
協業リテールメディアdivでデータエンジニアをしている千葉です。
本日は、広告プロダクトにおけるデータ基盤を効率よく活用することを目指したこの1年間を振り返って、データ基盤から広告プロダクトの価値を高めるための試行錯誤をご紹介します。
目次
データ基盤の構成紹介
以前弊社のイベントに登壇した際の設計思想をもとに構築をしています。
このデータ基盤の利用目的としては、各広告媒体の配信結果を分析するための基盤となっています。
基盤の構成としてはStorageにRaw Dataを格納し、Datalake、DWH,Datamartの3層構造で基盤を構築しています。
主に使用しているツール/サービスとしては
- Snowflake
- dbt
- GCP
- Cloud Storage
- Cloud Composer
- Cloud Batch
- Vertex AI
…etc
- Tableau
となっています。
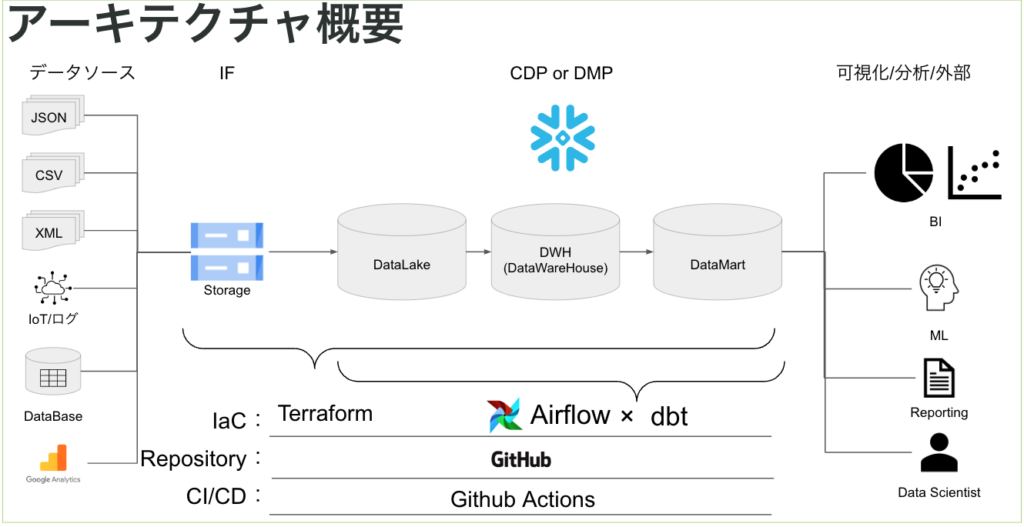
我々のデータ基盤の特徴はおもに以下の2つとなります。
- 広告プロダクトのみならず様々なデータソースから様々な形式のデータを取り込む必要がある
- 取り込んだデータを活用できる形に整え可視化をしていく必要がある
上記のような構成にすることで、それぞれのサービスが以下の役割を持ち、データ基盤の拡張を容易にすることが可能となりました。
- GitHub/GitHub Actions:コードレビューからデプロイまでの一元フロー化
- Google Cloud Storage:様々なデータの形式を格納することができる
- Snowflake:Google Cloud Storageからのデータの取り込みが容易に可能
- dbt:ELTの処理の共通化およびレビューからデプロイまでのサイクルを回すことができる
- Cloud Batch:SQL以外の処理でパフォーマンスを柔軟に変更することができる ※詳しくはこちらの記事を参照ください
- Vertex AI:ML Workflowの実行からモデルの品質チェックまで一元管理ができる
- Tableau:アウトプットをチームで共有/示唆を得ることができる
上記のような構成自体は昨今一般的なものかと思います。一方、その後の運用フェーズについてはなかなか事例を多く見つけることができないません。そこで今回は、その運用部分についても触れていきたいと思います。
データ基盤の活用および運用方法
今のチームでは様々な職種のメンバーが在籍しており、データエンジニアの私を始めデータアナリスト、データサイエンティスト、バックエンドエンジニアで構成されています。
各種職種は分かれているものの作業の内容については多くが民主化されており、このデータ基盤の活用および運用についても同様です。
※ここで言う民主化とは特定の職種のみがデータ基盤を触るのではなく、チームメンバーが職種に関係なくデータ基盤の運用、拡張に携わっていることを指しています。
主な民主化されている内容としては
- 新たなデータソースの追加
- 新たなテーブルの追加
- 新たなバッチジョブの追加
- A/Bテストのロジック追加 ※現在運用処理に乗せているロジック例についてはこちらの記事を参照ください
- 新たなレポートの追加
- ABテストの結果の可視化
- 機械学習のモデルの品質の可視化
になります。
一般的に上記のような作業をやっているのがデータエンジニアが多いかと思います。一方で我々のチームでは構築当初からそのやり方ではなくデータ基盤活用の民主化を目指す方針となりました。
民主化を目指すメリットとしては、データエンジニアの作業に依存せずにデータ活用ができるに尽きると思います。
各職種の裁量でデータが拡張していくため、我々のデータ基盤には多くのデータソースが繫がり、そこから様々なデータが生まれています。
民主化を目指すために工夫した点について説明をしていきます
1. 手動作業での事故が起きないCI/CDの構築
今のデータ基盤ではSnowflakeとdbtを利用しているため、ELTのTの部分はSQLで記載され、GitHub上でレビュー/管理ができています。主な流れは以下のとおりです。
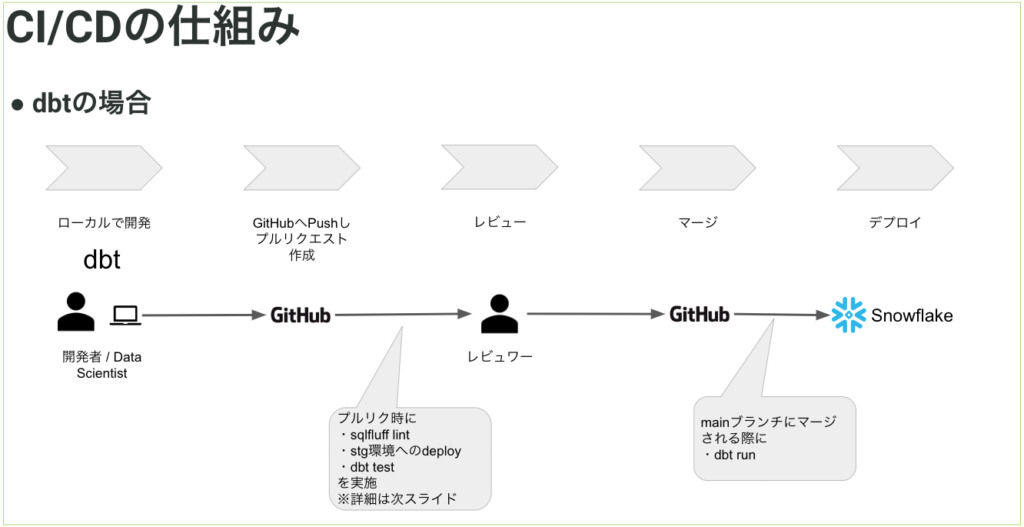
また、EやLの部分についてもGCPのサービスやSnowflakeの機能、 schemachangeなどのマイグレーションツールを使っているため基本的にGitHub上のレビュー/管理が行えています。
そのため、データソース/テーブル/バッチジョブの追加についてレビュー無しで本番にデプロイされることがありません。
特に本番運用をしているオブジェクトについては容易、に変更を加えられてしまうと事故の元となるためレビュー時のチェック対象となります。
また、dbt ではテストを書くことができるため、これを利用します。テーブル作成時にテストを書くことで、データ品質を担保することが可能です。。
dbt testについては、dbtのモデルを実行するdbt runを実行した直後に dbt test を実行をし、新しく入ったデータが問題ないことまで確認をします。
※dbt testについてはこちらを参照ください。
このようにすることでデータエンジニアが作業をしなければできなかったテーブル追加/削除やETL処理の追加/削除、データ品質の担保などがレビューのみとなりコストが大きく下がりました。
2. 実験ができる環境の提供
一般的にSandbox環境といった形で利用者が実験的に扱える環境が用意されることがあるかと思います。一方あまりにも権限を与えすぎると実運用をしているテーブルやデータを誤って消してしまう事故が発生してしまったり、細かな権限管理をするあまり運用が複雑になってしまい運用コストが非常に大きくなってしまいます。
我々のデータ基盤ではSnowflake上のスキーマを以下の形に区切り、それぞれのスキーマのOWNERSHIP権限を目的別で持つことで安全なシステム環境と自由に実験ができる環境を両立し、運用コストを最低限に抑えています。
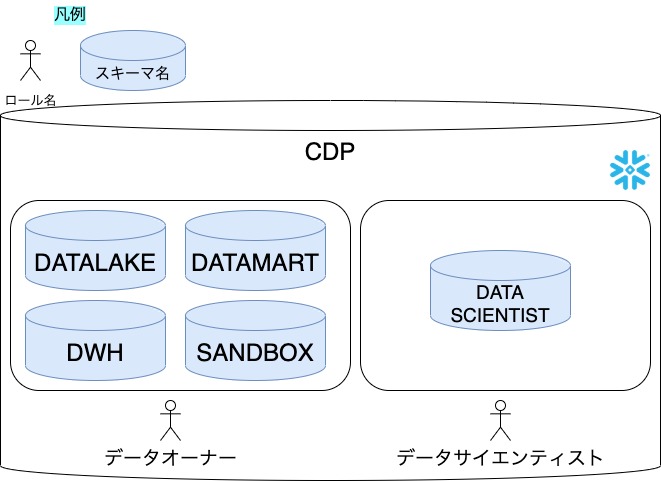
ポイントとしては各スキーマのOWNERSHIP権限を持たせているロールが異なる部分です。
(上図のロール=OWNERSHIP権限を持っているロールになります)
OWNERSHIP権限を持っている場合そのオブジェクトに対するすべての操作が可能となります。 (スキーマの配下にテーブルなどのオブジェクトがありスキーマについている権限と同じ権限が付与されています。)
データオーナーについては主に運用に使用するスキーマについてOWNERSHIP権限を持っておりその他のロールについては参照をするためだけの権限にしています。
(SANDBOXスキーマについてはOWNERSHIPは持たせず各ロールにCREATE権限だけ付与をしています。)
一方で、DATA SCIENTISTスキーマについてはデータサイエンティストロールがOWNERSHIP権限を持っています。
SANDBOXスキーマとDATA SCIENTISTスキーマの違いはOWNERSHIPを持っているかどうかでデータサイエンティストのロールを使用している際はDATA SCIENTISTスキーマ上であらゆる操作が可能となりますがシステム上で使用しているスキーマに対しては強い権限を持っていないため事故が発生しづらい環境となっています。
また、SANDBOXとDATA SCIENTISTを分離している理由はもう一つありDATA SCIENTISTロールではハイパフォーマンスなコンピュートリソースを利用する必要があるため利用できるWarehouseのサイズが大きくなっています。
※Warehouseについてはこちらを参照ください
DATA SCIENTISTスキーマで実験的に作ったテーブルが運用に乗ることになった場合レビューを通しDWH上にテーブルが作られることとなります。
3.コストの確認および監視
広告プロダクトのデータ基盤ということもありアプリのログデータやPOSデータなど大量のデータを扱うケースがあります。
その際に、予期せぬクエリの長時間の実行や大量データの発生などによりコストが大幅に増える危険もあります。
実際に、我々のチームでもクエリの長時間の実行は何度か起こっておりあらかじめ想定されていたケースもあれば予期せぬケースということもありました。
単純な実行時間の制御のみでは長時間実行したいケースをカバーできないためおもに以下のようなルールで運用をしています。
- 一時的に長時間実行クエリを実行する場合専用のWarehouseを利用する
- Warehouseごとにクエリ実行時間の上限を決められるため日次バッチで利用しているWarehouseについては実行時間の上限を短くし、長時間動かすことがわかっている処理については実行時間の上限を長く設定したWarehouseを用意するといった対応をしています。
- あらかじめ長時間実行するとわかっているクエリに関してはハイパフォーマンスなWarehouseを利用する
- コストの考え方として低パフォーマンス長時間の場合と高パフォーマンス短時間の場合ではあまりコストは変わらないため後者を選べる場合は選ぶようにしています。
- 週に一度の頻度でコストが大きかったクエリを確認する
- 週に1度朝会で予期せぬ形で長時間クエリが実行されていないか、ハイパフォーマンスなWarehouseを利用した方が良いクエリがないかなどをチェックしています。
- また、コストが大きいクエリについては各メンバーでも確認ができるよう権限の付与を行っています
4. 定期的な棚卸し
我々のチームでは四半期に一度の頻度で不要なテーブルや処理について棚卸しを行います。
特にSANDBOXやDATA SCIENTISTについては自由にテーブルが追加できるためすぐにテーブルが増えるため定期的な棚卸しが重要となります。
当たり前のことではあるかもしれないですがこういった定期的な運用を忘れずにすることでチームメンバーが変わった際も不要なオブジェクトなどが残らず扱いやすいデータ基盤になっていきます。
(棚卸しについては手動運用中ですがこちらについてもなるべく効率的にできる方法を模索中となります)
データ基盤の民主化をした結果と課題
約1年ほどデータ基盤を運用した結果チームでデータ基盤の民主化が進み多くのデータが追加/活用されてきました。
一方でデータ基盤の価値としてはデータが溜まっていることもありますがただデータが溜まっているだけではお金は生み出されず、集まったデータをアウトプットし活用することでお金につながっていきます。
我々のチームではこのデータの流れを情報流と呼んでいます。
この情報流はワークフローオーケストレーションとも関係があり、情報量の設計をするためにはワークフローオーケストレーションの設計が必要なってきます。
- ワークフローオーケストレーション
- 複数の処理をつなげる一連の流れの実行制御およびシステム間の調整を行う
※ワークフローオーケストレーションについての詳細はこちらを参照ください。
- 情報流
- プロダクトで発生する情報の流れを制御することを目的とし、適切な情報の流れを定義すること
理想的な状態としては情報流を描いてみた際にスケールしていない(≒ボトルネックになっている)箇所についてワークフローオーケストレーションツールを導入したり、場合によっては人の行動やオペレーション、組織構造までを変えていけることだと考えています
今の我々のチームでは以下の様になっています。
- データソース:各データが発生する箇所
- データストア:発生したデータを格納する箇所
- アウトプット:格納したデータをアウトプットする箇所
- 活用:アウトプットしたデータを活用する箇所
このような4つのフェーズに分けた際に今の我々のチームで実現できていることを各矢羽の線の太さで表すと以下の図のようになります。
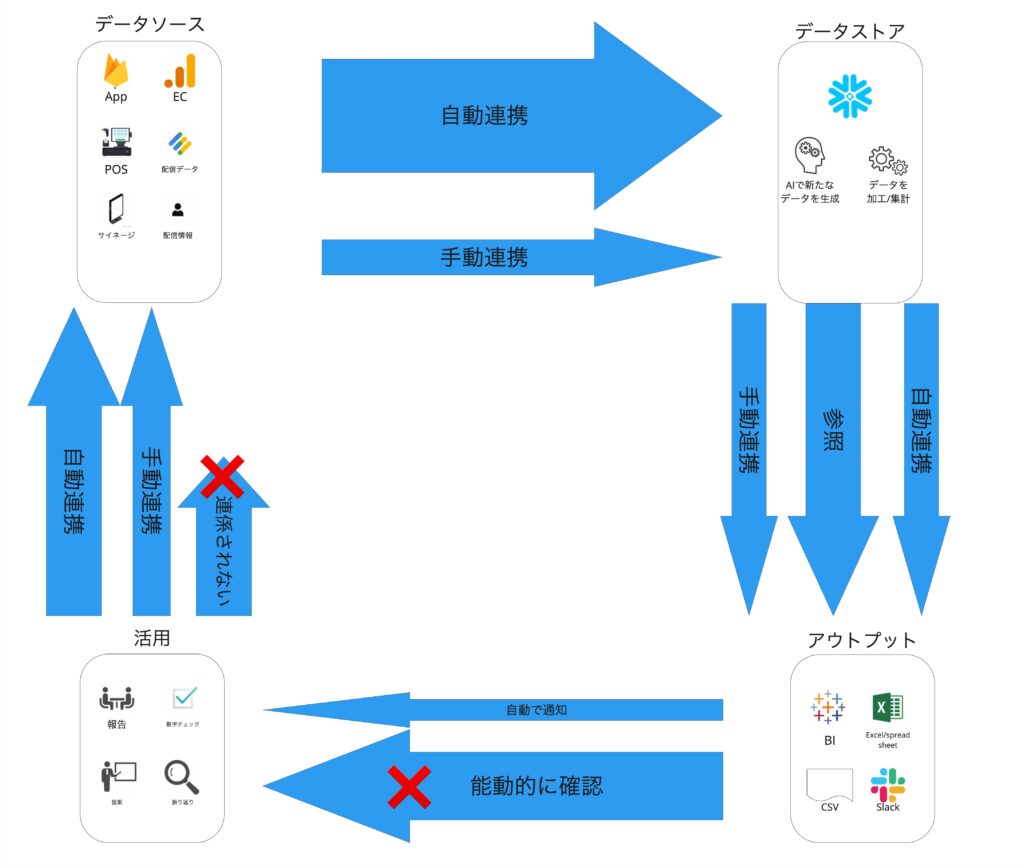
データ基盤の民主化による効果としてデータソース→データストア→アウトプットの自動化が進み、アウトプットの量も増えていきました。
一方で以下の2点が課題となっています
- アウトプット→活用のアウトプットの量は十分に増やせましたが、まだセールスチームを対象ユーザとした機能開発は十分ではなく、ここに活用のポテンシャルがあります
- 活用→データソースの連係されないデータが存在しているため、こちらについても連携をしていくことで新たな活用をみこむことができます
それぞれの課題に対して現在解決策を講じ、改善している最中となっているため、また別の記事にてご紹介できればと思います。
データ基盤の価値としてはアウトプットを増やせたことで一定の価値を生み出すことができているかもしれないですが我々が作っているのは広告プロダクトのデータ基盤になるため活用までつなげていく必要があります。活用につなげる部分が人に依存するのではなくもっと自動的に活用ができる状態になっていくことで広告プロダクトのデータ基盤としてもっと価値が高まると考えています。
まとめ
本記事においてはデータ基盤の民主化を我々のチームでどのようにして実現していったかについて記載をいたしました。
まだまだ多くの課題、特に活用部分については生成AIなどを使うことでもっと新たな価値が生まれれてくるかと思います。
我々のチームでは、データの価値を最大限活かした広告プロダクトの開発を日々取り組んでいます。
- 本記事を読み興味データ基盤、データエンジニアリングに興味がある方
- 新しい技術で小売業界に革命をもたらしたい方
- 小売業界の広告プロダクトのNo1を取りたい方
カジュアル面談でお話ししてみませんか?
以下のリンクよりご連絡お待ちしています!
https://hrmos.co/pages/cyberagent-group/jobs/1986666672570519563