
株式会社 AbemaTV で SRE / Platform Engineer をしている 後藤(@ren510dev)です。
Datadog Agent を v7.66 から v7.76 にアップグレードしたところ、agent コンテナの CPU 使用率が 2〜3 倍に急増する問題を引きました。
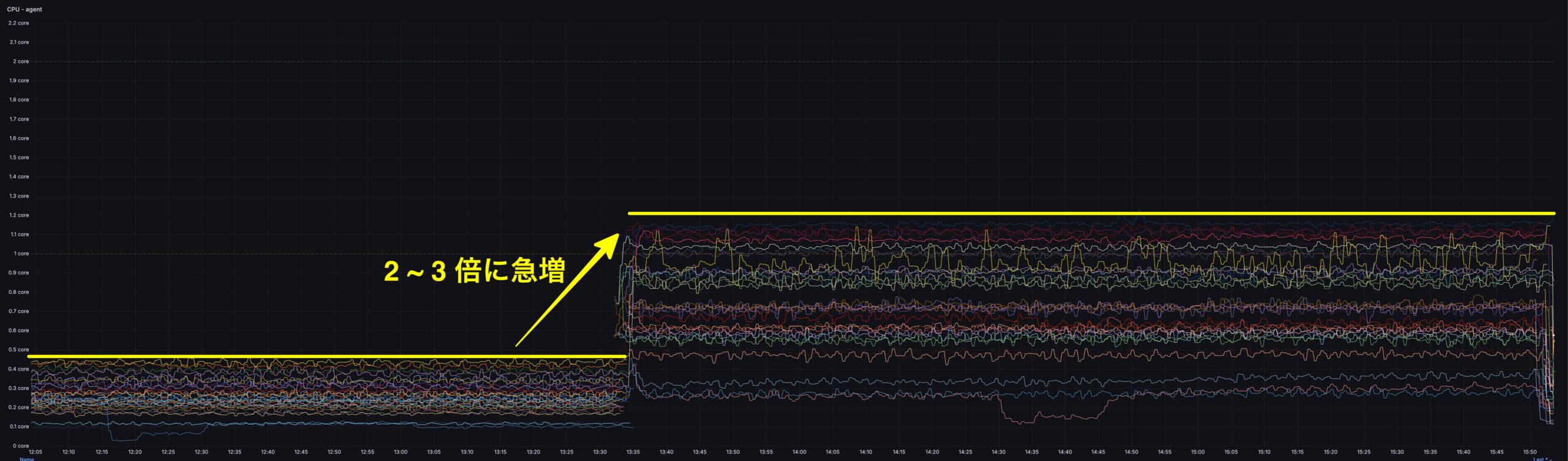
影響は istio-proxy が多数稼働するノードに集中しており、Agent が内部で利用する Python ベースの prometheus-client ライブラリのパーサ回帰によって、Prometheus テキスト形式のパース処理コストが大幅に増大したことが原因でした。
本記事では flare を使った原因の絞り込み方、パーサ回帰の技術的な詳細と特定の環境で影響が顕著になった理由、現時点でのコミュニティの認識と対応方針についてまとめます。
目次
- flare を使ったボトルネックの調査
- メトリクスのパース機構
- 特定の環境で顕著になる理由
- フィルタリングでは解決しない理由
- コミュニティの現状認識
- おわりに
1. flare を使ったボトルネックの調査
Datadog Agent には flareという診断バンドルの仕組みがあり、Agent の状態をスナップショットとして取得できます。flare はサポートへの問い合わせだけでなく、自力での原因分析にも活用できます。
今回 CPU が急増した問題では、flare に含まれる以下 3 つのデータが原因特定に役立ちました。
CPU プロファイル
flare には Go の pprof 形式の CPU プロファイルが profiles/core-cpu.pprof に含まれています。これを分析すると、CPU 時間の大半を消費しているコールスタックを特定できます。
今回のケースでは _Cfunc_run_check(Go から Python check を呼び出す CGO 境界)が CPU の 85% 以上 を占めていました。
$ go tool pprof -top profiles/core-cpu.pprof
File: agent
Type: cpu
Duration: 30.10s, Total samples = 32.38s (107.56%)
Showing nodes accounting for 29.41s, 90.83% of 32.38s total
Dropped 725 nodes (cum <= 0.16s)
flat flat% sum% cum cum%
27.81s 85.89% 85.89% 28.53s 88.11% runtime.cgocall
0.46s 1.42% 87.31% 0.46s 1.42% runtime.futex
0.41s 1.27% 88.57% 0.41s 1.27% internal/runtime/syscall.Syscall6
0.14s 0.43% 89.01% 0.29s 0.9% regexp.(*Regexp).tryBacktrack
0.13s 0.4% 89.41% 0.45s 1.39% runtime.scanobject
...

累積(cum)順に並べ替えるとコールチェーンが確認できます。
$ go tool pprof -cum -top profiles/core-cpu.pprof
flat flat% sum% cum cum%
27.81s 85.89% 85.89% 28.53s 88.11% runtime.cgocall
0 0% 85.89% 28.43s 87.80% ...middleware.(*CheckWrapper).Run
0 0% 85.89% 28.43s 87.80% ...runner.(*Runner).newWorker.func1
0 0% 85.89% 28.43s 87.80% ...worker.(*Worker).Run
0 0% 85.89% 27.97s 86.38% ...python.(*PythonCheck).Run
0 0% 85.89% 27.97s 86.38% ...python.(*PythonCheck).runCheck
0 0% 85.89% 27.97s 86.38% ...python.(*PythonCheck).runCheckImpl
0 0% 85.89% 27.97s 86.38% ...python._Cfunc_run_check
0 0% 85.89% 0.93s 2.87% ...aggregator.(*BufferedAggregator).run
0 0% 85.89% 0.85s 2.63% ...serializer.(*Serializer).SendIterableSeries
0 0% 85.89% 0.69s 2.13% ...python.SubmitMetric
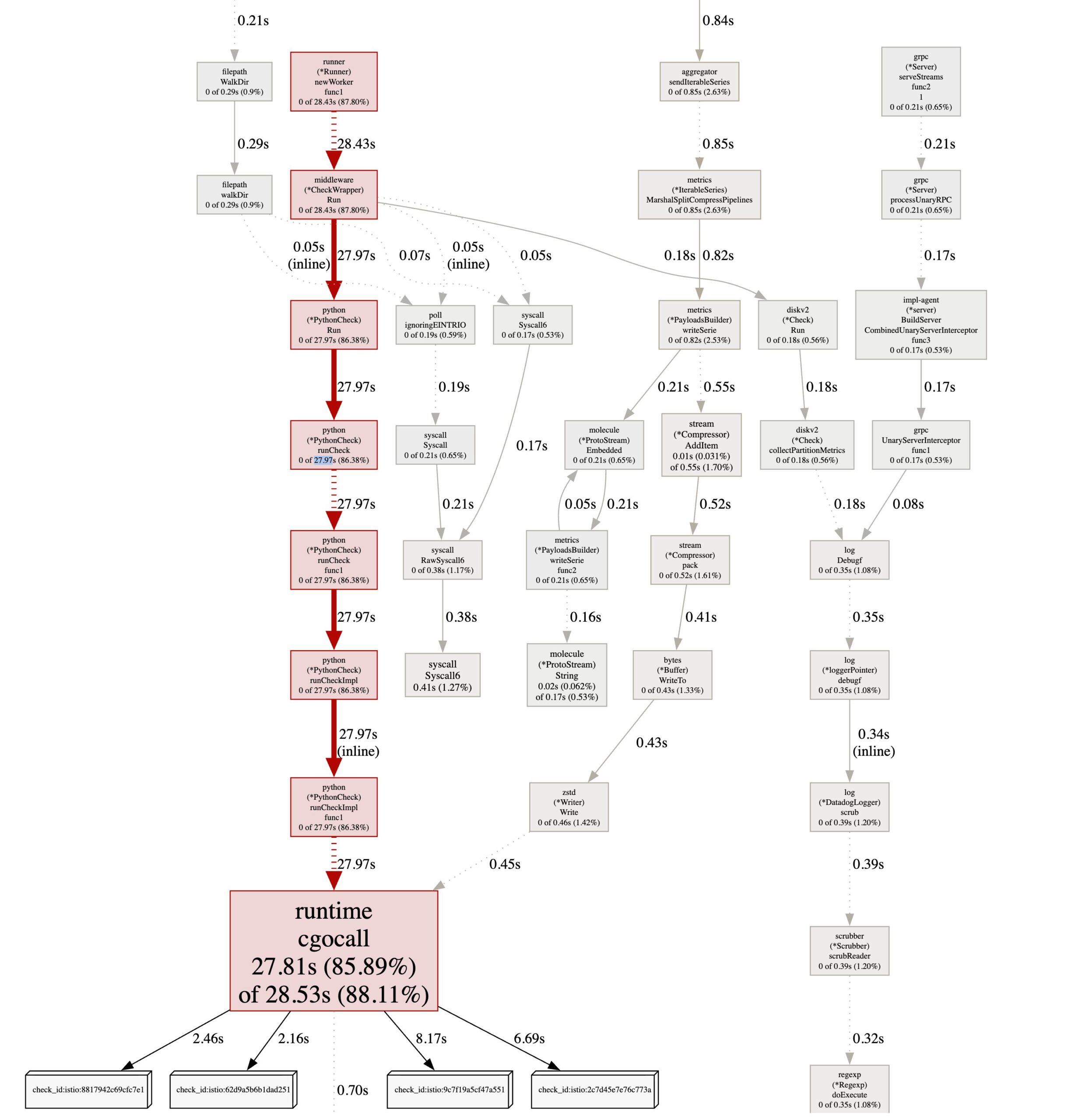
0 0% 85.89% 27.97s 86.38% ...python._Cfunc_run_checkCPU サンプル 32.38s のうち 27.97s、実に 86.4% が _Cfunc_run_check に集中しており、Go → Python の CGO 境界が CPU ボトルネックになっていることが分かります。
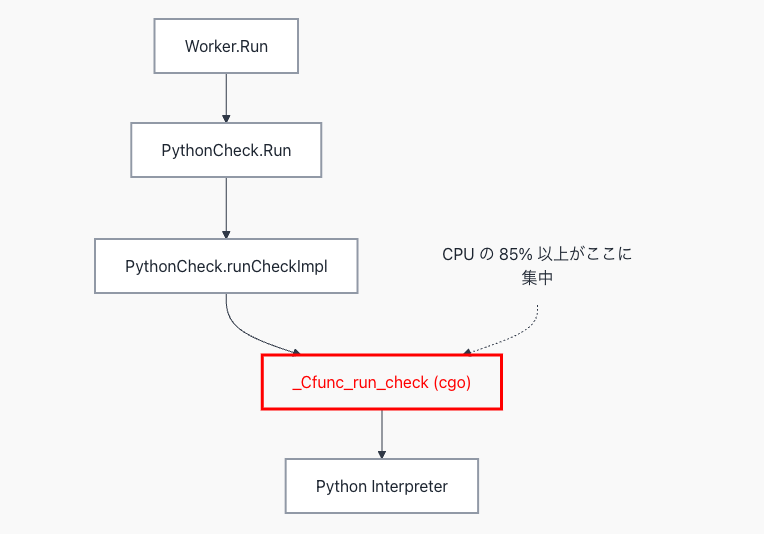
このことから、ボトルネックとなっている箇所は Python で実装されたコンポーネントにある と推測できます。
check 実行時間
status.log には各 check インスタンスの AverageExecutionTime(平均実行時間)と MetricSamples(取得されたメトリクスの数)が記録されています。MetricSamples は check が 1 回の実行で取得したメトリクスの数を表します。
MetricSamples: The number of fetched metrics.
アップグレード前後の flare を比較すると、どの check の実行時間が変化したかを一目で確認できます。
Check MetricSamples (Last Run) Average Execution Time
istio:9c7f19a5cf47a551 21,446 14.302s
istio:2c7d45e7e76c773a 14,614 13.201s
istio:8817942c69cfc7e1 4,274 5.254s
istio:62d9a5b6b1dad251 3,910 4.583s
istio:850adbc06398ddfe 3,638 4.170s
istio:404f7220365d8442 2,066 3.037s
istio:afde4b32e4f8803e 2,586 2.935s
istio:ab81eef1926ffa84 1,682 2.341s
istio:7fd1cb2367a2ee44 2,066 2.098s
istio:bf74166253783a60 1,178 1.446s
istio:a5c1fddf1a7bf9ac 514 0.866s
kubelet 397 0.327s
disk 26 0.120s
container 282 0.029s
cpu 4 0.015s
containerd 70 0.010s
network 8 0.001s
docker 0 0.001s
istio check だけが秒単位の実行時間になっており、他の check は全て ms 単位で完了しています。
### v7.66(アップグレード前)
istio check AverageExecutionTime: 1,851ms
MetricSamples: 23,534
### v7.76(アップグレード後)
istio check AverageExecutionTime: 14,302ms ← 7.7 倍に増大
MetricSamples: 21,446 ← サンプル数はほぼ同じ
v7.66 では 1 インスタンスあたり平均 1.85 秒だった実行時間が、v7.76 では最大 14.3 秒(7.7 倍)に増大しています。サンプル数が多いインスタンスほど実行時間が長く、他の check には変化がありませんでした。
処理サンプル数はほぼ同じなので、1 サンプルあたりの処理コスト自体が増大している と推測できます。
check worker の利用率
expvar/runner には check worker の利用率が記録されています。worker の利用率は check の実行時間 / check interval に比例するため、どの check が worker を占有しているかの指標になります。
### expvar/runner(実測)
Running:
istio:2c7d45e7e76c773a: "2026-04-30T05:49:43Z"
istio:9c7f19a5cf47a551: "2026-04-30T05:49:40Z"
istio:850adbc06398ddfe: "2026-04-30T05:49:45Z"
istio:ab81eef1926ffa84: "2026-04-30T05:49:46Z"
RunningChecks: 4 ← 4 worker 全てが istio check で占有
Workers:
Count: 4
Instances:
worker_1: { Utilization: 0.79 }
worker_2: { Utilization: 0.74 }
worker_3: { Utilization: 0.81 }
worker_4: { Utilization: 0.76 }
RunningChecks: 4 は worker 数と一致しており、スナップショット取得時点で 4 つの worker 全てが istio check の実行に占有されていました。各 worker の利用率は 74〜81% に達しており、check interval 15 秒のうち約 12 秒間は istio check が worker を占有している計算になります。
これらの分析結果から、CPU 負荷の主因は istio check で、処理サンプル数はほぼ変わっていないにもかかわらず実行時間が 7 倍以上に増大していることが分かりました。
この実行時間の増大についてさらに調査を進めたところ、istio check が内部で使用しているメトリクスパーサに回帰があることが分かりました。
2. メトリクスのパース機構
istio check のスクレイピング
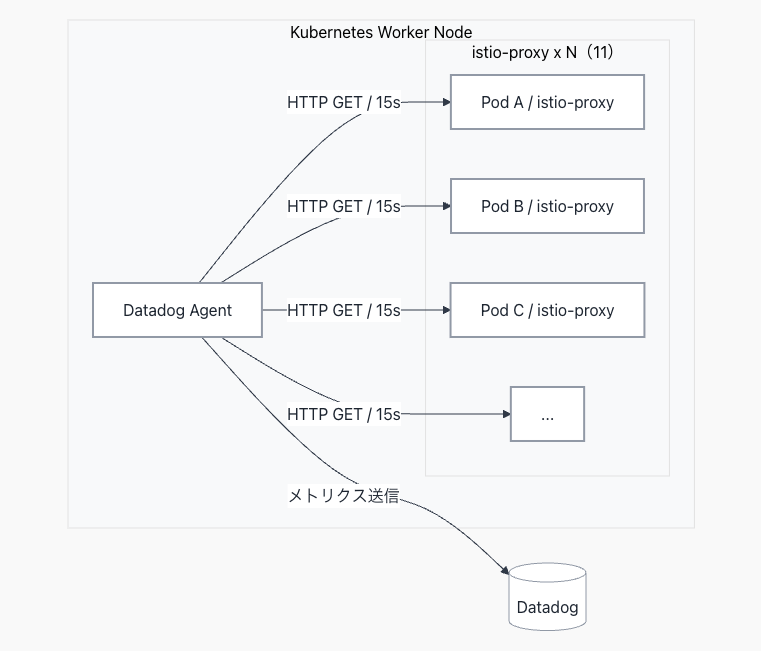
Datadog Agent の istio check は Python で実装されており、各 istio-proxy sidecar の /stats/prometheus エンドポイントを 15 秒毎にポーリング、Prometheus テキスト形式のメトリクスをパースして Datadog に送信します。
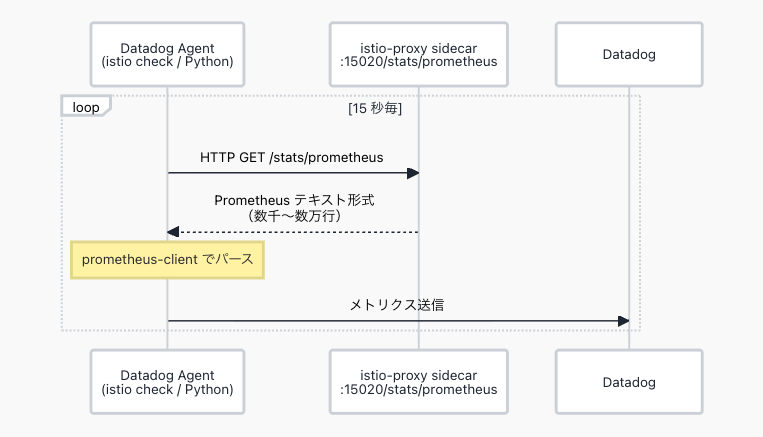
istio check が取得するレスポンスは以下のような Prometheus テキスト形式です。
# HELP envoy_cluster_upstream_rq_retry Total upstream request retries
# TYPE envoy_cluster_upstream_rq_retry counter
envoy_cluster_upstream_rq_retry{cluster_name="outbound|8080||foo.default.svc.cluster.local"} 3
istio_requests_total{reporter="source",source_app="bar",response_code="200"} 1452
prometheus-client のパーサは、このテキストを 1 行ずつ読み取り、行の種別判定、メトリクス名の抽出、ラベルのパース、値の変換を経て、Datadog が理解できるデータ構造に変換します。ノード上に複数の istio-proxy sidecar が稼働している環境では、1 つの Agent が複数インスタンス分のスクレイピングを並列で実行します。
パーサ回帰による性能劣化
prometheus-client v0.22.0 ではパーサが大幅に変更されました。
具体的には、これまで正規表現ベースで実装されていたパーサが引用符の中にある特殊文字({、# 等)を誤検出するバグがあり、UTF-8 も正しく扱えなかったため、文字単位で走査するパーサに置き換えられました。
この変更自体は正当な機能修正ですが、ASCII のみのテキストでもマルチバイト文字を考慮した 1 文字ずつの走査が行われるため、従来の C 実装による一括検索と比べて深刻な性能劣化が発生しました。
特に、Envoy / Istio 関連のメトリクスは Prometheus の仕様上 ASCII が推奨されており、実運用上も大半 ASCII で構成されていると、UTF-8 対応の恩恵がないまま性能劣化だけを受けます。
### ASCII のみ(Envoy / Istio の典型例)
envoy_cluster_upstream_rq_retry{cluster_name="outbound|8080||foo.default.svc.cluster.local"} 3
istio_requests_total{reporter="source",source_app="bar",response_code="200"} 1452
### UTF-8 マルチバイト文字を含む例
http_requests_total{error_message="接続がタイムアウトしました"} 5
app_notifications_total{template="【重要】お支払い期限のお知らせ"} 120
Metric names SHOULD match the regex
[a-zA-Z_:][a-zA-Z0-9_:]*
Label names SHOULD match the regex[a-zA-Z_][a-zA-Z0-9_]*
変更前後の実装の違い
- 変更前(v0.21.1 まで)
find() / rindex() は C 実装の文字列検索で、1 回の呼び出しで区切り文字の位置を特定します。Python Interpreter のオーバーヘッドは呼び出し回数分(行あたり数回)で済みます。
- 変更後(v0.22.0 以降)
_parse_sample() から呼ばれる _next_unquoted_char() の実装は以下の通りです。
変更前の find() / rindex() は C 実装に処理を委譲するため Python レベルのループは発生しません。変更後の _next_unquoted_char() は while i < len(text) で全文字を Python レベルで走査し、各文字毎に引用符の内外判定と _is_character_escaped() の呼び出しが発生します。
これに加え、parse_labels() の内部でも _next_unquoted_char() が繰り返し呼ばれるため、1 行あたりのバイトコード実行回数が大幅に増大します。
Issue #1114 では upstream のメンテナがベンチマークでパース性能の 5〜6 倍の劣化を確認したと報告しています。
The small benchmark I created now shows results taking 5-6x as long which is close enough to your report.
前述の status.log のデータをスループットに換算すると、劣化の程度がより明確になります。
$$
Throughput = MetricSamples \div AverageExecutionTime \, (sec)
$$
v7.66(0.21.1): 23,534 / 1.851s ≒ 12,714 metrics/sec
v7.76(0.22.1): 21,446 / 14.302s ≒ 1,500 metrics/sec ← 88% 低下
パッチによる部分的な回復
Issue #1114 を受け Prometheus コミュニティは部分的なパッチをリリースしています。
Datadog Agent では v7.78 で取り込まれているため(v0.22.1 → v0.24.1 に更新)こちらのバージョンにアップグレードすることで、多少の改善が見られました。
v7.66(0.21.1): 23,534 / 1.851s ≒ 12,714 metrics/sec
v7.76(0.22.1): 21,446 / 14.302s ≒ 1,500 metrics/sec ← 88% 低下
v7.78(0.24.1): 22,875 / 7.066s ≒ 3,237 metrics/sec ← 部分回復
3. 特定の環境で顕著になる理由
prometheus-client の回帰は 1 行あたりのパースコストが増大する という問題を抱えています。従って、1 回の check で処理する行数が多いほど影響が大きくなるため、同じ Agent バージョンでも環境によって影響度が大きく異なります。
istio-proxy の集中度
Kubernetes クラスタでは、ノードプールの設計によって 1 ノード上の Pod 数が大きく異なります。APM 用途等で多数のアプリケーション Pod が集中するノードでは、それぞれの Pod が istio-proxy sidecar を持つため、1 Agent あたりのスクレイピング対象インスタンス数が増加します。
今回の環境では、1 ノードに istio-proxy が 11 インスタンス稼働していました。
- インスタンス数:11
- 最大メトリクスサンプル数 / インスタンス:21,446(
status.log実測)- スクレイプ行数 / インスタンス:約 9,000 行(
curl実測)- check interval:15s
- → 1 Agent が 15 秒毎に 最大約 99,000 行 を Python Interpreter でパース
1 インスタンスあたりの実行時間が長いほど check worker の占有時間が積み重なり、CPU が高止まりします。check interval(15 秒)に対して実行時間が十分に短縮できなければ、worker は次の check interval までに処理を完了できず、常時過負荷の状態に陥ることになります。
スクレイプ行数の多さ
今回の環境では datadog-agent:x.xx.x-full イメージを使用しており、Istio Integration の Autodiscovery 設定(auto_conf.yaml)が同梱されていました。Autodiscovery が istio-proxy を検出すると istio check が自動起動し、明示的に無効化しない限りスクレイピングが実行されます。
スクレイピング先の /stats/prometheus(port 15020)には、istio 固有のメトリクス(istio_*)だけでなく、Envoy プロキシが生成するメトリクス(envoy_*)も混在 しています。
以下は実際に curl で取得し、データ行数を計測した結果です。
### envoy メトリクス行
$ kubectl exec -n datadog -c istio-proxy -- curl -s http://localhost:15020/stats/prometheus | grep "^envoy_" | wc -l
### istio メトリクス行
$ kubectl exec -n datadog -c istio-proxy -- curl -s http://localhost:15020/stats/prometheus | grep "^istio_" | wc -l
メトリクス構成の一例(実測):
envoy_*行数:4,752(52.4%)istio_*行数:4,318(47.6%)
計:9,072 行 / インスタンス
MetricSamples は check が取得したメトリクスの数であるのに対し、スクレイプ行数は HTTP レスポンスに含まれるデータ行の総数になります。
istio check はデフォルト設定のままでは、スクレイプしたすべての行をパースします。1 インスタンスあたり約 9,000 行で、それが 11 インスタンス分あるため、Agent 1 台あたり約 99,000 行を毎回処理することになります。
パーサが遅くなった状況下では、このスクレイプ行数の多さが CPU 負荷をさらに悪化させる要因になっていました。
4. フィルタリングでは解決しない理由
スクレイプ行数の過半数は業務上不要な envoy_* メトリクスが占めているわけなので、これをフィルタで除外すれば解決しそうに思えます。実際に、DD_IGNORE_AUTOCONF: istio で組み込みの auto_conf を無効化した上で、use_openmetrics: true(OpenMetrics V2)と raw_line_filters を組み合わせたカスタム設定を適用して必要なメトリクスだけをホワイトリスト形式で取り込むようにしてみました。
### datadog-agent.yaml
spec:
override:
nodeAgent:
env:
- name: DD_IGNORE_AUTOCONF
value: "istio"
extraConfd:
configDataMap:
istio.yaml: |-
ad_identifiers:
- proxyv2
- proxyv2-rhel8
instances:
- istio_mesh_endpoint: http://%%host%%:15020/stats/prometheus
use_openmetrics: true
send_histograms_buckets: true
tag_by_endpoint: false
raw_line_filters:
- "^(?!#|istio_requests_total|istio_request_duration_milliseconds|istio_request_bytes|istio_response_bytes|envoy_cluster_upstream_rq_retry|envoy_cluster_circuit_breakers_|envoy_cluster_upstream_rq_pending_overflow)"
しかし、フィルタを適用しても CPU 負荷は十分に下がりませんでした。
原因は raw_line_filters の動作タイミングにあるようで、フィルタはパーサの前段で行数を減らしますが、ホワイトリストで必要なメトリクスだけに絞った場合でも、それらに対応する行が数千行残ります。

| 状態 | MetricSamples | スクレイプ行数(推定) | 実行時間 / インスタンス |
|---|---|---|---|
| フィルタなし | ~21,000 | ~9,000 行 | ~14s |
| ホワイトリストフィルタ | — | ~3,000〜5,000 行 | ~5〜9s |
check interval 15s に対して、フィルタ適用後でもインスタンスあたり 5〜9s の実行時間が残ります。多数のインスタンスが並列に走る環境では check worker を常時占有する状態が継続し、CPU の高止まりは解消されません。
このため、パーサ自体の速度劣化が問題の本質になっており、フィルタの粒度を変えても対処することはほとんどできませんでした。
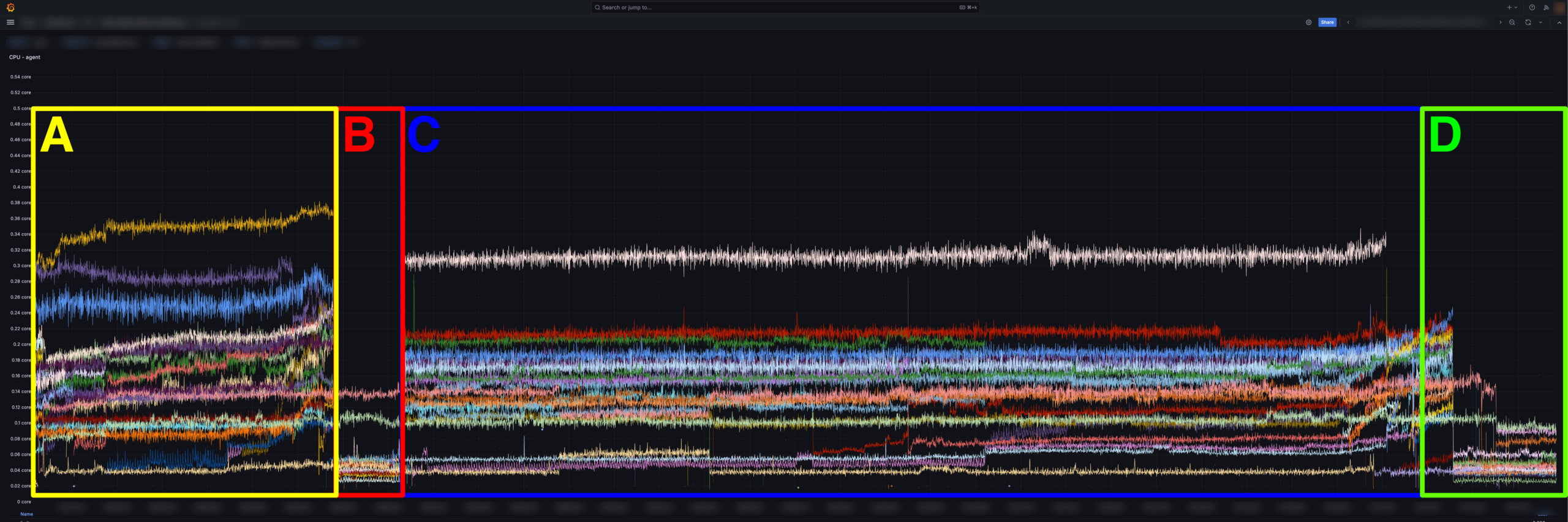
| 区間 | 設定状況 |
|---|---|
| A | v7.78.2 に単純アップデート |
| B | v7.78.2 で全メトリクスを除外 |
| C | v7.78.2 で raw_line_filters を適用 |
| D | v7.66 へ完全ロールバック |
検証結果から、区間 A と C でほとんど変化がないことが分かります。
5. コミュニティの現状認識
prometheus-client(upstream)
Issue #1114 では複数のユーザから v0.22.1 で CPU 劣化が見られたと報告されています。メンテナもベンチマークで 5〜6 倍の劣化を確認しており、PR #1117 で部分的な修正が行われました。
ただし、メンテナ自身が修正は改善にはなるが、元のパフォーマンスには戻らないとコメントしている通り、文字単位処理のアーキテクチャは維持されており根本解決には至っていません。
2026 年 5 月現在でも Issue はオープンのままです。
I created a first batch of optimizations that according to the benchmark should help, but won’t be back to original performance yet: #1117.
Datadog integrations-core
Datadog は prometheus-client の問題を把握しており、Agent v7.78 で v0.24.1 への更新を行ったが、現状、部分的な回復に留まるとしています。フィルタリングによって一定の改善が見られる可能性はありますが、根本的な修正は依然として upstream の進捗に依存している状態です。
また、Datadog サポートケースで直接確認したところ、prometheus-client を別のパーサに置き換えるといった動きも現時点では無いようです。
結論
この問題は現在も進行中で、コミュニティ全体として根本解決策が確立されていない状態にあります。istio-proxy が多数稼働する大規模な本番環境では特に影響が大きく、外部の修正を待つだけでなく自前での対策が必要な状況です。
現在、運用しているサービスでは istio / Envoy メトリクスの収集は必須ではないため、DD_IGNORE_AUTOCONF で istio check を完全に無効化することで CPU を正常水準に抑制しています。
env:
- name: DD_IGNORE_AUTOCONF
value: "istio"
これにより Autodiscovery による istio check の自動設定が無効化され、istio-proxy へのスクレイピング自体が停止します。
今後、これらのメトリクスの取り込みが必要になった場合は、Datadog Agent に組み込まれた OTel Collector(DDOT) の prometheusreceiver から istio-proxy の /stats/prometheus を直接スクレイプする方法を検討しています。この方法では、Go 実装の Prometheus スクレイパを使うため、今回問題になった Python ベースの prometheus-client パーサの問題を回避できるとみています。
6. おわりに
本記事では、Datadog Agent のアップグレードで CPU 負荷が急増する問題について、flare を使った分析と原因の調査をまとめてみました。分析の結果から Agent が内部で使用している prometheus-client ライブラリのパーサ回帰が原因であることが分かりましたが、2026 年 5 月時点で upstream の Issue はオープンのままで、正式な対処方法はまだ確立されていないようです。
今後 istio / Envoy メトリクスの取り込みが必要になる場合は、DDOT の prometheusreceiver を使う方式を検討してみると良さそうです。
同様の事象で頭を抱えている方に向けて、何かの参考になれば幸いです。