
ABEMAデータテクノロジーズの作花と山村です。今回は、Google Cloudで提供されているワークフロー管理サービスの一つであるCloud Composerを用いて機械学習のワークフローを管理した実例について紹介します。
Cloud Composerとは
Cloud Composer は、ワークフローの作成、スケジューリング、モニタリング、管理を支援する、マネージド Apache Airflow サービスです。 出典元:Google Cloud 公式ドキュメント
Cloud Composerを用いることで、GCP内外のサービスと連携したApache Airflowの環境を容易に構築することができます。また、Airflowで提供されているウェブブラウザ環境へGoogleアカウントで認証をすることができます。そのため、独自でアクセス制限をする必要がなく開発コストを削減できるという利点があります。
Cloud Composerは以下のようなアーキテクチャとなっています (図1)。
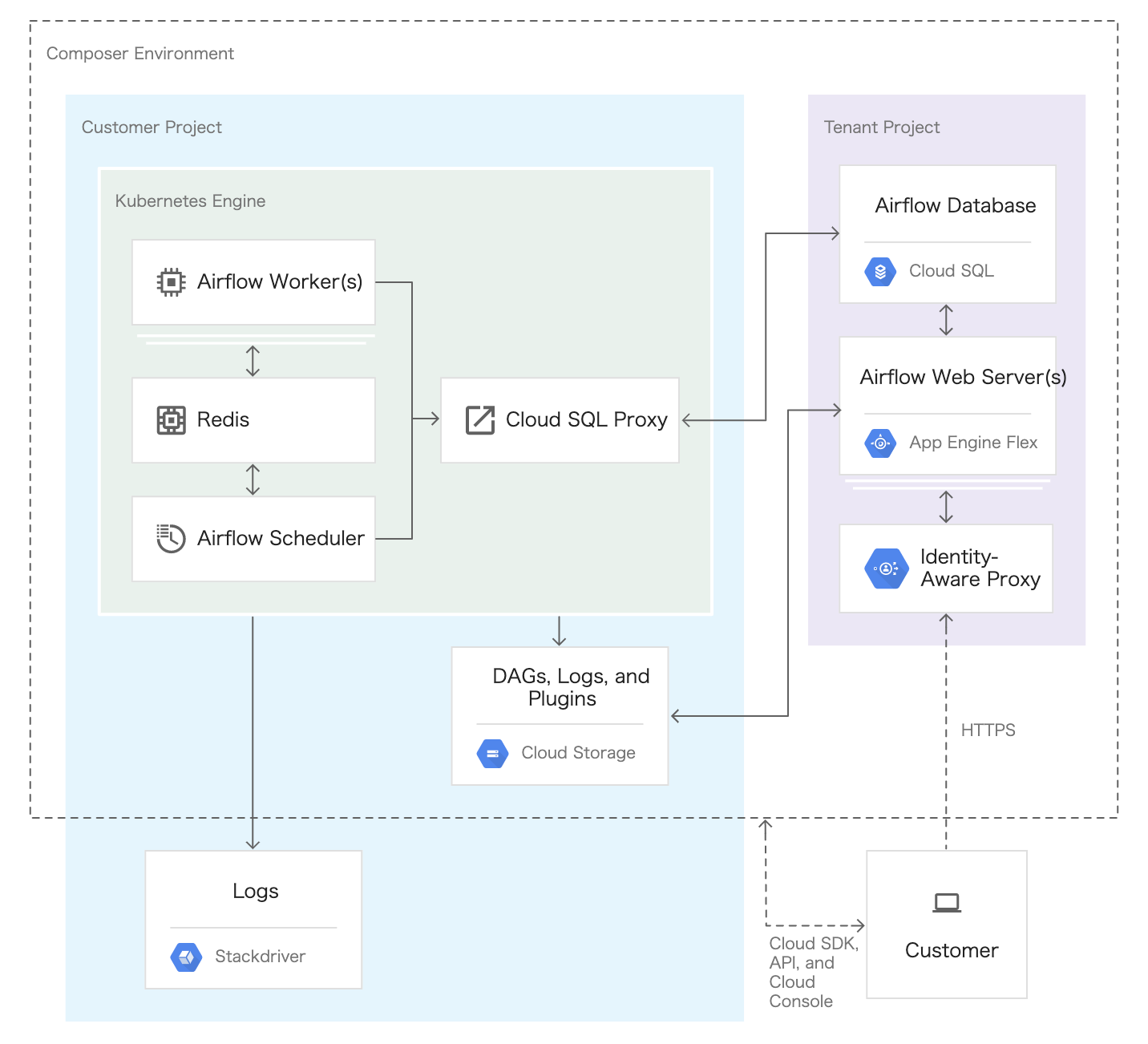 図1. Cloud Composer環境のリソース (公式ドキュメントから引用)
図1. Cloud Composer環境のリソース (公式ドキュメントから引用)
図内左側の水色で囲まれている部分が自分たちのプロジェクトで管理する部分で、右側の紫色の部分がGoogle側で管理されているプロジェクトとなっています。そのため、我々からは紫色で囲われたリソースに関しては見ることができません。
Airflowのスケジューラやワーカーなどは、Google Kubernetes Engineにデプロイされます。ワークフローやタスクの設定は、Google Cloud Storage (GCS)を利用して行います。環境を作成するとGCS内に必要なバケットが自動で作成されます。作成されたバケットは、Composerのコンソール画面から対象のワークフローのDAGリンクをクリックすることで確認することができます。ワークフローを設定する上で、主に利用するのはdagsとlogsになります。
- dags: DAGファイルと呼ばれるワークフローで実行する各タスクとタスク間の依存関係を定義したpythonファイルを格納します。
- logs: ワーカーの各種ログファイルが格納されます。
公式ドキュメントには、アーキテクチャに関する詳細やチュートリアルを用いた導入方法の例などが紹介されているので、興味のある方は是非見てみてください。
導入背景
ABEMAデータテクノロジーズで、ワークフローエンジンとしてCloud Composerを導入した背景には大きく以下の3点があります。
- BigQueryのスケジュールクエリでは対応しきれなくなった点
- ワークフローの設定を外部で管理することができる点
- マネージドサービスを用いることで開発コストを下げることができる点
1つ目は、クエリの実行順序に依存関係がある場合についてです。クエリAを実行した後にクエリBを実行する場合に、スケジュールクエリでは時間で実行順序を制御することになります。しかし、実際にはクエリAの集計結果にクエリBが依存するような場合もあります。このような場合には、各種実行結果のステータスが必要となり、スケジュールクエリでは実現が困難です。加えて、Cloud Composerを用いることでGCPの他のサービスや可視化ツールなどのサードパーティとの連携も容易になります。
2つ目は、ワークフローやDockerイメージなどの設定を外部で管理できる点です。切り出された設定をファイルで管理することで、GitHub上などで変更履歴の確認や、問題発生時の切り戻し、コードレビューが可能になります。結果として、ワークフローの保守がしやすくなります。
3つ目は、インフラやソフトウェアの保守・運用のための開発コストについてです。運用していく中で、GCPやAirflowは日々更新されていきます。ときには、新機能追加などの互換性のない大きなアップデートが行われますが、それらにも対応する必要があります。しかし、データ分析を主とする組織では部署内に多くのエンジニアがいるわけではないので、対応に多くの時間が掛かってしまいます。マネージドサービスを利用することで、新バージョンに対応するための初期開発や各種障害対応などのついてGoogle側に任せることができます。そうすることで、データ組織としては分析やモデルの作成に注力できる環境となります。
実際の活用例
今回は、ABEMAのキャスティングシステムを例にCloud Composerを用いて機械学習のワークフローを管理する方法について紹介します。キャスティングシステムとはABEMAのキャスト選びをデータを用いて支援するシステムとなっています。システムの構成は一般的なデータ処理フローであるExtract/Transform/Load (ETL)に加え、機械学習を用いた予測、SlackやTableauへの結果の通知となっています (図2)。このワークフローは週次で実行され、翌週に結果が通知されるようにスケジュールが組まれています。
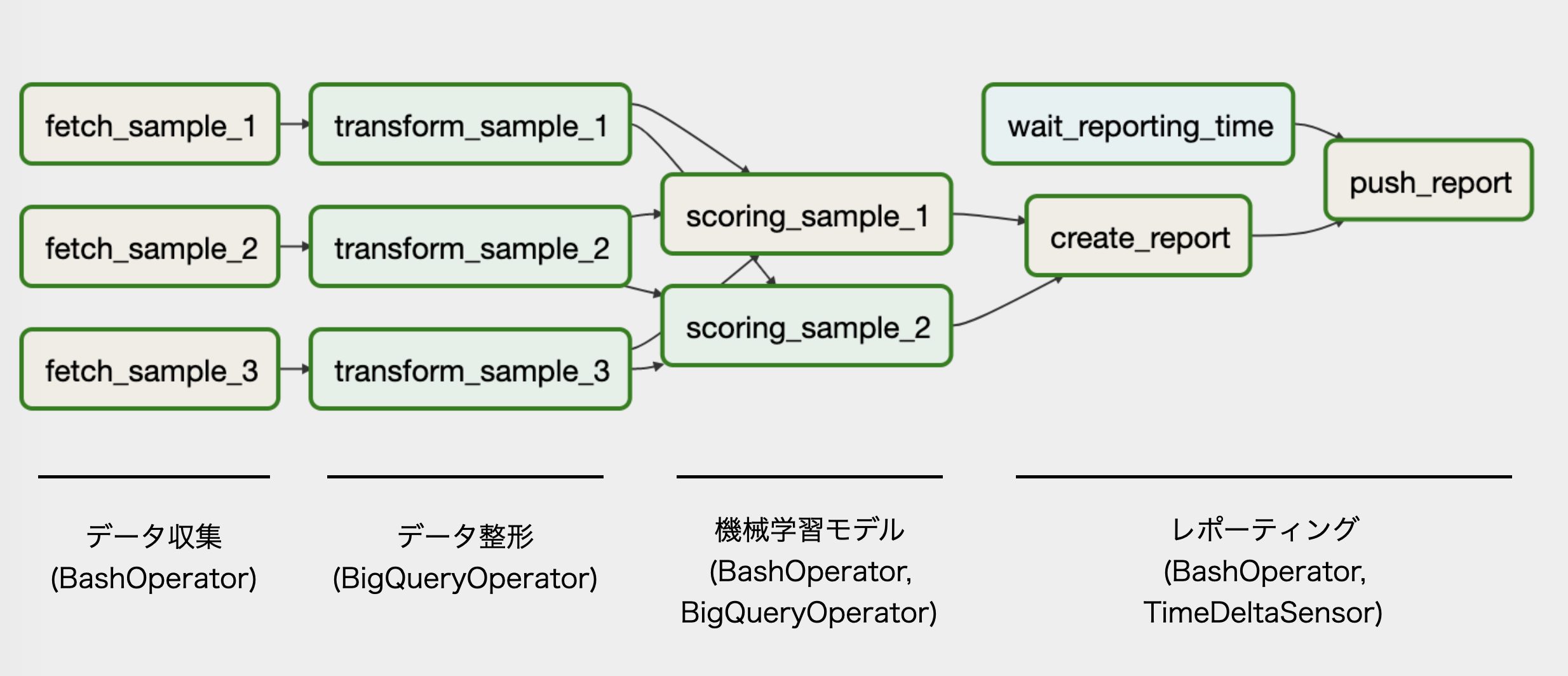 図2. サンプルのワークフローを表現したDAG
図2. サンプルのワークフローを表現したDAG
ワークフローの定義
ここでは、キャスティングシステムを例にサンプルコードを用いてワークフローを定義する手順を紹介します。ワークフローは、依存関係を含むタスクを組み合わせることで定義されます。各タスクは、必要なデータを取得してくるタスクや機械学習モデルで予測するタスクのように一つ一つの処理で表現されます。ワークフロー内では、タスク単位で失敗時のリトライ処理などを行うため各タスクは冪等になるように定義することが理想的です。Cloud Composerでは、ワークフローを表現するDAG (Directed acyclic graph)をpythonで記述して管理します。作成したファイルは、Cloud Composer環境を作成した際に自動生成されたGCSバケットのdags配下に格納することでAirflow側にDAGが自動で読み込まれます。
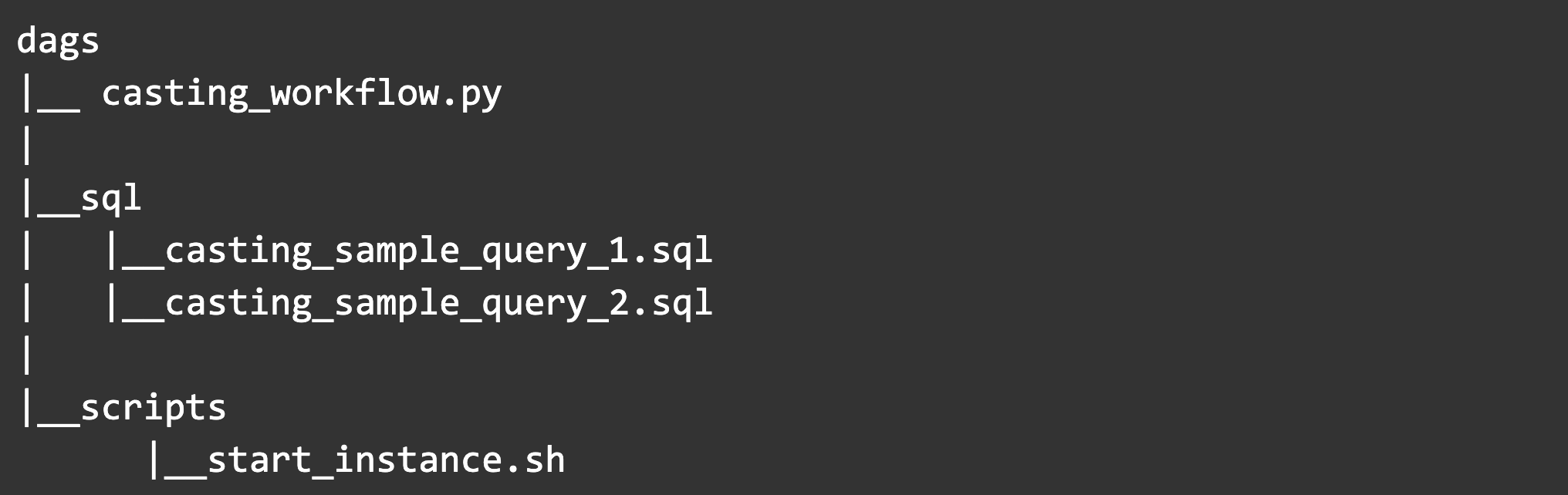
今回の例では、dags配下を以下のような構造で管理します。
はじめに、DAGを定義する上で重要な時間の扱いについて説明します。主に以下の3つの変数を設定することでDAGのスケジュールを制御します。
- start_date: DAGの開始日時。backfillを行う場合は、この日付まで遡ります。
- end_date: DAGの終了日時
- schedule_interval: DAG全体の実行間隔
日時のタイムゾーンはデフォルトではUTCとなっているため、必要に応じてAsia/Tokyoに変更する必要があります。ここで、DAGが最初に実行される時刻はstart_dateではなく、start_date + schedule_intervalとなる点に注意が必要です。DAGが実行された時刻はexecution_dateという変数に格納されており、スクリプト内で利用したい場合は{{ ds }}で参照できます。execution_dateは、リトライをしても変更されない値となっています。
スクリプト内で利用できるDAGの変数やマクロは、他にも複数用意されているので詳しくは公式ドキュメントを確認してください。
タスクの定義
次に、実際にDAGを定義しているcasting_workflow.pyを参照しながら説明します。まずは、DAG自体の設定を見ていきます。
import pendulum
from airflow import models
from airflow.contrib.operators import bigquery_operator
from airflow.operators import bash_operator
from airflow.sensors import time_delta_sensor
from datetime import datetime, timedelta
default_args = {
'email': os.getenv('SLACK_EMAIL'),
'email_on_failure': True,
'email_on_retry': False,
'owner': 'owner_name',
'params': {
'sample_table': 'project_name.casting_dataset.sample1',},
'retries': 3,
'retry_delay': timedelta(minutes=5),
'use_legacy_sql': False,
}
with models.DAG(
dag_id='casting_workflow',
concurrency=5,
default_args=default_args,
start_date=datetime(2020, 8, 3, 13, 0, 0, tzinfo=pendulum.timezone('Asia/Tokyo')),
schedule_interval=timedelta(weeks=1),
) as dag:
ワークフローを表すDAGは、models.DAGで定義され引数にパラメータを渡すことができます。今回の例では、以下の5つのパラメータを設定しています。
- dag_id: DAGを一意に認識する文字列
- concurrency: DAG内で同時に実行するタスクの最大数
- default_args: タスクのステータスに関する通知設定や失敗時のリトライ数・リトライ間隔、DAGに渡すパラメータなどを設定することができる
- start_date: DAGの開始日
- schedule_interval: DAGを実行する間隔
次にDAGで管理する各タスクについて見ていきます。タスクを定義する際には、Airflowで用意されているOperatorを用います。今回はBashOperatorとBigQueryOperator、TimeDeltaSensorの3つを用いてタスクを定義しますが、他にも様々なOperatorがありますので公式ドキュメントを参考に用件に合うものを用いてください。
各タスクは以下のコードで記述されています。タスクの定義の仕方は全体を通して大きく変わらないので、ここでは各Operatorから一つずつ抜き出して紹介します。
# BashOperatorのタスク例
fetch_sample_1 = bash_operator.BashOperator(
task_id="fetch_sample_1",
bash_command="scripts/start_instance.sh",
params={"instance_name": "casting-sample-instance",
"docker_image": "gcr.io/abematv-sample/sample_image",
"exec_file_path": "sample_dirc/fetch_sample.sh",
"is_test": "false",
"send_gcs": "true",
"check_end_file_path": "gs://abematv-sample/data/fetch1/done_task.txt"},
)
# BigQueryOperatorのタスク例
transform_sample_1 = bigquery_operator.BigQueryOperator(
task_id="transform_sample_1",
sql="sql/casting_sample_query_1.sql",
destination_dataset_table="{{params.sample_table}}",
write_disposition="WRITE_APPEND",
)
# TimeDeltaSensorのタスク例
waiting_sensor = time_delta_sensor.TimeDeltaSensor(
task_id="wait_reporting_time",
delta=timedelta(days=7) # execution_dateが基準時刻となる
)
まずは、BashOperatorから見ていきます。BashOperatorでは、ワークフロー内でタスクを一意に特定するためのtask_id、実行するbashコマンドとパラメータを引数で指定します。今回は実行するbashコマンドが複数行になりタスクを定義するcasting_workflow.pyが煩雑になるため、別ファイルとして切り出しています。切り出したbashファイルは以下のようになっています。bashファイルは、DAGファイルと区別するためにGCSのdags/scripts配下にまとめて管理しました。
set -xe
INSTANCE_NAME="{{ params.instance_name }}-{{ ds }}"
PROJECT="abematv-sample"
ZONE="us-central1-a"
# インスタンス作成
gcloud compute instances create-with-container "${INSTANCE_NAME}" \
--project "${PROJECT}" \
--zone "${ZONE}" \
--machine-type n1-standard-2 \
--container-image "{{ params.docker_image }}" \
--boot-disk-size 100 \
--boot-disk-type pd-standard \
--boot-disk-auto-delete \
--scopes storage-full,bigquery \
--container-command "bash" \
--container-arg="{{ params.exec_file_path }}" \
--container-arg="{{ params.is_test }}" \
--container-arg="{{ params.send_gcs }}"
sleep 3m
# タスクの実行
while true; do
if gsutil -q stat {{ params.check_end_file_path }}; then
echo "Done Process"
# get and remove end status file
gsutil mv {{ params.check_end_file_path }} ./done_task.txt
break
else
sleep 10m
fi
done
# インスタンス削除
gcloud compute instances delete "${INSTANCE_NAME}" \
--project "${PROJECT}" \
--zone "${ZONE}" \
--quiet
# 終了ステータスを通知
if [ `head -n 1 ./done_task.txt` = failure ]; then
echo "task was failure"
exit 1
else
echo "all tasks were success"
exit 0
fi
このbashファイルでは、次のようなことを行っています。まずタスクを実行するためのGCPインスタンスを作成します。インスタンス名は、実行スケジュールと関連性を持たせるために、指定した名前に実行日時 (execution_date)を連結するようにしています。Dockerイメージや実行ファイルのpathなどは、BashOperatorのパラメータで指定しています。そして、exec_file_pathで指定したファイルをコンテナ内で実行します。コンテナ内での処理が終了すると、終了ステータスを記載したファイル (end_check_file_path)をGCSに送信し、ループから抜けます。インスタンス内で実行する処理が終了するとインスタンスは不要なので、プロジェクトから削除します。最終的にend_check_file_pathを読み込み、処理の終了ステータスを確認することでComposer側に終了ステータスを通知します。
次にBigQueryOperatorについて説明します。BigQueryOperatorを用いるとワークフローにBigQueryの操作を組み込むことができます。実行するQueryを記述したSQLファイルは、 GCSのdags/sql配下にまとめて管理しました。BigQueryOperatorの引数としては、以下の4つがよく利用されます。
- task_id: DAG内でタスクを一意に識別するためのID
- sql: 実行するSQL文またはSQLが記述されたファイル
- destination_dataset_table: 結果を格納するテーブル名、今回の例ではDAGのdefault_argsでパラメータとして指定している
- write_desposition: 保存先のテーブルに既にデータが存在する場合のアクションを設定する (WRITE_EMPTY/WRITE_APPEND)
casting_sample_1.sqlでは、前のタスクで取得したデータを機械学習モデルに入力できるように集計し、write_despositionで指定した場所に結果を格納します。また、TableauなどのBIツールで可視化する際に扱いやすいようにデータの整形も行います。
BigQueryでは集計処理以外にも、BigQuery MLを用いることで機械学習モデルの学習・推論を行うことができます。そうすることで、機械学習モデルをSQLで記述することができるためBigQueryOperatorで管理することができます。その場合には、BigQueryからデータの転送を行う必要がなく、BigQuery内の閉じた環境で大規模なリソースを用いて機械学習モデルを実行できるという利点もあります。
最後にTimeDeltaSensorについて説明します。このOperatorは今までとは異なり特定の時間になったことをDAGに知らせるSensorとして働きます。今回は、得られた推定結果を特定の時間以降まで待ってSlackへ通知するということを実現するために利用します。コードの例では、execution_dateを基準として7日間待つというタスクを定義しています。
実行順序の定義
先ほどは、DAGで実行するタスクの定義方法について説明しました。ここからは、タスクをどのような順序で実行するかを定義する方法について説明します。タスクAの後にタスクBを実行するという順序の場合は、タスクA >> タスクBと記述します。実際に利用する場合には、タスクAとタスクCが終わった後にタスクBを実行するといったように複数の依存関係がある場合も発生します。その場合には、[タスクA, タスクC] >> タスクBと記述します。
上記の例に従いキャスティングシステムのタスク実行順序を定義しすると、以下のようになります。
fetch_sample_1 >> transform_sample_1
fetch_sample_2 >> transform_sample_2
fetch_sample_3 >> transform_sample_3
[transform_sample_1, transform_sample_2, transform_sample_3] >> scoring_sample_1
[transform_sample_1, transform_sample_2, transform_sample_3] >> scoring_sample_2
[scoring_sample_1, scoring_sample_2] >> create_report
[create_report, waiting_sensor] >> push_report
Cloud Composerの環境作成時のコンソールから、Airflowのモニタリングページにアクセスすることで、図2のように定義したDAGを視覚的に確認することができます。
DAGファイルの管理
Cloud ComposerではDAGを定義したpythonファイルやタスクで利用するファイル (bash、sql)は、環境に紐付いたGCSの特定のバケットで管理されています。また、今回の場合ではタスクで利用するインスタンス用のDocker imageもGCRで管理されているため、いずれかのファイルを変更するたびに人手で更新するのは手間が掛かるだけでなく、ミスも発生しやすい仕事となります。
私たちの場合は、GitHubとCloud Buildを連携し、特定のブランチからのpushをトリガーとしてGCSにデプロイすることで最新の状態に保つようにしています。 例として、Cloud Buildを用いてDAGファイルを管理するcloudbuild.yamlを紹介します。この例では、masterブランチからpushされた場合のみ”GCS_DEST_URL”配下にあるComposerのDAGファイルや外部ファイルを更新するようにしています。
steps:
- name: 'python:3-slim'
entrypoint: 'bash'
args:
- '-exc'
- |
apt-get update && apt-get install -y --no-install-recommends gcc g++
pip install --no-cache-dir -r requirements.txt
for f in $$(find dags -name \*.py | sort); do
cat "$${f}"
python < "$${f}"
done
- name: 'gcr.io/cloud-builders/gcloud'
entrypoint: 'bash'
args:
- '-exc'
- |
gsutil -m rsync -r -d -n dags "$${GCS_DEST_URL}"
- name: 'gcr.io/cloud-builders/gcloud'
entrypoint: 'bash'
args:
- '-exc'
- |
if [[ $${BRANCH_NAME} != 'master' ]]; then
echo 'skip deploying'
exit
fi
gsutil -m rsync -r -d dags "$${GCS_DEST_URL}"
env:
- 'BRANCH_NAME=$BRANCH_NAME'
options:
env:
- 'GCS_DEST_URL=gs://abematv-sample-workflow/dags'
- 'LANG=C.UTF-8'
おわりに
今回は、キャスティングシステムを例にCloud Composerを用いて機械学習のワークフローを管理した話を紹介しました。他にもBigQueryのマスターテーブルが正しく更新されているかを確認するワークフローなど、GCPのリソースを管理するためにもCloud Composerを利用しています。
今後もABEMAにおけるデータ活用の事例を紹介していきたいと思いますので、よろしくお願いします。