
はじめに
ABEMA の Data Platform チームに所属している河野です。
Data Platform ではABEMAの行動ログやマスターデータなど多岐にわたるデータを管理しています。
ABEMAは今年で10周年を迎え、日々多くのユーザー様にご利用いただいています。
そのおかげもあり、ログの送信量は1日平均15億レコードに及びます。
長きにわたり愛用されているABEMAですが、それと同様にデータ基盤にも同じ長さの歴史があります。
これまで多くのプロジェクトが試行され、そのたびに新しいデータが作成されてきましたが、それらのデータが今もテーブルとして残り続けています。
そこで今回は、Data Lineage APIとaudit logを利用し、ABEMAの大規模データ基盤におけるテーブル廃止プロセスを運用する方法を紹介します。
TL;DR
- 課題:10年運用の約1万テーブル規模の BigQuery で、使われていないテーブルが特定できず棚卸しが進まなかった
- 打ち手:Data Lineage API で「リーフノード(下流のないテーブル)」を抽出し、audit log のクエリ実績と突き合わせて未使用テーブルを検出
- 仕組み:Airflow で月1回バッチ実行し、候補を Slack に通知して廃止判断につなげる
対象読者
- BigQueryを利用している人
- 分析基盤の大量のテーブルを掃除したい人
- データ基盤管理者
なぜ未使用テーブル監視が必要だったのか
行動ログの種類が増え、維持コストが膨らむ
ABEMAでは行動ログの種類が約50種類ほどあります。
行動ログの種類は多ければ多いほど分析の幅が広がりますが、その分クライアントエンジニアやQAエンジニアの実装、テストのコストが高まるという問題がありました。
新しい機能を開発するたびに、全てのログが正しく送信されているか確かめる必要があり、そのために労力をかけています。
しかし、その大半は使われていない
ここで問題なのが、行動ログの大半はもう既に使用されていないということです。
新規機能の開発や、新しい分析、検証のためにログが作成されますが、それらのプロジェクトが終わった後に継続的に分析され続けているログはほとんどありません。
そのため、クライアントチームが送ってくれているログが、本当は分析に利用されていないから送らなくても問題にならない、という問題を抱えています。
かといって「利用していない」と言い切れる人はいない
それなら、利用していない行動ログを削除すればいいと思ってしまいますが、ABEMAには約600名の社員が在籍しており、もう利用していないと思われるデータを、実は誰かがまだ利用しているということがあります。
社員全員にヒアリングすることは可能ですが、誤って廃止したときにどのようなビジネス影響があるか不明なため、リスクを考慮し確実に廃止できる方法を選択することにしました。
そこで、使っていないテーブルから逆算する
ABEMAのデータウェアハウスでは、行動ログデータは1つのデータソースとなるテーブルに集約されています。
そのテーブルから行動ログ別のテーブルに分解し、それぞれのテーブルを加工して分析用のテーブルを作成しています。
分析用のテーブルを廃止するための確実な方法を考えたとき、BigQueryの利用していないテーブル(以下、未利用テーブル)を洗い出していくことで、最終的に行動ログ別のテーブルまで削除でき、最後のこのテーブルの利用者も0だったときに行動ログ自体を廃止できると考えました。
リーフノードから刈る
より安全に未利用テーブルを廃止するために、未利用テーブルの定義を、「 audit log 上での利用回数が0」「リネージの最も端のリーフノードである」としました。
リーフノードのテーブルと定義した理由は、下流の依存関係がなくコンソール、もしくは BI ツールによる getData API での取得の2種類でしかデータ利用履歴が残らないためです。これらの取得方法はすべて audit log 上で取得可能となっています。
未利用テーブルの廃止において最も重要なのは、安全にテーブルを参照できなくさせることです。
全てのテーブルに対して一律に使用状況を確認し、使用回数が0のテーブルでも、その先のテーブルで利用されている場合があるため一概に削除できるとは言えないと考えました。
そこで、枝葉から刈っていくイメージで徐々にテーブルを廃止していき、長いスパンで見て未利用テーブルがなくなっていくように設計しました。
Data Lineage API の役割
Data Lineage APIは、テーブルのリネージ関係を探索し、リーフノードにおけるテーブルを発見するのに使用しています。
リネージ関係を取得するときのルートのテーブルには、生のログデータを保存しているテーブルを指定しています。
幸い、ABEMAの行動ログのデータは最初の1つのテーブルから全てスタートしていたため、ここの選定が楽に済みました。
audit log の役割
audit log はクエリの利用回数を調べるのに利用しています。
audit log にした理由は BI ツールからの参照まで知ることができるためです。
BigQuery には JOBS ビュービューを利用して実行されたクエリを分析することができますが、こちらの場合は Tableau などのSaaS製品が実行したAPIの履歴までは取ることができませんでした。
このときの、利用回数を調べる遡及期間は1か月に設定しています。
この1か月という数字に大きな意味はありませんが、なるべく長く取ることで廃止するときの安全性が高くなります。
システム構成
本システムは Managed Service for Apache Airflow (旧 Cloud Composer)上の月次バッチとして動作します。
行動ログのルートテーブルを起点に Data Lineage API で下流グラフを辿ってリーフテーブルを特定し、audit log から集計した直近 1 ヶ月の利用履歴と BigQuery 上で突き合わせ、利用回数が 0 のテーブル(未利用テーブル)を Slack に通知します。
アーキテクチャ全体図
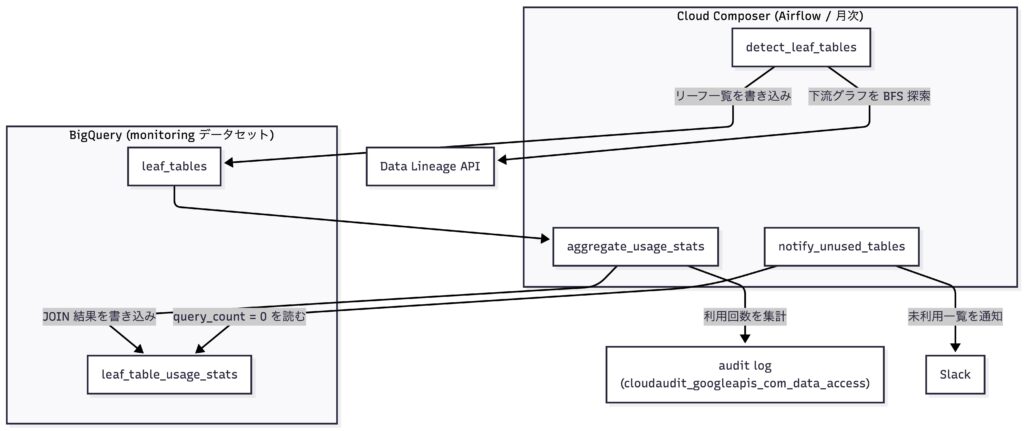
全体は「リーフ検出 → 利用回数の集計 → Slack 通知」という月次のパイプラインですが、本記事では技術的な肝である次の 2 点に絞って解説します。
- リーフテーブルの検出ロジック ── Data Lineage API でどう「末端のテーブル」を見つけるか
- audit log のクエリ方法 ── 「実際に使われたか」をどう測るか
リーフテーブルの検出ロジック
探索の起点は行動ログの生テーブル `root_table` です。
このテーブルから派生する系譜だけを対象に、下流に実テーブルを持たないノード=リーフテーブルを特定します。
Data Lineage API はテーブルを bigquery:project.dataset.table という FQN(完全修飾名)で識別します。まずは FQN の組み立てとパースを行うヘルパーです。
_BQ_FQN_PREFIX = "bigquery:"
@dataclass
class TableRef:
"""BigQuery テーブルの識別子。"""
project: str
dataset: str
table: str
def _build_root_fqn(env: str) -> str:
"""環境に応じたルートテーブルの Data Lineage API 用 FQN を構築する。"""
prefix = env_prefix(env, "_")
return f"{_BQ_FQN_PREFIX}abema.abema_sample.root_table"
def _parse_fqn(fqn: str) -> TableRef | None:
"""FQN 文字列から project/dataset/table を抽出する。非 BigQuery アセットは None。"""
if not fqn.startswith(_BQ_FQN_PREFIX):
return None
parts = fqn[len(_BQ_FQN_PREFIX) :].split(".")
if len(parts) != 3:
return None
return TableRef(project=parts[0], dataset=parts[1], table=parts[2])
以下は探索の本体です。
LineageClient.search_links に source(入力側)としてテーブルを渡すと、そのテーブルを起点とする下流リンクが返ります。
これを幅優先探索(BFS)で辿り、テーブルの下流を 1 つも持たないノードをリーフと判定します。
判定時に下流から除外するもの(=そのノードを「中間ノード」に格上げしない対象)は次のとおりです。
- ビュー(VIEW):ビューしか下流に持たないテーブルはリーフ扱いにしており、これは audit log 上では VIEW ではなく参照元のテーブルが履歴として残るためです
- 一時データセット(_ 始まり):クエリ実行時の一時的な中間生成物
- 削除済み(NotFound)/アクセス拒否(Forbidden):実体を確認できないテーブル
def _traverse_downstream(
lineage_client: LineageClient,
bq_client: bigquery.Client,
root_fqn: str,
) -> list[TableRef]:
"""BFS でルートテーブルから下流グラフを探索し、リーフテーブル情報を返す。"""
visited: set[str] = set()
queue: deque[str] = deque([root_fqn])
visited.add(root_fqn)
leaves: list[TableRef] = []
while queue:
current_fqn = queue.popleft()
current_ref = _parse_fqn(current_fqn)
if current_ref is None:
continue
# current_fqn を入力(source)とする下流リンクを検索
request = SearchLinksRequest(
parent=f"projects/{current_ref.project}/locations/us",
source=EntityReference(fully_qualified_name=current_fqn),
)
has_bq_downstream = False
for link in lineage_client.search_links(request=request):
target_fqn = link.target.fully_qualified_name
target_ref = _parse_fqn(target_fqn)
if target_ref is None:
continue
if target_fqn in visited:
has_bq_downstream = True
continue
table_fqn = f"{target_ref.project}.{target_ref.dataset}.{target_ref.table}"
if target_ref.dataset.startswith("_"):
continue # 一時データセット
try:
tbl = bq_client.get_table(table_fqn)
except NotFound:
continue # 削除済み
except Forbidden:
continue # アクセス拒否
if tbl.table_type == "VIEW":
continue # ビュー
has_bq_downstream = True
visited.add(target_fqn)
queue.append(target_fqn)
# 下流に実テーブルが無ければリーフ(ルート自身は除く)
if not has_bq_downstream and current_fqn != root_fqn:
leaves.append(
TableRef(current_ref.project, current_ref.dataset, current_ref.table)
)
return leaves
audit log のクエリ方法
ここでは BigQuery にエクスポート済みの audit log テーブル cloudaudit_googleapis_com_data_access を参照します。
このテーブルは事前に作成しているもので、 https://docs.cloud.google.com/architecture/security-log-analytics?hl=ja を参考に作成することができます。
クエリのポイントは次のとおりです。
- 「利用」の定義:bigquery.tables.getData 権限を伴い、かつ Query / InsertJob のジョブだけを利用とみなす(メタデータ参照などは除外)
- ノイズ除外:セキュリティスキャナ等の自動アクセスは、サービスアカウントで除外しないと「利用あり」と誤判定されてしまう
-- リーフテーブルの利用統計を集計
-- monitoring.leaf_tables と audit log を結合し、各リーフテーブルのクエリ利用回数を取得
SELECT
REGEXP_EXTRACT(protopayload_auditlog.resourcename, r'projects/([^/]+)') AS project,
REGEXP_EXTRACT(protopayload_auditlog.resourcename, r'datasets/([^/]+)') AS dataset,
REGEXP_EXTRACT(protopayload_auditlog.resourcename, r'tables/([^/]+)') AS table_name,
COUNT(*) AS query_count
FROM `cloudaudit_googleapis_com_data_access`
, UNNEST(protopayload_auditlog.authorizationinfo) AS authorizationinfo
WHERE
timestamp >= TIMESTAMP(DATE '${dt}')
AND timestamp < TIMESTAMP(DATE_ADD(DATE '${dt}', INTERVAL 1 MONTH))
AND protopayload_auditlog.resourcename LIKE 'projects/%/datasets/%/tables/%'
AND authorizationinfo.permission = "bigquery.tables.getData"
AND protopayload_auditlog.methodname IN (
"google.cloud.bigquery.v2.JobService.InsertJob",
"google.cloud.bigquery.v2.JobService.Query"
)
AND protopayload_auditlog.authenticationinfo.principalemail NOT IN (
"(スキャナ用サービスアカウントのメールアドレス)" -- 自動スキャンを除外
)
GROUP BY
1, 2, 3
運用してみた結果
通知が来たタイミングでミーティングを行い、廃止できるかできないか、廃止する場合はどのようなコミュニケーション設計が必要かなどを話し合ったうえで、未利用テーブルへの対応を手動で行っています。
この監視システムにより数十個の未利用テーブルが検知され、廃止可能なテーブルもいくつか検出することができました。
この10年間で手を付けていなかったテーブルの廃止プロセスの一歩を踏み出したことで、複雑化したデータ基盤をシンプルにできるという手触りの感覚が得られました。
また、通知された未利用テーブルもメンバーの肌感覚と合致しており、リーフノードのテーブルから廃止していくというプロセス自体は間違っていないと感じています。
今後の展望
今後はこのシステムを利用しながら徐々にテーブル数を減らし、分析に本当に必要なテーブルだけが残った状態を作りたいと思っています。
新しく入ってきた分析者がジョインした初日にすぐに仕事に取りかかれる、シンプルでわかりやすいデータ基盤を提供するために、引き続き廃止運動は続けていこうと思います。