
協業リテールメディアdivの河野です。
2023年に新卒入社し、今年で2年目になります。優しい先輩たちからビシバシと厳しい指導を受け、日々成長を実感しています。
今、我々のチームではAIセグメントという、機械学習を用いて作成されたセグメントをデジタル広告配信で運用しています。セグメントとはマーケティングの文脈である特性を持つユーザーの集団のことをいいます。AIセグメントは商品カテゴリに対する購買予測をし、予測値が高いユーザーを集めたものです。簡単に言うと、「カテゴリを購買しやすそうなユーザー集団」です。もう少し具体的な内容を知りたい方は以下のブログを参照してください。
このAIセグメントは私が機械学習モデルを構築し作成しました。その後PoCを経て、実運用に乗せていきたいというところまではチーム全体の合意が取れていたのですが、実際にどのようにして売り込めばよいかという問題に直面しました。
お客様と実際に会話するのは営業メンバーです。営業メンバーはAIセグメントがどのようにして作られ、どのような特性があるのか知らないため、私が資料作成を担当し、営業メンバーが容易に説明できるようにすることをゴールとして資料内容を作成することになりました。
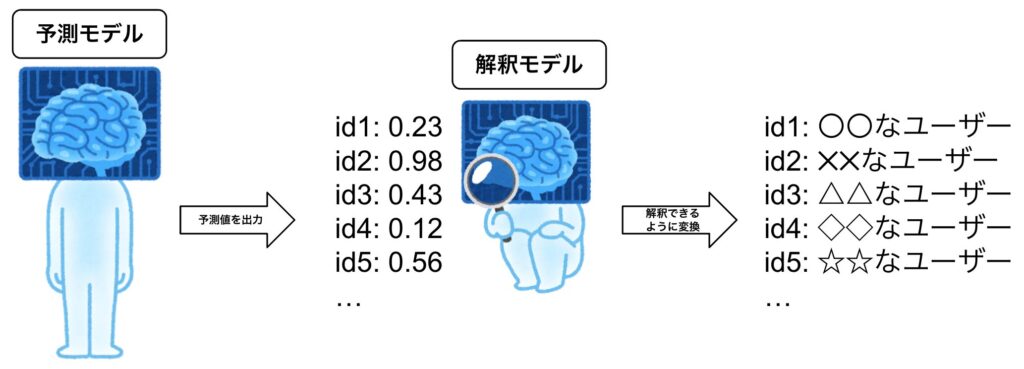
この資料を作るうえで最も大変だったのが、「AIセグメントはどんな性質があるのか」を説明する部分でした。これを解決するために「AIセグメントを作成する予測モデル」とは別の「AIセグメントを説明する解釈モデル」を作成し、そのモデルに説明内容を作らせるということをしました。
ここでの「AIセグメントの説明」とは、予測モデル自体やモデル内部の解釈を得るのではなく、モデルの出力に対する説明をすることが目的となります。AIセグメントは予測値によって決定されるため、モデル自体は間接的な関係性しかなく、直接的な関係にあるのはモデルが出力する予測値です。そのため、予測値に対する解釈を得ることがAIセグメントの説明をすることに繋がります。
どのような説明がよい説明になるのか?
作成する説明資料は、実際に営業メンバーがお客様に向けて話す社外に向けた資料になります。ここで、重要視したのは「納得度」と「意外性」の2つです。
今回説明したい「AIセグメントはどんな性質があるのか」をもう少し具体化すると、「AIセグメントにはどのようなユーザーが含まれているのか」に言い換えられます。いくら効果の良いセグメントができたとしても、予算を割いてもらうための説明が必要になります。「納得度」と「意外性」は、AIセグメントのユーザー性質が効果の良さに結びついているということを説明するために必要な要素でした。
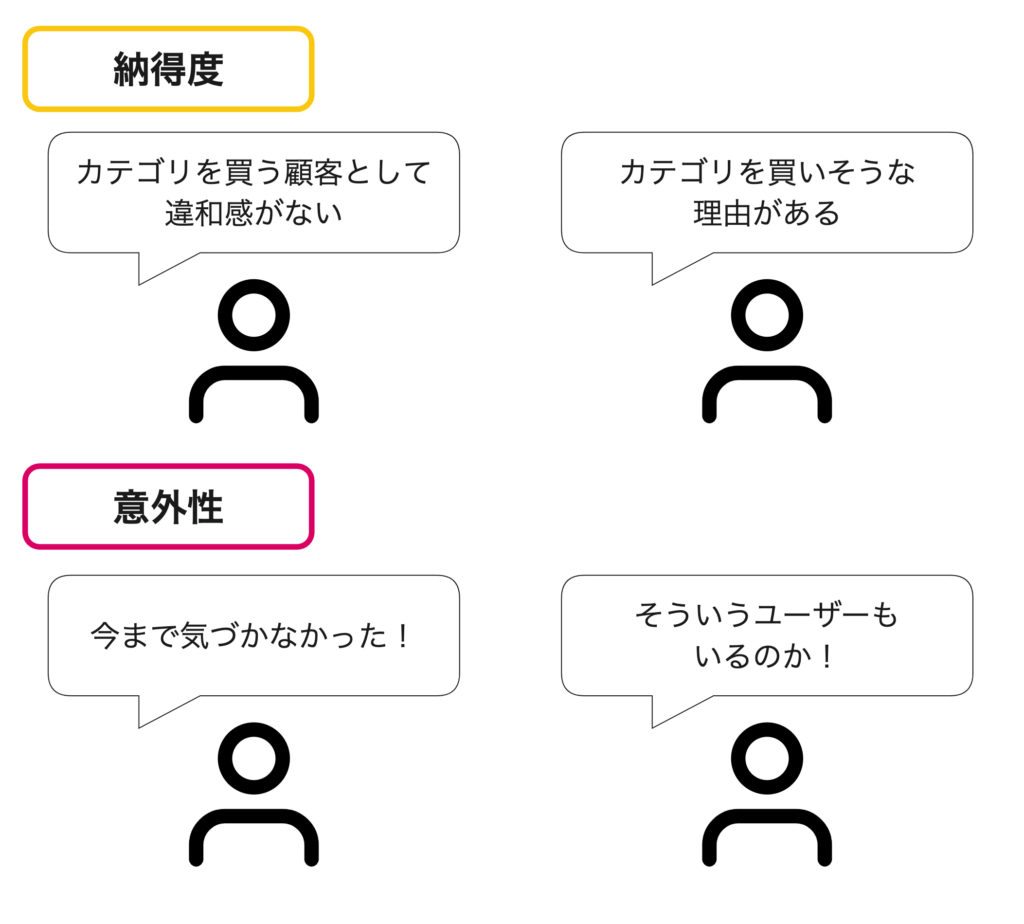
納得度については、何かの説明を受け入れてもらうために、説明の内容が信じられるもの、理解できるものにするためにはmustな条件だと思います。AIセグメントにおいては、「カテゴリ(例えばパソコンといった特定のカテゴリの商品)を購買しやすそうなユーザー集団」に納得度を持たせたいため、そこから乖離したような例はあまり出さないほうがいいと考えました。高額な商品カテゴリのAIセグメントに「10代のユーザー」を説明として出しても、高額な商品を購入できる10代が世の中には多くいないと考えられてしまい(そのようなユーザーはいるかも知れませんが)、納得はしにくいでしょう。その他にも、先ほど例に出したパソコンカテゴリのAIセグメントに「過去冷蔵庫を購入したユーザー」という説明を入れても、関係性がないためこれも納得しにくそうです。AIセグメントの納得度を高めるためにはカテゴリに含まれる商品を購入してもおかしくないかつ、関係性がわかりやすいといった内容にすることが求められます。
また意外性については、「AIセグメントをこれまでの人が作成するセグメントと差別化したい」というこちら側の目的を説明するために必要な要素でした。このAIセグメントには、セグメント作成を人から切り離し自動化させたいという目的もありました。そのため、人が作成するよりもAIで作成したほうがメリットが大きいことを伝えたく、そこで人が見つけられないような「カテゴリを購買しやすそうなユーザー」をAIはみつけられるという主張をしようと考えました。意外性とは、「あ、こういうユーザーも含まれるのか」という新しい発見ができるところに肝があります。
これらの「納得度」と「意外性」の2つを満たし、最終的にAIセグメントが効果の高いセグメントであることが納得できるようなものが「よい説明」であると考えました。次節では、実際に行った方法を述べていきます。
「よい説明」を回帰モデルで作成する
機械学習の解釈性の研究について人工知能学会のウェブサイトの記事で以下のようにまとめられています。
- 大域的な説明:複雑なブラックボックスモデルを可読性の高い解釈可能なモデルで表現することで説明とする方法。
- 局所的な説明:特定の入力に対するブラックボックスモデルの予測の根拠を提示することで説明とする方法。
- 説明可能なモデルの設計:そもそも最初から可読性の高い解釈可能なモデルを作ってしまう方法。
- 深層学習モデルの説明:深層学習モデル、特に画像認識モデルの説明法。アプローチとしては2の局所的な説明に該当。
AIセグメントの解釈は上記4つのうち「大域的な説明」に入ります。AIセグメントの解釈は機械学習モデルによって選択されたユーザーの中身を知ることが目的のため、ブラックボックスモデルのメカニズムを知ることよりも、ブラックボックスモデルの出力(予測値)を解釈可能にすることが重要です。
今回は大域的な説明で用いられるGlobal Surrogate Modelを採用しました。Interpretable Machine Learning[1]の「8.6 Global Surrogate」では以下のように説明されています。
A global surrogate model is an interpretable model that is trained to approximate the predictions of a black box model. We can draw conclusions about the black box model by interpreting the surrogate model. Solving machine learning interpretability by using more machine learning!
「ブラックボックスモデルの予測値を近似するように学習された解釈可能なモデル」という風に説明されており、解釈可能なモデルとは線形回帰モデルや決定木のことを指しています。以下、ブラックボックスモデルを「予測モデル」、解釈可能な(ブラックボックスモデルの解釈を可能にさせる)モデルを「解釈モデル」と呼ぶことにします。
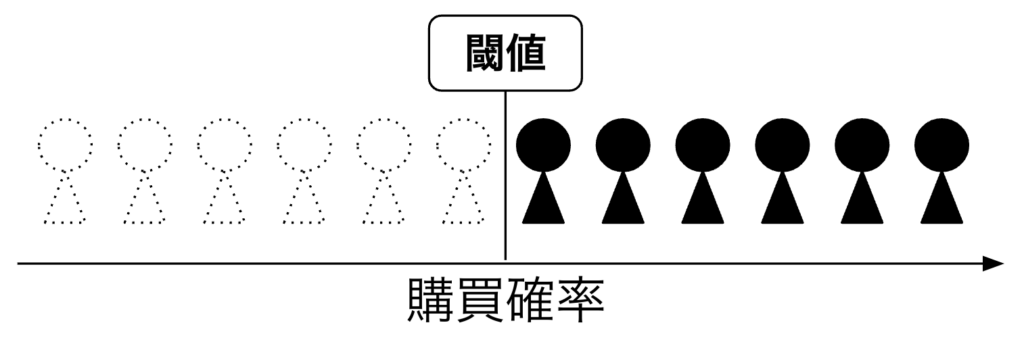
AIセグメントは予測モデルから出力される購買予測値が使われています。その中身自体はシンプルで、[0, 1]の予測値に閾値を設け、閾値を上回ったユーザーがAIセグメントということになります。
今回、解釈モデルとして線形回帰モデルを採用しました。線形回帰モデルは以下の式で表されます。
$$ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p + \epsilon $$
ここで:
- \(y\) は目的変数(従属変数)
- \(\beta_0\) は切片(モデルのy切片)
- \(x_1,x_2,…,x_p\) は説明変数
- \(\beta_1,\beta_2,…,\beta_p\) は各説明変数(独立変数)\(x_1,x_2,…,x_p\) に対応する回帰係数
- \(\epsilon\) は誤差項(誤差またはノイズ)
をそれぞれ表しています。
線形回帰モデルを用いることで、各説明変数の重要度をそれに対応する回帰係数で表すことができます。この特性から、回帰係数の絶対値が大きい説明変数が、モデルの出力に大きな影響を及ぼすと考えることができます。
AIセグメントは予測値が閾値を上回ったユーザーの集合のため、予測値を線形回帰モデルの目的変数にすることで解釈モデルを作成することができます。この解釈モデルが計算した回帰係数のうち、回帰係数の絶対値が大きいいくつかの説明変数を使ってAIセグメントを説明するようにしました。
予測モデルを解釈モデルで説明するメリット
Interpretable Machine Learningでは、Global Surrogate Modelのメリットについて以下のように書かれています。
The surrogate model method is flexible: Any model from the interpretable models chapter can be used. This also means that you can exchange not only the interpretable model, but also the underlying black box model. Suppose you create some complex model and explain it to different teams in your company. One team is familiar with linear models, the other team can understand decision trees. You can train two surrogate models (linear model and decision tree) for the original black box model and offer two kinds of explanations. If you find a better performing black box model, you do not have to change your method of interpretation, because you can use the same class of surrogate models.
解釈モデルには、線形回帰モデルでも決定木でもよいためチームの周りが理解しやすいモデルを柔軟に選べるという点と、ブラックボックスモデル側に変更があったとしてもフレームワークを変更せずに済むという点の2点について語られています。
また、「どのように説明するかを自由にできる」という点(Ribeiro, Singh, and Guestrin 2016[2])は今回において最大のメリットとなりました。結局のところ「どのように説明するか」は解釈モデルの説明変数によって決定されます。そして、この説明変数はあらゆる変数を取れます。つまり、「納得度」と「意外性」を満たす説明変数を作成することで「よい説明」をいくつも作り上げることができるということです。
説明変数になにを選ぶか次第で、納得度と意外性の2つの質が大きく変わります。人が直感的にわかるような変数を選んでしまえば納得度は得られますが意外性が失われ、本来欲しい情報が得られなくなってしまいます。逆に、意外性ばかり突き詰めると納得度が失われてしまいます。
今回の分析ではこの説明変数の作成に労力を最もかけました。以下は今回使用した説明変数の例です。
- 性別
- 年齢
- 過去の購買
- カテゴリ
- 金額帯
- 新品 or 型落ち
- etc…
これらの変数を様々に組み合わせ、回帰分析し、また組み合わせ、回帰分析…のように解釈として納得度と意外性を持たせられるような変数選択を探索的に行い、最終的に3パターンの説明変数セットに絞りました。
なぜ複数パターンを用意したかと言うと、解釈の説明をするにあたって実際にどの説明がどのようなお客様に刺さるかは不明瞭だったためです。そのため、3つのパターンから選べるようにすることで営業メンバーが喋りやすいように工夫しました。このパターンから選ぶ方法は営業メンバーからも好評で、実際の提案資料にも組み込んでいただけています。
予測モデルと解釈モデルを分け、説明変数を柔軟に選択できるようしたことで解釈の説明に幅をもたせられるようになりました。説明のための要素を自由に選択できることと、複数のパターンを用意できる点は、機械学習が介在するなかで納得度と意外性を持たせるために最も重要な機構だと思います。
おわりに
今回、重要視した要件であった「納得度」と「意外性」を担保するために、予測モデルと解釈モデルを分けることでそれを実現しました。これにより、解釈用の説明変数を自由に操れるようになり、人の意思をモデルへと反映させることができました。
1年目の仕事で「データサイエンスをビジネス転用する」といったことを経験できたことは自分にとって大きな価値となりました。これからのキャリアでこのような仕事をいくつもこなせるようにこれからも頑張っていこうと思います。
また、新しい領域にチャレンジしたいと考えている方や、機械学習をビジネスモデルに直接反映させたいと考えている方はぜひお話しましょう!以下のカジュアル面談のページや、私のX(@ zippowriter_)のDM等でお気軽にお声掛けください!
■ チームメンバーの他のブログ記事はこちら