
はじめに
こんにちは!芝浦工業大学理工学研究科 修士1年の只野陽生と申します。2026年2月の3週間にわたって現場配属型の就業型インターンシップ「CA Tech JOB」に参加し、AI事業本部の広告配信プラットフォームであるDynalystに配属させていただきました。
本記事では以下の内容について紹介します。
- アドテク・DSPおよびDynalystの概要
- 稼働中のログパイプラインに対するログ形式(tsv → jsonl)の移行設計
- タスクを通じて学んだ技術(Scalaの暗黙の型変換、Kinesis Data Streamsの内部構造、メッセージ配信保証など)
アドテクやインフラ移行に関心のある方の参考になれば幸いです。
アドテクとDynalystについて
アドテクとは
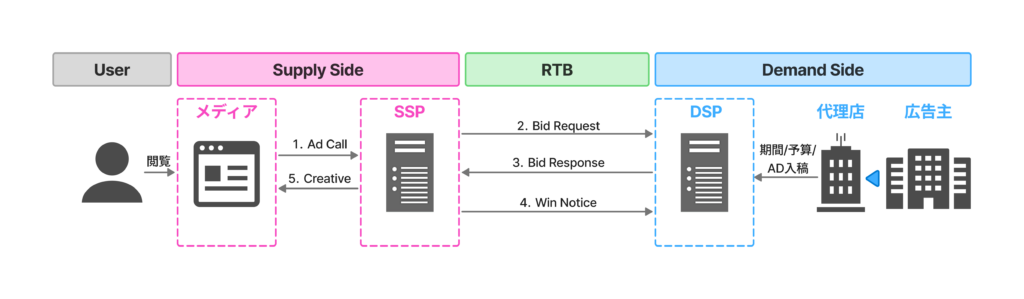
アドテクとは、インターネット広告の配信・最適化における技術のことです。その中核を担うのがSSP(Supply-Side Platform)とDSP(Demand-Side Platform)で、両者はRTB(Real-Time Bidding)と呼ばれるリアルタイム入札の仕組みで接続されています。
SSPはメディア側に立ち、保有する広告枠の収益最大化を目的として、複数のDSPに入札リクエストを同時送信します。DSPは広告主側に立ち、ユーザ属性や広告枠のコンテキストを特徴量として機械学習モデルでCTR・CVRを予測し、期待値に基づいた入札額を算出して応札します。SSP側で最高額を提示したDSPが落札され、そのクリエイティブが配信されます。
この一連の処理は通常100ミリ秒以内に完結する必要があり、低レイテンシなシステム設計とリアルタイム機械学習推論が求められます。
Dynalystについて
Dynalystは、サイバーエージェントのAI事業本部が提供するスマートフォン向けパフォーマンス型広告配信プラットフォーム(DSP)です。独自のターゲティング技術を用いて、アプリインストール後に離脱したユーザに再度アプリの起動を促すリターゲティング広告や、新規ユーザ獲得を目的とした新規インストール推進型広告の配信を行っています。最大で秒間50万リクエストという大規模トラフィックを処理しながら、機械学習モデルによるCTR・CVR予測を数ミリ秒単位のオンライン推論で実行し、最適な入札額をリアルタイムに決定しています。
タスクについて
内容について
今回のタスクは、広告の表示を計測するインプレッションサーバ(以下、Impサーバ)のログ形式をtsvからjsonlに移行し、CyCloud内のAKE → AWS → Snowflake に至るログパイプライン全体の改修を行うものです。
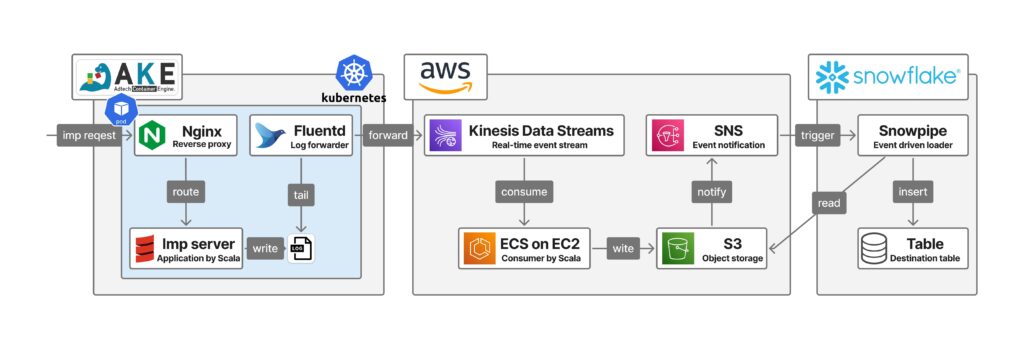
解決したい課題
従来、Impサーバのログはタブ区切りのtsv形式で扱われていました。しかしtsvは「位置(列番号)」でデータを特定するフォーマットであるため、運用面で以下のような課題がありました。
課題1:列の追加・削除が困難
S3に置かれたログファイルはSnowpipeが読み込み、COPY INTOでパースしてSnowflakeのテーブルに書き込まれます。このとき、tsv形式では $1, $2, $3, … のように列番号でカラムを参照するため、ログ側のスキーマとSnowpipe側のマッピングが密結合しています。
例えばログから不要な列を削除しようとした場合、ログファイル側だけを変更すると、それ以降の列が一つずつ前にずれ、Snowpipeが誤った列を誤ったカラムに書き込んでしまうという問題が発生します。
その結果、後方互換性を維持するには列を消せず、新しい列は常にテーブルの末尾に追加するしかないという運用ルールが定着し、テーブルのカラム数がひたすら膨張していく状態になっていました。
課題2:巨大化したテーブルによる2次的な問題
カラム数の肥大化は、以下のような問題も引き起こしていました。
- テストの記述コストが高い:巨大なログやテーブルの列番号を意識しながらテストケースを作成する必要があり、列の意味を把握・確認するのが手間になる
- クエリや運用の複雑化:カラム数が増えることで、SELECT *を含む分析クエリやテストデータ作成、スキーマ管理の負荷が高まり、結果としてコストやレイテンシに影響する可能性がある
- 可読性の低下:どの列が何を意味するのかを把握しづらくなっている
このように、ログフォーマットそのものが後方互換性を持ちにくい構造であるという点が根本原因であり、上記のような問題を引き起こしていました。
tsv形式とjsonl形式の違い
tsv(Tab-Separated Values)
各行がタブ区切りの値の並びになっているフォーマットです。値の意味は「位置(列番号)」で決まるため、スキーマ定義が別途必要です。
2026-04-27T10:00:00 user_123 /ad/impression 200 45
この行を見ても、200 がHTTPステータスなのかカウントなのかは判断できません。
jsonl(JSON Lines)
各行が1つのJSONオブジェクトになっているフォーマットです。フィールド名が値とペアで含まれているため、各値の意味を簡単に把握できます。
{"timestamp":"2026-04-27T10:00:00","user_id":"user_123","path":"/ad/impression","status":200,"latency_ms":45}
比較表
| 観点 | tsv | jsonl |
|---|---|---|
| データの特定方法 | 位置(列番号) | キー(フィールド名) |
| スキーマ情報 | ファイル外で管理 | フィールド名を各レコード内に持つ |
| 列の追加 | 末尾のみ安全 | どこでも安全 |
| 列の削除 | 後方互換性が崩れる | 該当キーを消すだけ |
| 列の並び替え | 不可能 | 可能 |
| ファイルサイズ | 小さい | やや大きい |
| 人間の可読性 | 低い | 高い |
表1. TSVとJSONLの比較
不備があっても切り戻せる移行設計
ここでは私が当初提案した移行手順とその問題点、最終的な移行手順について解説します。
初期案と問題点
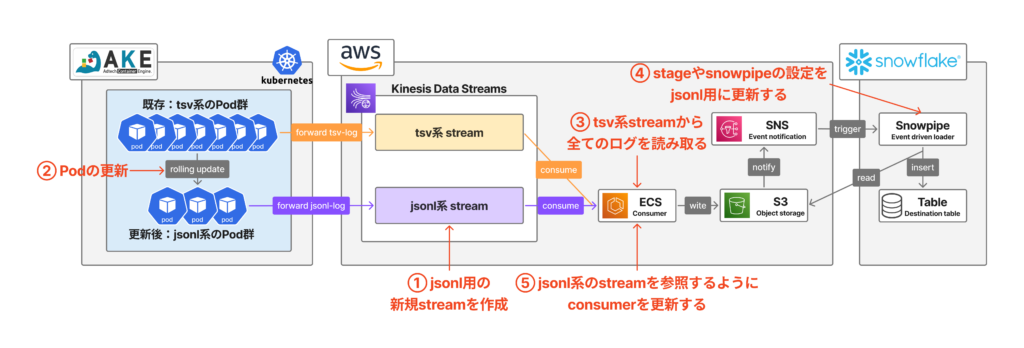
私は最初に上図のような移行手順案を考案しました。ポイントはKinesis Data Streamsのストリームをjsonlログ用に新しく作成して、図中の①〜⑤の順番で適宜更新をかけていくというものでした。またストリームにはretention periodというレコードがストリーム内で保存される期間を設定でき、これを十分長く設定することでパイプラインにおける後続の実装に不備があった時でもストリーム内にログを留めておけます。またtsvログを完全に保存し切った後にECSを更新できるように、graceful shutdownを行うことも考案しました(既に実装済みでしたが)。具体的な手順は以下のようになります。
- Kinesis Data Streamsにjsonlログ用のストリームを新規作成します。この時に、retention periodを十分長く設定します。
- AKEのKubernetesクラスターにjsonlログに対応したPodをデプロイします。この時、既存のPodはKinesisのtsvストリームにtsvログを転送して、後続のパイプラインを経由してSnowflakeのテーブルに保存されますが、更新がかかったPodはjsonlストリームへjsonlログを転送します。この時点ではjsonlストリームはECSから参照されていないため、ログは1.で設定したretention periodの期間中ストリームに滞留し続けます。
- 2.のPod更新が完了するとtsvストリームへのtsvログ転送がなくなります。ここで、ECSがtsvストリーム内の未処理分をすべて読み取り、Snowflakeへの保存が完了するのを待ちます。消費が全て完了すると、既存のパイプラインにはログが一時的に流れなくなります。
- SnowflakeのS3外部ステージおよびSnowpipeの設定をtsv形式からjsonl形式へ更新します。
- jsonlログを流す準備が完了したので、ECSの参照先をtsvストリームからjsonlストリームへ変更し、滞留していたjsonlログをパイプラインに流すことで移行を完了させます。
この方法でもログ形式の移行はできますが、以下のような問題があるため採用しないことになりました。
- ECSやSnowflake、Snowpipeの設定に実装ミスがあった場合、ログが消失するリスクがある。
- AKEの全Podの更新が完了するまでjsonlログをSnowflakeに保存できないため、データに遅延が生じる。
最終的な移行手順
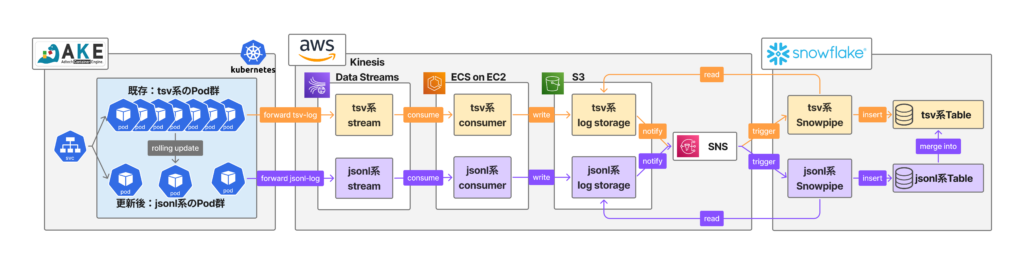
最終的には上図のようにtsv系のパイプラインとjsonl系のパイプラインを並列に構築し、ごく少量のjsonlログを流して(この時、tsvログは100%従来通り保存される)jsonl系テーブルに正常に保存されることを確認した後、AKEの全てのPodをjsonl系へ更新しました。
またrolling update中はtsv系テーブルとjsonl系テーブルの両方にログが書き込まれるため、jsonl系テーブルの内容を親となるtsv系テーブルへ適宜MERGE INTOを実行してデータを統合させました。更新完了後は、jsonl系テーブルには存在するがtsv系テーブルには存在しないレコードをテーブルJOINで抽出し、jsonl系テーブルで取得したログがtsv系テーブルへ漏れなく取り込まれているかを検証することで、ログ欠損の有無を確認しました。
なお、以下のサンプルSQLでは説明の都合上 tsv_log / jsonl_log というテーブル名を用いていますが、実際のプロダクション環境ではこれらとは異なる名称を使用しています。
-- jsonl_log(マージ元)の内容を tsv_log(マージ先)へ移動する
-- request_id をキーに、tsv_log にまだ存在しないレコードのみINSERTする
MERGE INTO tsv_log AS tgt
USING jsonl_log AS src
ON tgt.request_id = src.request_id
WHEN NOT MATCHED THEN
INSERT (column1, column2, ...)
VALUES (src.column1, src.column2, ...);
-- jsonl_log には存在するが tsv_log には存在しないレコード数をカウントし、
-- ログ欠損が発生していないかを検証する
SELECT COUNT(*) AS missing_count
FROM MY_DB.MY_SCHEMA.jsonl_log AS j
LEFT JOIN MY_DB.MY_SCHEMA.tsv_log AS t
ON j.request_id = t.request_id
WHERE j.request_id IS NOT NULL
AND t.request_id IS NULL;
詰まったところ&業務中に得た知見
Scalaの暗黙の型変換
本タスクに取り組むにあたり、最初にImp-serverでjsonlログを出すようにコードを修正しようとしました。impLog.tsvをimpLog.jsonlに書き換えて、ImpLogクラスにjsonlメソッドを新規で定義すれば良いだけだと高をくくっていたのですが、ImpLogクラスにはそもそもtsvメソッドすら定義されていなかったのです。
初日あたりは環境構築と並行してタスクの理解を深めていたタイミングで、Scalaの環境やIntelliJ、AIも導入していない状態だったためコードジャンプもできず、どのような仕組みで動いているのかさっぱりわかりませんでした。メンターに相談したところ、Implicit Conversionsという仕組みで動いていることを知りました。
Implicit Conversionsとは
ある型から別の型への変換を暗黙的(自動的)に行う仕組みです。本来存在しないメソッドを呼んだとき、コンパイラがimplicit変換を探して自動的に型変換してくれます。
// jsonlメソッドを持つラッパークラス
class jsonlOps(p: Product) {
def jsonl: String = (jsonlへの変換処理)
}
// implicit conversionの定義
implicit def productTojsonlOps(p: Product): jsonlOps = new jsonlOps(p)
// 使う側
case class ImpLog(id: Int, message: String)
val impLog = ImpLog(1, "hello")
impLog.jsonl // コンパイラが自動でjsonlOps(impLog).jsonlに変換
なぜImpLogをProduct型として渡せるのか
ImpLogはcase classです。Scalaのcase classは定義するだけで、コンパイラが自動的にProduct traitを実装します。
case class ImpLog(id: Int, message: String)
// 実質以下と同じ
class ImpLog(...) extends Product { ... }
そのためImpLogはProductのサブタイプとなり、Productを受け取るjsonlOpsにそのまま渡すことができます。これはJavaやScalaの継承と同じく、子クラスは親クラスの型として扱えるというルールによるものです。
処理の流れ
impLog.jsonl を呼ぼうとする ↓ ImpLogにjsonlが見つからない ↓ コンパイラがimplicit変換を探す ↓ productTojsonlOpsでjsonlOpsに変換できると判断 ↓ new jsonlOps(impLog).jsonl() として実行
Implicit Conversionsのメリット
メリットは既存のクラスに手を加えずメソッドを追加できる点です。通常の継承ではクラスが増えるほど継承関係が複雑になりますが、Implicit Conversionsを使うとシンプルに記述できます。jsonlという機能はあくまでjsonlOpsの責務であることが明確になり、クラスの責務が分離されて見通しが良くなります。
Kinesis Data Streams内でRecordがどのように格納されるのか
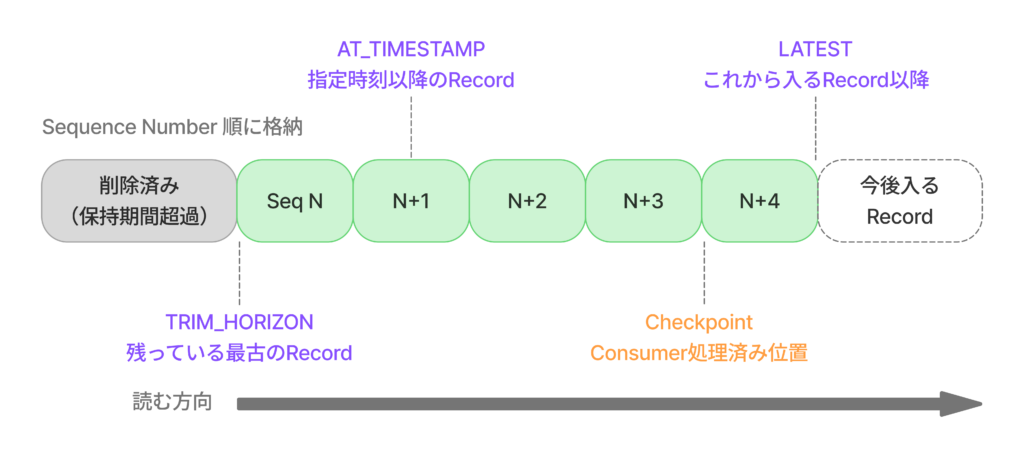
Kinesis Data StreamsにはStreamやShardという概念があり、Shardが並列処理やスループットに関わることは知っていました。
一方で、実際にタスクに取り組む中で、Shardの中にデータがどのように格納され、Consumerがどの位置からデータを読み始めるかについては理解が曖昧であったため、Kinesis内のデータを確認する際に、どの範囲のデータを見れば良いか迷う場面がありました。
そこで調べる中で、Kinesis Data Streamsでは、Producerが送信したRecordがPartition Keyに基づいてShardに振り分けられ、Shard内ではSequence Number付きで順番に並ぶことを知りました。Consumerは、そのShard内のRecordを指定した開始位置から順に読み取ります。
その読み取り開始位置として、TRIM_HORIZON、LATEST、AT_TIMESTAMPなどの指定があります。例えば、LATESTはこれから新しく入ってくるRecordを読むための指定で、AT_TIMESTAMPは指定した時刻以降のRecordを読むための指定です。今回特に理解が深まったのはTRIM_HORIZONで、これはShard内に現在残っている最古のRecordの位置を指します。Kinesisのデータは保持期間を過ぎると削除されるため、TRIM_HORIZONは「Kinesisに残っている範囲の先頭」と捉えると理解しやすいと感じました。
また、Consumer側にはCheckpointという考え方があることも学びました。Checkpointは、Consumerがどこまで処理したかを記録する位置です。例えば、Consumerの再起動時にはCheckpoint位置から続きの処理を開始します。KCLはこのDynamoDBテーブルを使って、各Shardに対する処理済み位置や、どのConsumer WorkerがどのShardを担当しているかといった情報を管理します。
メッセージ配信保証
Kinesis Data Streamsを扱う中で、メッセージがどのようにConsumerへ配信されるかについて考える機会がありました。特に、Consumerが途中で失敗した場合、再起動時に同じRecordが再処理されるのか、それともRecordが失われるのかが気になりました。
そこで、メッセージ配信にはいくつかの保証レベルがあることを知りました。代表的なものとして、At most once、At least once、Exactly onceがあります。
At most onceは、メッセージが最大1回だけ処理される方式です。重複処理は発生しない一方で、Consumerの失敗などによってメッセージが失われる可能性があります。つまり、「重複は避けたいが、欠落が起きる可能性はある」という考え方です。
At least onceは、メッセージが少なくとも1回は処理される方式です。Consumerが処理後にCheckpointを保存する前に失敗した場合などには、同じRecordが再度処理される可能性があります。そのため、重複処理は起こり得ますが、メッセージを失わないことを重視する方式です。
Exactly onceは、メッセージが過不足なく1回だけ処理される方式です。一見理想的ですが、実際の分散システムでは、ネットワーク障害やConsumerの失敗、外部DBへの書き込みなどが絡むため、完全に実現するのは難しいです。そのため、実務ではメッセージ基盤だけでExactly onceを期待するのではなく、Consumer側や保存先のDB側で冪等性を持たせることが重要だと学びました。これを実現するには例えば、各Recordに一意なIDを持たせておき、Consumer側で同じIDを二重に処理しないようにすることで、再処理が発生しても結果が壊れにくくなります。また、DBに書き込む場合も、ユニークキーやUpsertを使うことで、同じイベントが複数回届いても最終的な状態が変わらないようにできます。
今回のタスクを通じて、Kinesis Data Streamsを使う際には、RecordがConsumerに届くことだけでなく、Consumerの失敗や再処理を前提に設計する必要があると理解しました。特に、At least onceの考え方を前提に、重複しても問題が起きないような冪等な処理を意識することが重要だと学びました。
エンジニアとしての学び
本タスクを通じて、技術面・働き方の両面で多くの学びを得ることができました。記事の中で触れた移行設計や冪等性といった、稼働中システムを扱う上で欠かせない考え方に加えて、zoxideやCLI操作の工夫、ターミナルのセッション管理といった日々の作業効率を高めるための知見も多く得られました。また、ScalaのImplicit ConversionsやKCL、Snowpipeなど、これまで触れたことのない技術と多く出会う中で、未知の技術に出会ったときに自分なりにキャッチアップしていく進め方も身につけることができたと感じています。
- 不備があっても安全に切り戻せる移行設計
- 冪等性を考慮した設計
- シンプルに考える
- 作業効率の向上(ターミナルのセッション管理、zoxide、vim、ペイン分割など)
- 知らない技術と出会ったときのキャッチアップ法
- 自分の中で仮説を持った上で質問する
- パイプラインの設定不備を無闇に探さず、二分探索的に原因箇所を探す
反省点
一方で、振り返ると改善すべき点もありました。
- ライブラリの技術選定が曖昧だった
JSONシリアライズにScalaのcirceを採用しましたが、circeで対応しきれない例外ケースが発生した場合の代替案を事前に検討できていませんでした。本来であれば、選定の段階で「採用するライブラリでカバーできない範囲はどこか」「その場合にどう対処するか」まで踏み込んで考えるべきだったと感じています。 - ターミナルのセッション管理が下手だった
複数の作業を並行して進める中で、タブやウィンドウが散乱してしまい、SSH接続を張り直したり同じコマンドを何度も打ち直したりと、無駄な手間が発生する場面がありました。tmuxなどを活用したセッション管理を早い段階で身につけておけば、よりスムーズに作業を進められたと思います。 - TerraformやKCLの細かい設定を把握しきれないまま全体の整合性を取ってしまった
並列パイプラインを構築する都合上、既存設定を踏襲する形で進めた箇所がありましたが、本来であれば一つひとつの設定値の意味を理解した上で採用・変更の判断をすべきでした。動作はしているものの、なぜその設定なのかを説明しきれない部分が残ってしまったことは、今後の課題として持ち帰りたいと思います。
まとめ
本記事では、DynalystのImpサーバのログ形式をtsvからjsonlへ移行し、CyCloud → AWS → Snowflake に至るログパイプライン全体を改修したタスクについて紹介しました。ポイントは、tsv系とjsonl系のパイプラインを並列に構築し、少量のjsonlログを流して検証してから段階的にjsonlへ切り替えることで、不備があっても切り戻せる移行手順にしたことです。MERGE INTOによるテーブル統合とJOINによるログ欠損チェックを組み合わせ、データ整合性も担保できました。
最後に
実際の開発現場に入ることで、普段の開発では経験できないような大規模開発の一部を経験することができました。特に、稼働中のシステムの移行作業やログパイプラインの移行設計に携わる機会は今回が初めてで、シンプルかつ安全に進めるための設計をどう組み立てるかを実践的に考えられたことは、エンジニアとして非常に良い経験になりました。ここで得た学びを、今後の業務にも活かしていきたいと考えています。
エンジニア職の方だけでなくビジネス職の方ともお話しさせていただき、ランチにもご一緒させていただく中で、仕事内容ややりがいについて多くを伺うことができました。また、これまでエンジニア職以外の方に自分の技術的な取り組みを伝える機会がなかったため、分かりやすく伝えることを意識する良い機会にもなりました。
インターン開始時には、目標の一つとして「プロダクトに対する知識を深め、エンジニアとしてビジネス的観点でも貢献する」を掲げていました。13日間という期間の中で完全に達成することは難しかったものの、自分のタスクがDynalystにもたらす効果を深く考え、ビジネス職の方にも噛み砕いて伝えることを意識することで、目標達成へのアプローチを試みました。
インターン終了後に改めて振り返ってみると、自分にとってのビジネス的観点とは、
- 企画の段階から技術的なオーナーシップを持ってプロジェクトを前に進めること
- プロジェクトのKPI改善のために技術的に何ができるかを考え、提案・実践すること
であると言語化することができました。
最後になりましたが、トレーナーの方をはじめ、お世話になった皆様に心より感謝申し上げます。本当にありがとうございました。