
AI事業本部 協業リテールメディア Div. の青見 (@nersonu) です。2023年11月に中途で入社したため、5月でようやく入社半年を迎えました。社内 Slack の times で有給休暇が付与されて喜んでいる(?)様子を御覧ください。
そんな社歴半年のペーペーですが、普段は機械学習エンジニアと強い気持ちで名乗ってお仕事をしています。特にうまい繋ぎも思いつかないので、記事の本題に入りましょう。
近年、 LLM に関する話題は尽きることはありません。研究領域やビジネス領域といった概念にとらわれず、わたしたちの生活のすぐそばで、今まさに違和感が少しずつ取り除かれながら社会に溶け込んでいっていると感じます。そんな LLM ですが、自然言語というデータの枠に収まらず、様々なタスクへの適用の試みが日夜行われています。そんな挑戦的な数多あるトピックの中から「表形式データの読み解き」に関してのお話を少しだけしていきたいと思います。
目次
モチベーション
「表形式データを読み解こう!」というモチベーションがあるとき、まずはどういったことをするでしょうか。例えば、POS のような表形式データがあったとして、これをマーケティングに活かしたいといったケースが考えられると思います。こういった状況では恐らく多くの場合、マーケターやアナリストといった人間、すなわちデータに関して専門性を持っているもしくは分析に関しての技術を持っている人間が多角的なデータ分析を経て、何かしらの示唆を創出したり、ビジネス的な意思決定を行います。
一方で、こういった専門性・技術を持った人材が必ずしも揃っているとは限りませんし、他の業務にリソースを割かないといけないこともあります。さらに、実データの多くはデータ数が膨大であったり、データを扱うことが不慣れな人間が取り扱うことができる量にも限界があります。
そこで、単純な発想として思いつくのは LLM の活用です。世はまさに生成AI戦国時代と言わんばかりの時代を生き抜く読者の皆さんも、半信半疑ながら考えたことのある方もいるのではないでしょうか。
チームメンバーの須ヶ﨑が書いた記事 (https://developers.cyberagent.co.jp/blog/archives/47743/) では、(多くを表データとして持つ) 専門性の高いデータを読み解くことの困難さと、実践的なプロンプティングのテクニックを紹介しました。
本記事では、表データというところにさらにフォーカスを当て、近年の LLM の表データの読解についての論文をいくつか紹介します。
論文の紹介とちょっと試用
今回紹介する論文は、基本的に「表データとそれに関する問い (Question) がセットで入力として与えられ、それに適した回答 (Answer) を返すタスク」を解いています。いわゆる QA に関するタスクの一つです。また、基本的には In-context Learning ベースの手法を対象としており、(ほぼ) LLM の性能でどこまで出来るのかというところを見ることができればと思います。
Binder (Cheng et al., ICLR 2023)
元論文: https://openreview.net/pdf?id=lH1PV42cbF
LLM に表をパースさせるためのアイデアを考えたときに、 入力を SQL や Python に変換させて解釈させ、その後に取り出すアイデアは比較的簡単に思いつくのでは無いでしょうか。この発想をさらに発展した手法が、最初に紹介する Binder と呼ばれる手法です。
例えば POS の表データに対して、「関東で作られた商品で一番売れたものは何?」という問いが与えられた際、以下のように条件となるようなものを自然言語で表現されるタスクに置き換えてプログラムを生成します (例として SQL で表現しています)。
SELECT Product
FROM T
WHERE f("関東?";Made_in) = 'yes'
ORDER BY Sales DESC
LIMIT 1
次に、この中に含まれるタスク (ここでは f("関東?";Made_in) = 'yes' ) に対する回答を再度生成するように促し、得られた結果を統合して最終的なプログラムを求めます。最後に、それを元に目的の回答を導くというメカニズムです。
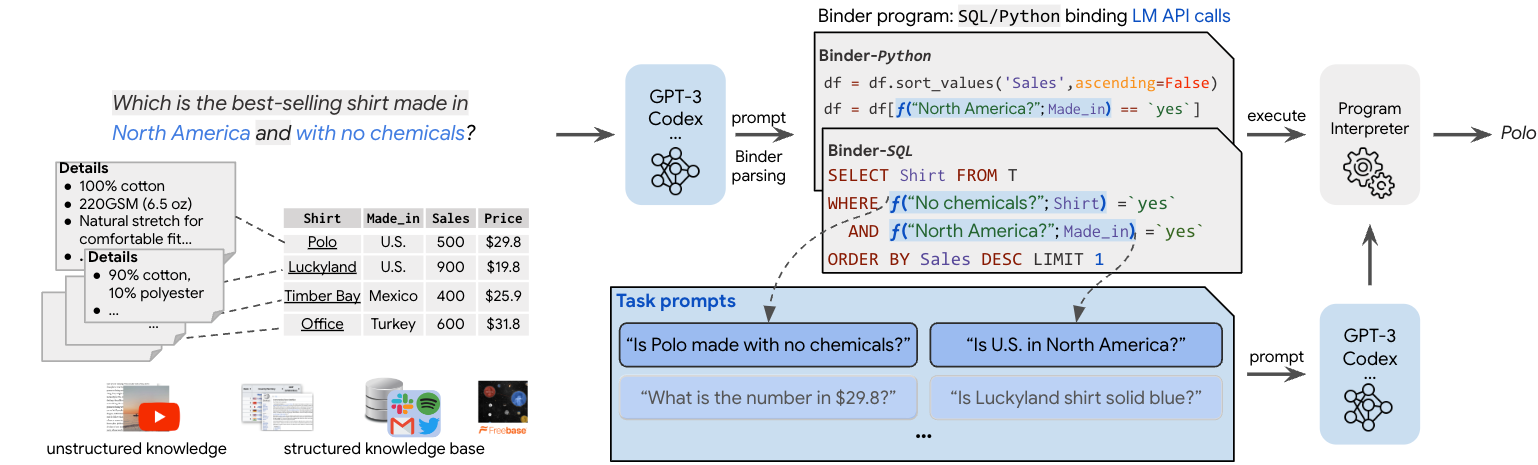
発表当時は OpenAI の Codex を利用していたようですが、Codex のサポート終了に伴って GPT-4 等のモデルへの対応も実施しているようです (GitHub)。
実験結果を確認すると、既存手法よりも性能向上しているのがわかります。注目すべきは、直接 LLM にコードを生成させて結果を得ようとするよりも良い結果が得られている点です。提案法の Binder program の有効性が見て取れます。
プロジェクトページに実際の入力プロンプトがあるので、興味のある方はお試しください。
Dater (Ye et al., SIGIR 2023)
元論文: https://arxiv.org/abs/2301.13808
ところで、読者の皆様も LLM により簡単に咀嚼したタスクを渡すと、元タスクよりもパフォーマンスが向上した感覚や経験がある方は少なくないと思います。実際にいくつかの研究でもその有効性が示されており、2つ目に紹介する Dater でもこのアイデアが取り入れられています。
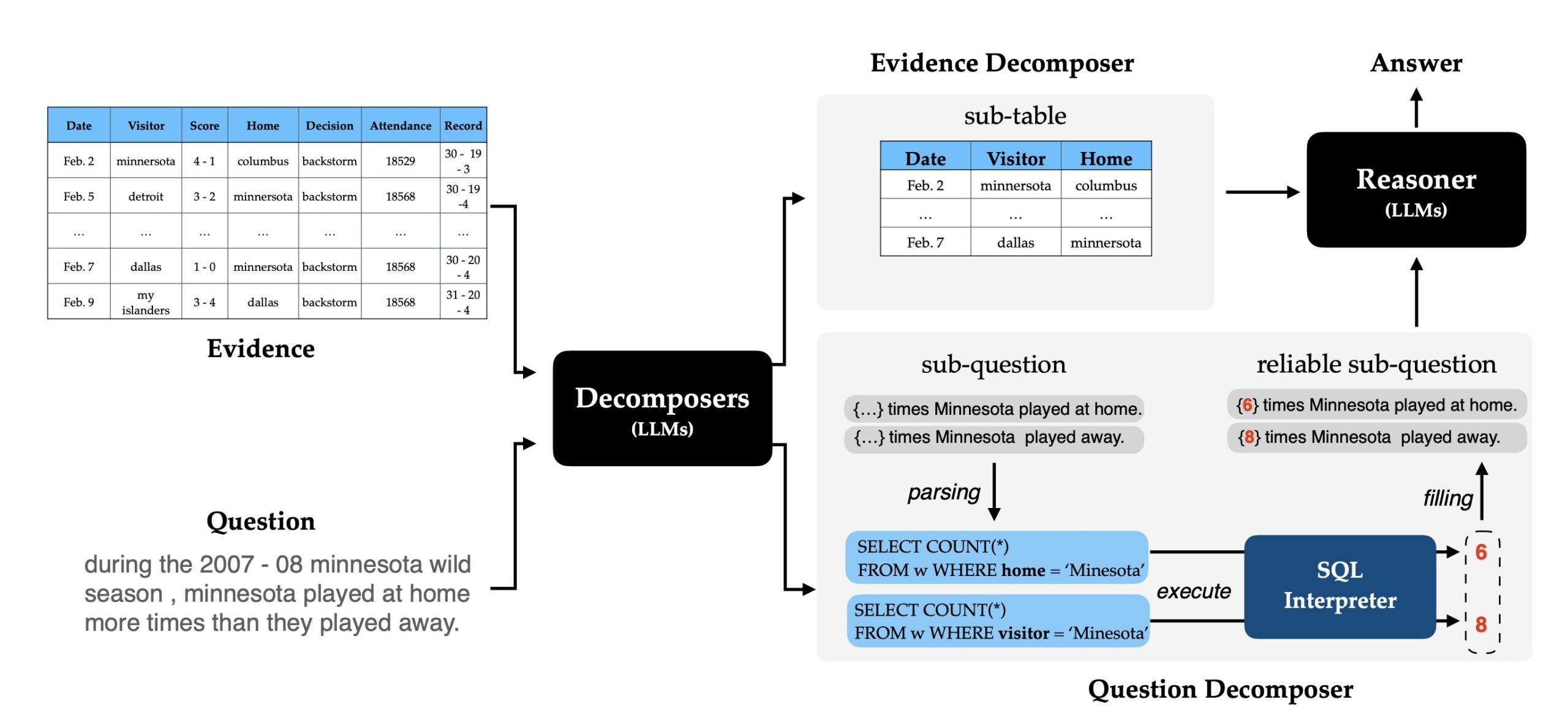
分解していくのは大きく2つで、「元テーブル」と「質問」です。
Evidence Decomposer と称するステップでは、「元テーブル」を回答に必要なサブテーブルに変換を行っています。詳細は元論文の Prompt 4.2 を参照していただきたいのですが、ポイントは質問に対応する (プロンプト内では “support or oppose the statement.“ と表現している) 行と列を抽出させるようなプロンプトを記述している点です。これによって、目的のサブテーブルを得ています。
「質問」を分解するのは Question Decomposer と称するステップです。論文内でも言及 (Section 4.3 参照) がありますが、LLM は、特に数値が関係するケースにおいて、入力とする表に対応しない内容を生成する可能性があり、サブ質問の生成には信頼のおける方法が必要です。ここでは、具体的な数値が入るであろう部分をマスクした状態でサブ質問を生成し、 SQL に変換します。そして、変換した SQL 内でマスク部分の実際の数値を求める (概要図における COUNT(*) が該当)ことで、より正確な数値を含むサブ質問を得ます。最終的に、こうして得られたサブテーブルとサブ質問を使って回答を出力することができます。
結果として、著者らは性能向上だけでなく、上記のようなサブテーブルとサブ質問を生成するステップを介すため、解釈可能性にも優れていると主張しています。
Chain-of-Table (Wang et al., ICLR 2024)
元論文: https://openreview.net/forum?id=4L0xnS4GQM
最後に、先日(2024/5/7 – 2024/5/11)開催された ICLR 2024 からも一本紹介しましょう。先に紹介した2つの手法は、表からの抽出部分は SQL 等に一旦変換するというステップを取っていました。しかしそもそも、この表からの抽出ステップに失敗している (例えば、 SQL 文そのものの生成に失敗している)ケースがあるのではないでしょうか。人間が表データを分析するステップを考えても、特定の行/列の抽出の操作だけでなく、group-by といった集約関数に加え、行の追加操作が発生するかもしれません。こういった表に対する操作そのものをプロンプトとして定義してしまって、質問に対してそれらの必要な操作をステップバイステップで実行しようというのが Chain-of-Table です。
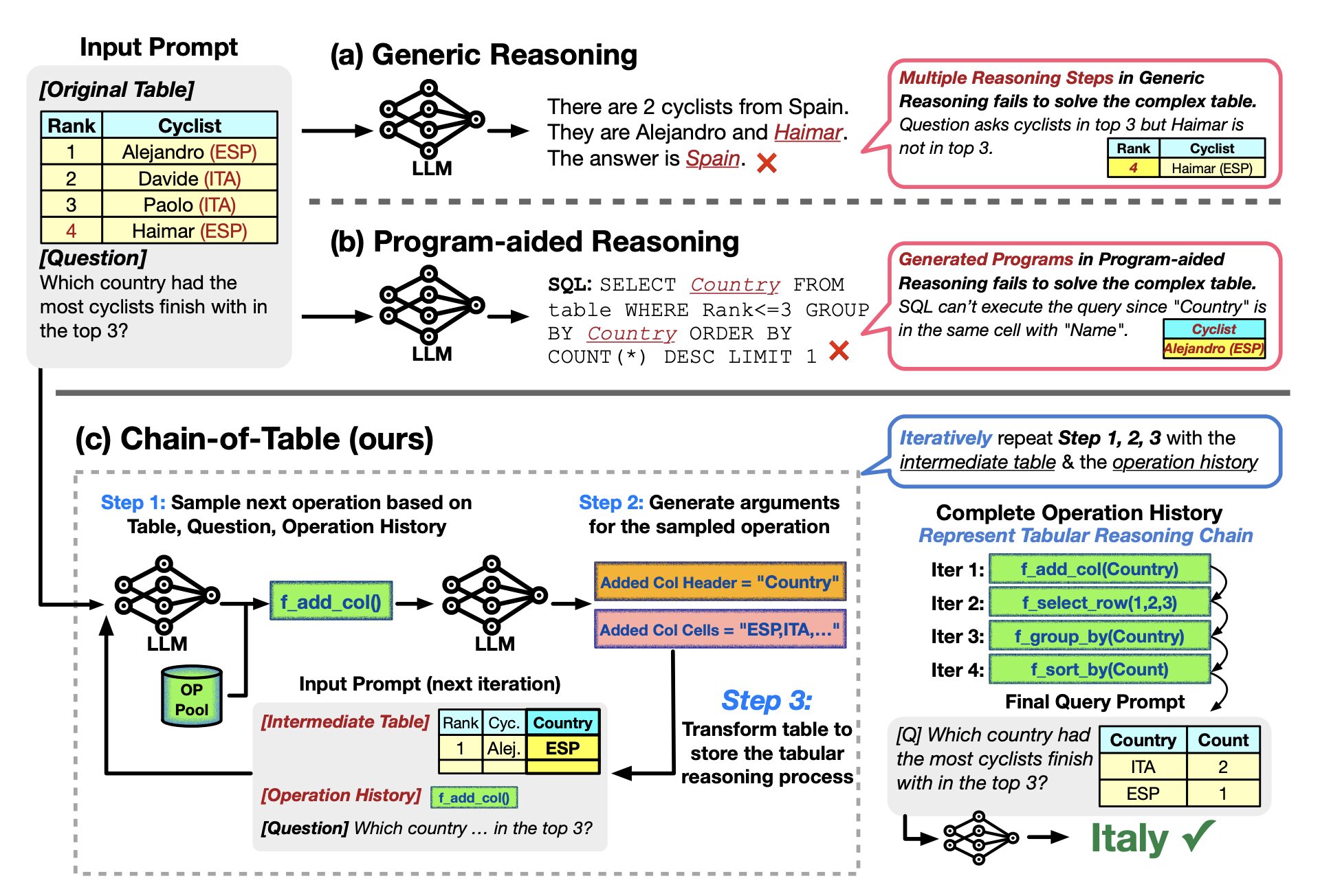
以下は、表の操作による表の更新ステップを記した疑似コードです。 chain に開始タグ [B] を持ってスタートして、表の操作が終了することを示す終了タグ [E] が生成されるまで表の更新を実行します。
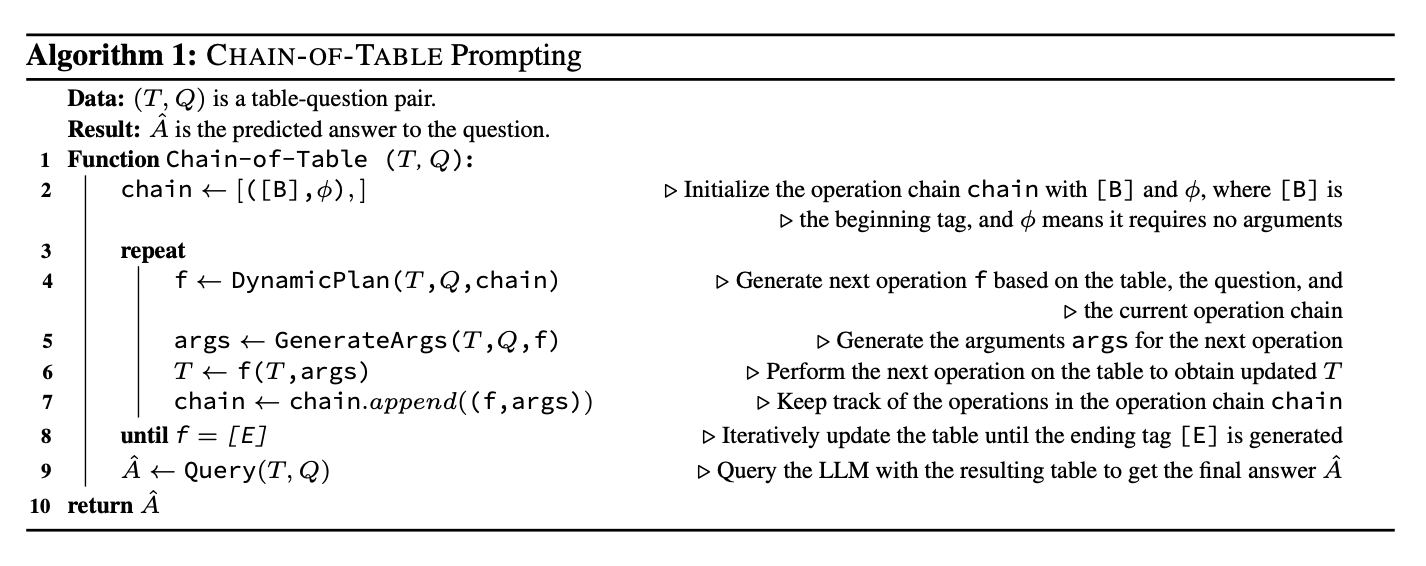
ここで、提案法では DynamicPlan と GenerateArgs という操作を定義しています。
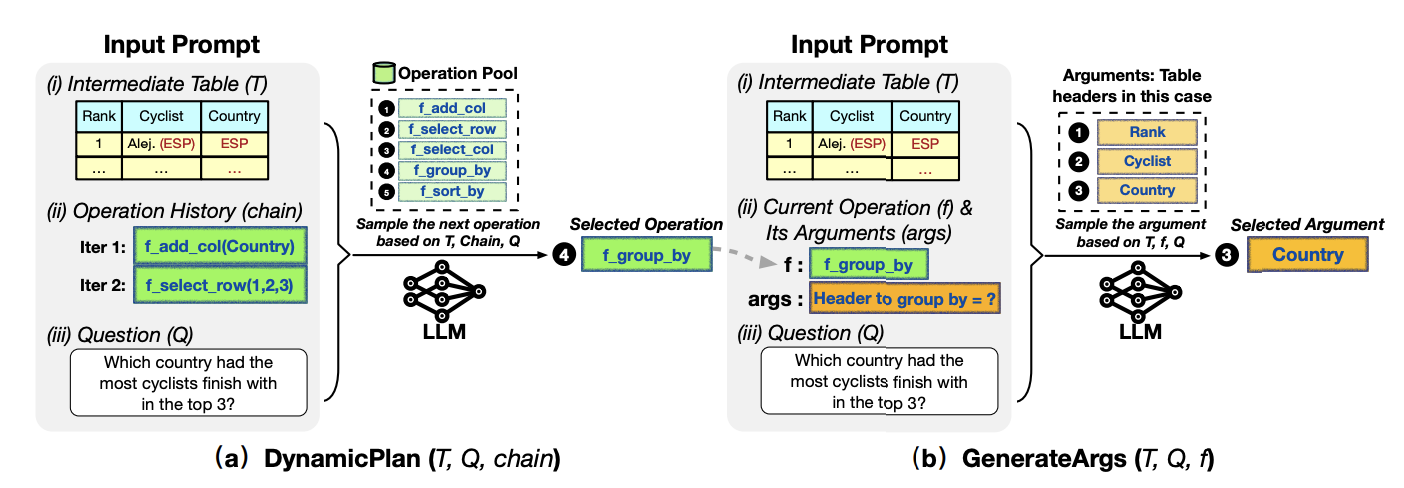
DynamicPlan では、図で示されるように (i)最新の表、(ii)操作履歴、(iii)質問の3つ項目を入力として、事前定義した操作から次の操作を選択します。また、GenerateArgs では、(i)表、(ii)Dynamic Plan で選択された操作、(iii)質問の3つの項目を入力として表操作の引数を生成します。表操作そのものの選択と、具体的にどういった内容の操作をするか (例えば、何について group-by するか等) を In-context Learning で行っているわけですね。
これらの操作を繰り返して表を更新し、最終的な回答を求めるという手法となっています。実験結果としては、Binder や Dater を凌駕する性能を見せています。
さらに本論文には Appendix に興味深い結果が掲載されています。
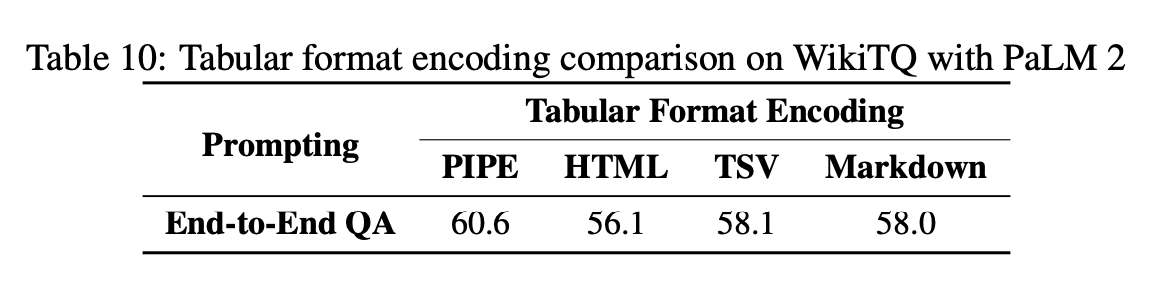
これはプロンプト内で表を文字列でどのように与えると、性能に良い影響を与えるかを試した結果です。もちろん先行研究と同条件で比較するために採用したということもありますが、 In-context Learning の性質上、前もって与えるプロンプト内での表の形式は非常に重要だと言えそうです。今回の報告では以下のような PIPE 形式が最も良かったようです。
col : Name | Grade | Course | Apartment Room No.
row 1 : Yuno | 2 | Art | 201
row 2 : Miyako | 2 | Art | 202
row 3 : Hiro | 3 | Art | 101
row 4 : Sae | 3 | Art | 102
row 5 : Nori | 1 | Art | 103
row 6 : Nazuna | 1 | General | 203
一概に全ての手法でこのような結果になるとは限りませんが、表を文字列化する際の1つの参考になりそうです。
試してみた
著者実装では無さそうですが、Chain-of-Table は LlamaIndex の LlamaHub で実装が公開されていたので、試しに使用してみました。
実行環境(Pythonバージョンと主要なライブラリのみ記載)は以下の通りです。Azure OpenAI を使用しています。
python = "3.11.6"
llama-index = "0.10.36"
llama-index-llms-azure-openai = "0.1.8"
python-dotenv = "1.0.1"
pandas = "2.2.2"
LlamaHub から実装をダウンロード。
from llama_index.core.llama_pack import download_llama_pack
ChainOfTablePack = download_llama_pack(
"ChainOfTablePack",
"./chain_of_table_pack",
)
LLM のモデルは gpt-4 と gpt-35-turbo で検証します。
from llama_index.llms.azure_openai import AzureOpenAI
llm_gpt35 = AzureOpenAI(
model="gpt-35-turbo",
deployment_name="your-gpt35-turbo-development-name",
api_key=api_key, # your api key
azure_endpoint=azure_endpoint, # your azure endpoint
api_version="2024-02-15-preview",
)
llm_gpt4 = AzureOpenAI(
model="gpt-4",
deployment_name="your-gpt-4-turbo-development-name",
api_key=api_key, # your api key
azure_endpoint=azure_endpoint, # your azure endpoint
api_version="2024-02-15-preview",
)
データとして、Pandas の DataFrame を渡すことができます。試しに、以下のデータで動かしてみましょう。
import pandas as pd
df = pd.DataFrame(
[
["Yuno", 2, "Art", 201],
["Miyako", 2, "Art", 202],
["Hiro", 3, "Art", 101],
["Sae", 3, "Art", 102],
["Nori", 1, "Art", 103],
["Nazuna", 1, "General", 203],
],
columns=["Name", "Grade", "Course", "Apartment Room No."],
)
Name Grade Course Apartment Room No.
0 Yuno 2 Art 201
1 Miyako 2 Art 202
2 Hiro 3 Art 101
3 Sae 3 Art 102
4 Nori 1 Art 103
5 Nazuna 1 General 203
試しに表に対する質問として、”What is the name of the student who lives in room 101?” と与えてみましょう。 gpt-4 の場合の実行の様子は以下の通りです。
from chain_of_table_pack.llama_index.packs.tables.chain_of_table.base import ChainOfTableQueryEngine
query_engine_gpt4 = ChainOfTableQueryEngine(
df,
llm=llm_gpt4,
verbose=True,
)
response = query_engine_gpt4.query("What is the name of the student who lives in room 101?")
print(response)
> Iteration: 0
> Current table:
col : Name | Grade | Course | Apartment Room No.
row 1 : Yuno | 2 | Art | 201
row 2 : Miyako | 2 | Art | 202
row 3 : Hiro | 3 | Art | 101
row 4 : Sae | 3 | Art | 102
row 5 : Nori | 1 | Art | 103
row 6 : Nazuna | 1 | General | 203
> New Operation + Args: f_select_row(['row 3'])
> Current chain: f_select_row(['row 3']) ->
> Iteration: 1
> Current table:
col : Name | Grade | Course | Apartment Room No.
row 1 : Hiro | 3 | Art | 101
> New Operation + Args: f_select_column(['Name', 'Apartment Room No.'])
> Current chain: f_select_row(['row 3']) -> f_select_column(['Name', 'Apartment Room No.']) ->
> Iteration: 2
> Current table:
col : Name | Apartment Room No.
row 1 : Hiro | 101
> Ending operation chain.
assistant: Hiro.
このようにうまく、人名を回答することに成功しました。関数選択やターゲットのための抽出がうまくいっていそうです。一方で、 gpt-35-turbo では以下の通り正規表現に関してエラーになってしまいました。
query_engine_gpt35 = ChainOfTableQueryEngine(
df,
llm=llm_gpt35,
verbose=True,
)
response = query_engine_gpt35.query("What is the name of the student who lives in room 101?")
print(response)
> Iteration: 0
> Current table:
col : Name | Grade | Course | Apartment Room No.
row 1 : Yuno | 2 | Art | 201
row 2 : Miyako | 2 | Art | 202
row 3 : Hiro | 3 | Art | 101
row 4 : Sae | 3 | Art | 102
row 5 : Nori | 1 | Art | 103
row 6 : Nazuna | 1 | General | 203
...
AttributeError: 'NoneType' object has no attribute 'group'
少しばかり動かしてみた所感としては、簡単な質問ならうまくいく一方で、処理途中で正規表現による抽出がうまくいかず実行が失敗するケースが見られました。今回例示したように、特に gpt-4 ではなく gpt-35-turbo の場合に発生したため、LLM の性能に依存する可能性もあります。GenerateArgs は正規表現ベースで実装されている (Section 3.3 参照) ため、引数抽出に失敗するということがあるようです。
おわりに
今回は In-context Learning をベースとして手法に採用している「表形式データの読み解き」に関する論文を、個人的ピックアップで紹介してみました。まだまだ課題はあるものの、LLM による表の解釈の日進月歩のスピード感を体感することができました。一方で In-context Learning の特性上、入力出来る表のサイズに制限があることも確かです。これは LLM の許容量にも依存する話でもありますが、どのように表というデータを扱っていくか、はたまた回答を得るための LLM への入力前にどのような操作を行っていくかを考えていくことが非常に重要だと考えます。
LLM でいい感じにデータを読み解けるアイデアがあればぜひお話しましょう。以下のカジュアル面談のページや、X (@nersonu) の DM 等でお気軽にお声掛けくださいませ。
■ 本文中ではうまくひねることができず、紹介し損ねたチームメンバーの他のブログ記事はコチラ
参考文献
(Cheng et al., ICLR 2023) Cheng, Z., Xie, T., Shi, P., Li, C., Nadkarni, R., Hu, Y., Xiong, C., Radev, D. R., Ostendorf, M., Zettlemoyer, L., Smith, N. A., & Yu, T. (2023). Binding language models in symbolic languages. International Conference on Learning Representations.
(Wang et al., ICLR 2024) Wang, L., Xu, W., Lan, Y., Hu, Z., Lan, Y., Lee, R. K.-W., & Lim, E.-P. (2024). Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. International Conference on Learning Representations.
(Ye et al., SIGIR 2023) Ye, Y., Hui, B., Yang, M., Li, B., Huang, F., & Li, Y. (2023). Large language models are versatile decomposers: Decompose evidence and questions for table-based reasoning. SIGIR ’23: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval.