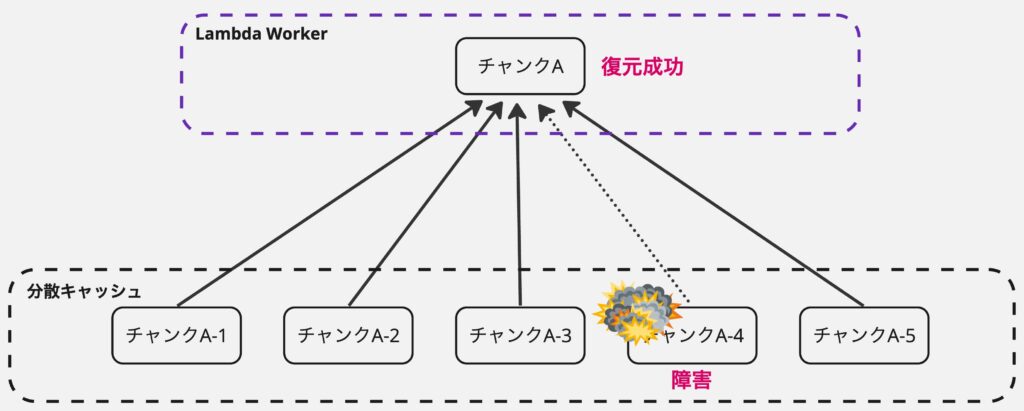
この場合、1つのチャンクを5つに分割し、どの組み合わせでもよいのでそのうち4つが取得できれば元のデータを復元できます。キャッシュ容量のオーバーヘッドとしては25%です。
この特性を活かすと、1つのチャンクのキャッシュを取得する時に5つのノードへリクエストし、最初に4つのノードからレスポンスが返ってくれば残りの1つのノードからのレスポンスを待たずにレスポンスを返せます。最悪障害等でレスポンスが帰ってこなかったとしても問題ありません。この特性を利用してtail latencyの改善と耐障害性を両立しています。
まとめ
「キャッシュというより分散ストレージに似た何かでは?」というのが最初の感想でした。
コンテナのストレージのアクセス特性を生かした高速化をしつつセキュアかつシンプルな実装になっていることがわかり面白かったです。
要素としては、
- オンデマンドなコンテナ読み込み
- キャッシュ
- 重複排除
- 収束暗号化
- 階層化キャッシュ
- イレイジャーコーディング
- 重複排除
これらの技術がAWS Lambdaのコンテナロードの高速化に大きく貢献していそうだということが論文よりわかりました。
今回論文の全ての内容は紹介しきれておらず、他にも分散環境でのGC(Garbage Collection)など面白い内容が書かれているので、興味がある方はぜひ元の論文を読んでみてください!