
はじめに
アニメ Tech STUDIO ソフトウェアエンジニアの新です。
この記事では、コーディングエージェントの実行履歴から Human-in-the-Loop(人間の確認・介入)の頻度・内容を計測し、確認・介入のポイントを見直す仕組みを紹介します。
背景と課題
コーディングエージェントに任せられる範囲は、急速に広がっています。任せるほど開発は速くなりますが、自律性が上がるほど、危険な操作や意図しない実行のリスクも増えていきます。「任せること」と「安全に保つこと」は、トレードオフの関係にあります。
このトレードオフを調整するのが Human-in-the-Loop です。確認のポイントが多すぎれば、エージェントは些細な操作のたびに止まり、開発のスピードが落ちます。少なすぎれば、本来止めるべき操作が誰の確認も通らずに実行され、事故につながります。適切な塩梅は、その両極端のあいだにあります。
問題は、エージェントの Human-in-the-Loop が適切な頻度・タイミングになっているか——強すぎないか、逆に緩すぎないか——を確かめる手段がないことです。
仕組みの全体像
過去の実行履歴から Human-in-the-Loop を分析するスキルを作りました。処理は 2 段階に分かれています。
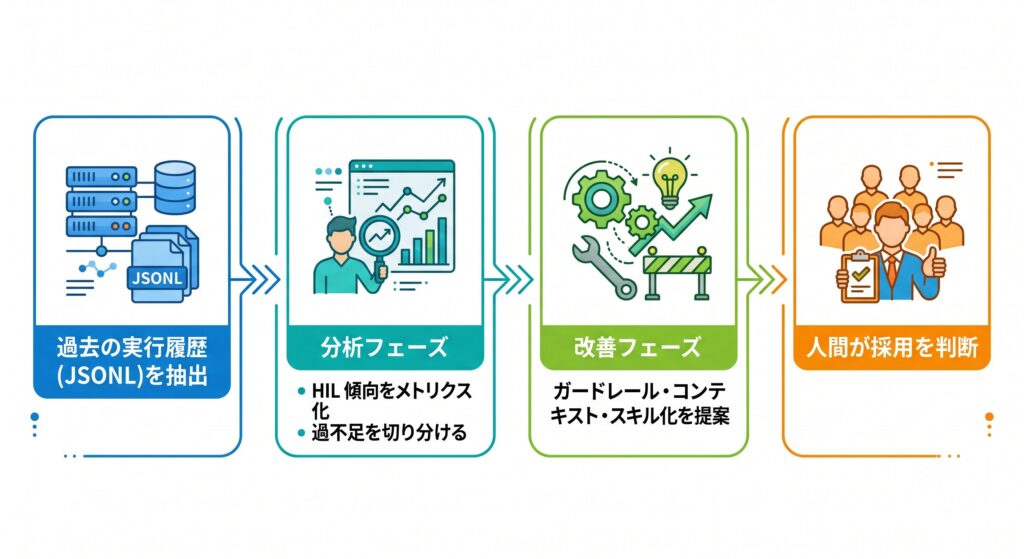
まず分析フェーズで、実行履歴をたどって人間の確認・介入をメトリクスにまとめ、「必要なのに確認していない」「不要なのに確認している」といった過不足を切り分けます。
次に改善フェーズで、その診断を現状の設定と突き合わせ、ガードレール・コンテキスト・スキル化といった観点で具体的な改善案を出します。採用するかどうかは人間が判断します。
スキル
作ったスキルは GitHub で公開しています。
MasatoraAtarashi/hitl-harness-improver – GitHub
インストール
プラグインとして導入できます。
/plugin marketplace add MasatoraAtarashi/hitl-harness-improver
/plugin install hitl-harness-improver@masatora-marketplace使い方
集計したい期間を渡して実行します。
/hitl-harness-improver # 過去 7 日
/hitl-harness-improver 30 # 過去 30 日
/hitl-harness-improver all # 全期間reports/ に診断レポートが Markdown で書き出されます。
全文の例は こちらのサンプルレポート(examples/sample-report.md)にあります。
分析フェーズ:確認・介入を測る
過去の実行履歴(Claude Code のトランスクリプト JSONL)から、エージェントが確認を求めた場面・人間が途中で止めた場面・やり直させた場面を拾い、次の 13 のメトリクスにまとめます(定義はこちらの記事を参考にさせていただきました)。
値は自分の過去 90 セッションの実測値です。機械的に数えられるものは実測、判断が要るものは LLM が見積もります。
算出用プロンプト
メトリクス算出 + 4 分割分析(LLM)
(a) メトリクス表: Qiita 一覧のうち transcript で出せるものを、メトリクス / 説明 / 値 / 算出 / 根拠・備考 の列で全部埋める。
- 単位を揃える: 割合は %(0.69 でなく 69%)。数えられるもの(必要性率 / 技術的回避可能率 / Override / 分散度)は数値、判断が要るものだけ 高/中/低。
- 長い根拠は「根拠・備考」列へ(値セルに詰めない)。
- 介入は 2 種を分けて扱う: ツール停止(本来確認すべきの強シグナル)と ターン中断(casual 含む弱)。③ の根拠はツール停止側だけ使う。
- 実測 = 履歴から数えた数値。LLM 推測 = 確認・介入・是正のサンプルから見積もり、根拠を添える。
- 載せない: 人間の工数・損失額・後工程結果が要るもの。
(b) 4 分割分析(診断の本体): 観測した介在と自律実行を、いいやつ 2・ダメなやつ 2 に振り分ける。各見出しに具体例 + LLM の判断。
1. 適切に人間が介在した場所(agent が妥当に聞いた / 人間が止めて正解)
2. 不必要に人間が介在した場所(確認過多。本来自動化できた)
3. すべきだったのに素通りで実行された場所(ツール停止がその証拠。危険)
4. 適切に自律できた場所(介在不要で正しく自走。自律稼働率で裏付け)
固定ルールで決め打ちしない。何を止めたか・是正の発言を LLM が文脈判断する(read 系の停止は危険でなく確認過多寄り、のような判断も LLM)。| メトリクス | 何を測るか | 算出 | 自分で試したときの値 |
|---|---|---|---|
| 介在回数 | 人間の介在を要した回数(自発確認 + ツール停止) | 実測 | 106(自発確認 82 / ツール停止 24) |
| ターン中断 | 人間が生成を途中で止めた回数 | 実測 | 81(参考・casual な割り込み含む) |
| 必要性率 | 発生した介在のうち、本当に必要だった割合 | LLM 推測 | 約 65% |
| 技術的回避可能率 | 設計やモデルの改善で消せたはずの介在の割合 | LLM 推測 | 約 30% |
| 待機時間 | 人間の回答を待ってアイドルした時間 | 実測 | 中央値 74s / 最大 50 分 16 秒 |
| 割り込み分散度 | 介入が人間の集中作業をどれだけ分断したか | 実測 | 28 セッション / 平均 3.8 件 |
| コンテキスト十分性 | 提示された情報だけで人間が判断できたか | LLM 推測 | 中 |
| 判断覆し率(Override) | 人間が提案を修正・却下した割合 | LLM 推測 | 約 35% |
| リスク加重価値 | 介入対象の影響度で重み付けした重要度 | LLM 推測 | 中 |
| 自律稼働率 | 介入なく最後まで完走したセッションの割合 | 実測 | 69.6%(90 中 62) |
| 信頼キャリブレーション | 自信がない場面で確認できているかの精度 | LLM 推測 | 中 |
| カスケード率 | 1 つの確認が追加の確認を誘発した割合 | LLM 推測 | 低 |
| 粒度ミスマッチ率 | 「もっと早く聞いてほしかった」などと言われた割合 | LLM 推測 | 中 |
メトリクスをもとに、観測した介在を 4 つに切り分けます。
問題になるのは、不要なのに確認している(過剰)と、必要なのに確認していない(リスク)の 2 つです。自分の場合は次のように出ました。
1. 適切に人間が介在した場面
- 自発確認 82 件の多くは妥当。「ブランチ名」「配置場所」「対象 PR」など、人間にしか決められない分岐で止まれている。
- 自発確認(82)がツール停止(24)を上回る=「止められる前に自分から聞く」側に寄っている。
2. 過剰な介在(確認過多)
- 同じ方針の確認を複数のセッションで繰り返している。一度決めておけば、毎回聞かなくてよいものが含まれる。
- 人間の返答が遅れて不要にエージェントの待機時間が発生している(待機時間の最大 50 分)。
3. 介在すべきだったのに素通りで実行された場面(リスク)
gh api -X DELETEによる GitHub コメントの削除が、&&でつないだ複合コマンドの後半に紛れて、確認なしで実行されていた。前半のコマンドを承認すると、後半の破壊的な操作まで一緒に通ってしまう。
4. 適切に自律できた場面
- 自律稼働率 69.6%(90 セッション中 62 は介入ゼロで完走)。大半の読み取り・編集・テスト実行は問題なく自走できている。
改善フェーズ:ハーネスの改善を提案する
分析で見えた過不足を、現状の ~/.claude/settings.json や CLAUDE.md と突き合わせ、次の 3 方向で改善案を出します。設定の自動編集はせず、提案までにとどめます。
- ガードレール(
permissions):確認を減らす/増やす - コンテキスト(
CLAUDE.md):足りない前提を補う - スキル化:繰り返す判断を手順としてまとめる
提案例
自分のログから出た提案です(既に設定済みのものは除く)。
| 対象 | 種別 | 根拠 | 現状 | 採用判断 |
|---|---|---|---|---|
gh api の DELETE など破壊的メソッド |
ask | コメント削除が複合コマンドに紛れて実行された | 未登録 | 追加 |
Bash(grep*) |
allow | 頻出・read-only・介入されても無害 | 未登録 | 追加 |
Bash(git add -A*) / Bash(git add .*) |
ask | 広域 add を止められた実績 | 未登録 | 追加 |
| 「破壊的操作は複合コマンドに混ぜず単独で実行」 | CLAUDE.md |
DELETE が複合コマンドで通った | 未記載 | 追記 |
| 「検証は本番相当の確認まで計画に含める」 | CLAUDE.md |
検証をローカルで止める傾向 | 未記載 | 追記 |
ハーネス改善提案用のプロンプト
ハーネス改善提案(診断 × 現状設定)
診断と現状設定を突き合わせ、改善提案を書く。既に設定済みのものは再提案しない(「既に deny 済み」と明記)。
- permissions.allow 追加: 確認過多 / 止められた read 系のうち、allow に未登録で安全なもの(例: grep gh api)。既に allow 済みは除外。
- permissions.deny / ask 追加: 危険な素通り。既に deny 済み(git push --force 等)なら「設定済み」と書き、未カバーのものだけ提案。「毎回は嫌だがたまに止めたい」は ask(例: 広域 git add)。
- Stop hook: deny で拾いにくい操作の事後検知(必要時のみ)。
- CLAUDE.md / 初期指示: 繰り返す是正(スコープの先走り / 前提の取り違え 等)を最初から防ぐ追記。
各提案に「対象」「根拠(診断のどの数値/事例から)」「現状(既設定か否か)」「採用判断のポイント」を付ける。自動編集はしない。今後の展望
AI Gateway(LiteLLM など)にチームの実行履歴を集約すれば、メンバーを横断して確認・介入の傾向を把握できます。個人単位ではなくチーム共通のハーネス(CLAUDE.md や permissions)の改善に活かせるので、ここまで広げていきたいと考えています。
おわりに
ハーネスが妥当かどうかは、設定ファイルを見るだけでは分からない部分もあります。実際のコーディングエージェントの振る舞い——人間が介入した記録——を測ることで、どこを締め、どこを緩めるかが見えてきます。
同じように線引きに悩んでいる方の参考になれば幸いです。
参考リンク
- Human-in-the-Loop 定量評価メトリクス(cvusk)
- Human-in-the-Loop の定量評価メトリクスの定義をそのまま参考にさせていただきました
- tokoroten/prompt-review
- スクリプト・スキルの構成などの参考にさせていただきました
- Human-in-the-loop(LangChain 公式ドキュメント)